
Nginx监控运维示例
前言
Nginx 特性
相比 Apache 服务器,Nginx 因其采用的异步非阻塞工作模型,使其具备高并发、低资源消耗的特性,高度模块化设计使 Nginx 具备很好的扩展性;在处理静态文件、反向代理请求等方面,Nginx 表现出很大的优势。
Nginx 常见的使用方式
Nginx 可以作为反向代理服务器来转发用户请求;并能够在处理请求的过程中实现后端实例负载均衡,实现分发请求的功能;也可将 Nginx 配置为本地静态服务器,处理静态请求。
一、监控指标梳理
Nginx 处理请求的全过程应被监控起来,以便我们及时发现服务是否能够正常运转。
Nginx 处理请求的过程被详细地记录在 access.log 以及 error.log 文件中,我们给出以下(表 1)需要监控的关键指标:
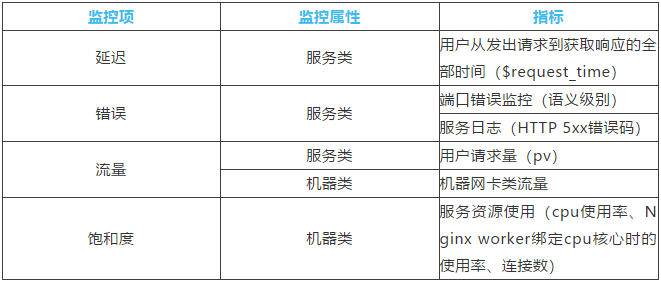
表1:关键指标
二、监控实践
下面从延迟、错误、流量以及饱和度四个指标对 Nginx 监控实践进行说明。
2.1 延迟监控
延迟监控主要关注对 $request_time 的监控,并绘制 TP 指标图,来确认 TP99 指标值。
另外,我们还可以增加对 $upstream_response_time 指标的监控,来辅助定位延迟问题的原因。
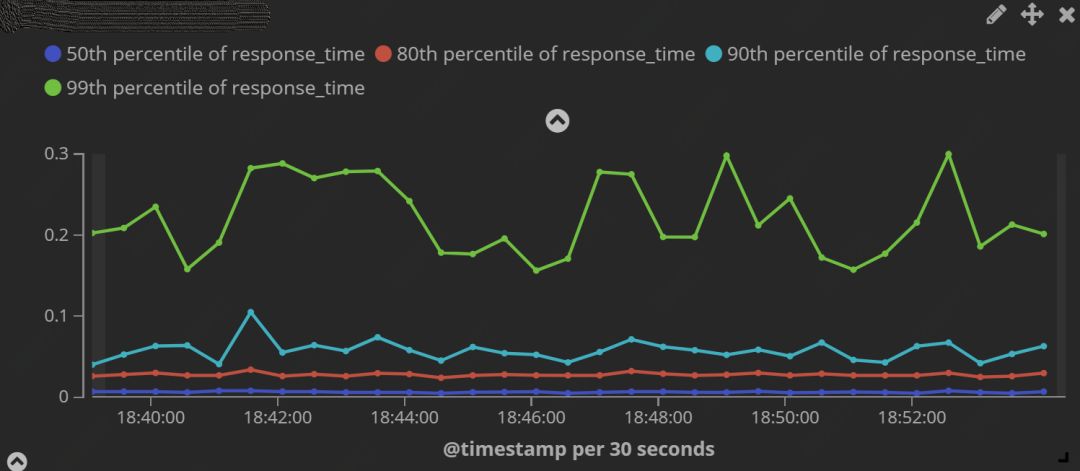
图 1:TP 指标
图 1 展示了过去 15min 内 Nginx 处理用户请求的时间,可以看出用户 90% 的请求可以在 0.1s 内处理完成,99% 的请求可以在 0.3s 内完成。
根据 TP 指标值,并结合具体业务对延迟的容忍度,来设置延迟的报警阈值。
2.2 错误监控
Nginx 作为 Web 服务器,不但要对 Nginx 本身运行状态进行监控,还必须对 Nginx 的各类错误响应进行监控,HTTP 错误状态码以及 error.log 中记录的错误详细日志都应被监控起来以协助解决问题。
2.2.1 基于 HTTP 语义的 Nginx 端口监控
单纯的 Nginx 端口监控无法反映服务真实运行状态,我们要关注的是 Nginx 本身存活以及是否可以正常提供服务。
基于我们的实践,我们推荐用语义监控代替端口监控,即从 Nginx 本机以 http://local_ip:port/ 的方式进行访问,校验返回的数据格式、内容及 HTTP 状态码是否符合预期。
2.2.2 错误码监控
必须添加对诸如 500/502/504 等 5xx 服务类错误状态码的监控,它们告诉我们服务本身出现了问题。
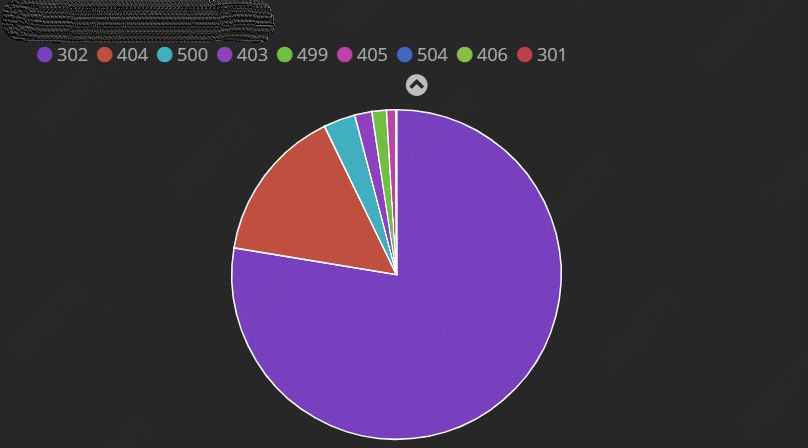
图 2:状态码监控
5xx 类错误每分钟出现的频率应该在个位数,太多的 5xx 应及时排查问题并解决;4xx 类错误,在协助解决一些非预期的权限错误、资源丢失或性能等问题上可以给予帮助。
可以选择性得对 301/302 重定向类监控,应对特殊配置跳转的监控,如后端服务器返回 5xx 后,Nginx 配置重定向跳转并返回跳转后的请求结果。
2.2.3 对错误日志监控
Nginx 内部实现了对请求处理错误的详细记录,并保存在 error.log 文件中。
错误类型有很多种,我们主要针对关键的、能体现服务端异常的错误进行采集并监控,以协助我们进行故障定位:
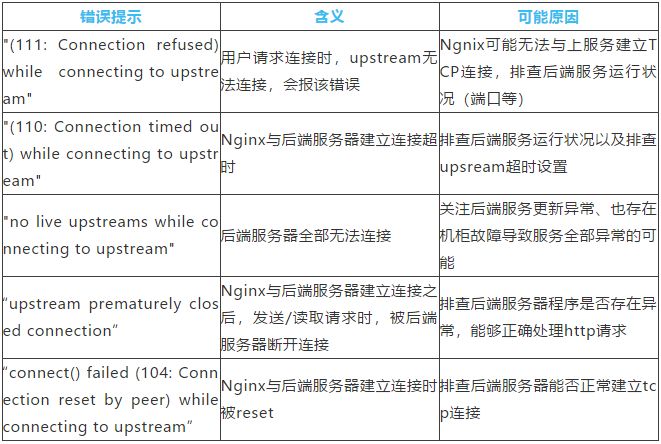
表 2:错误日志信息
2.3 流量监控
2.3.1 Nginx 所接受请求总量的监控
关注流量波动周期,并捕获流量突增、突降的情况;通常稳态下流量低峰和高峰浮动 20% 需要关注下原因。
对于有明显波动周期的服务,我们也可以采用同环比增涨/降低的告警策略,来及时发现流量的变化。
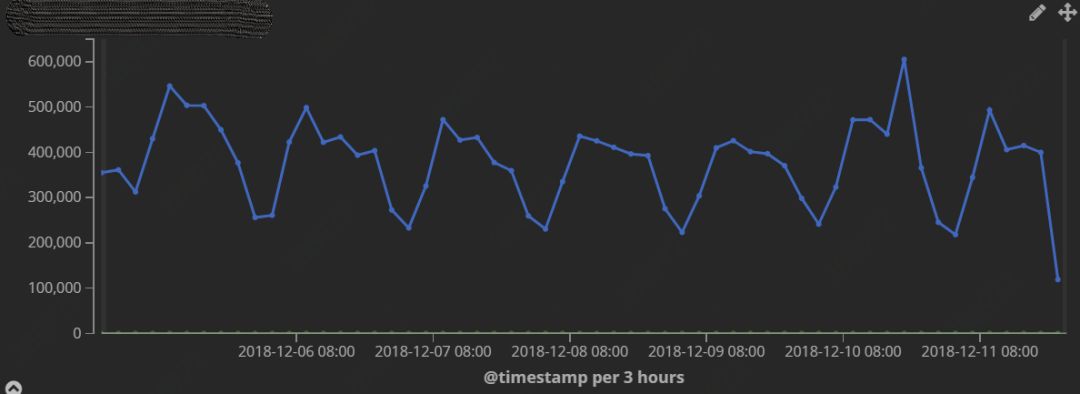
图 3:PV 流量图
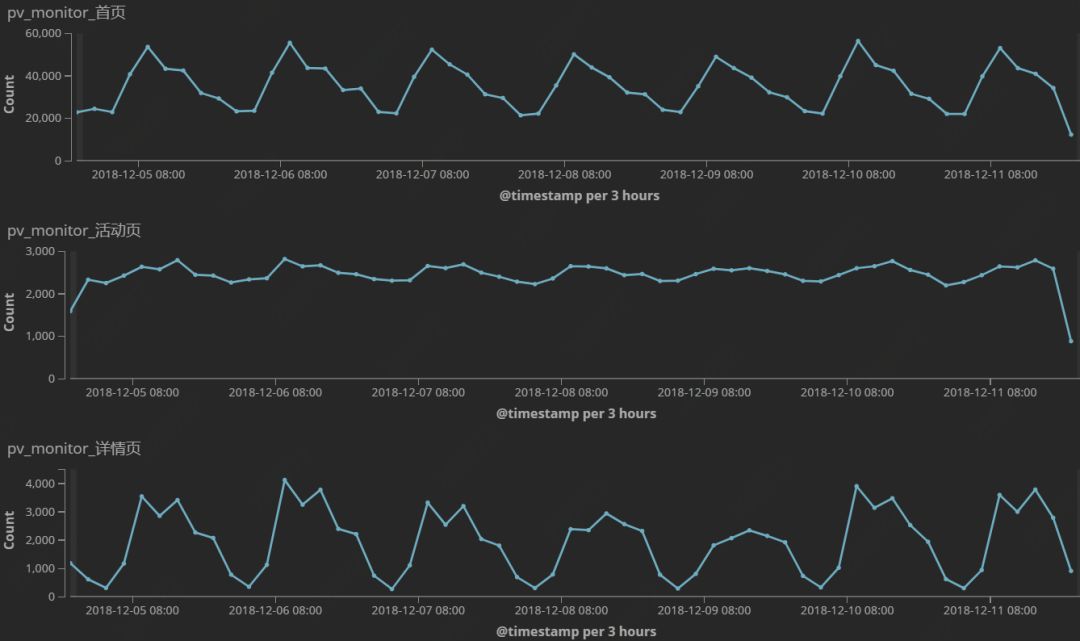
图 4:关键流量图
图 3 为京东云某平台一周内的流量波动图,流量存在明显低峰和高峰并有天级别的周期性。
基于网站运行特性,根据低峰、高峰的值来监控网站流量的波动,并通过自身的监控仪表盘配置网站关键页面的流量图(图 4),以协助故障排查。
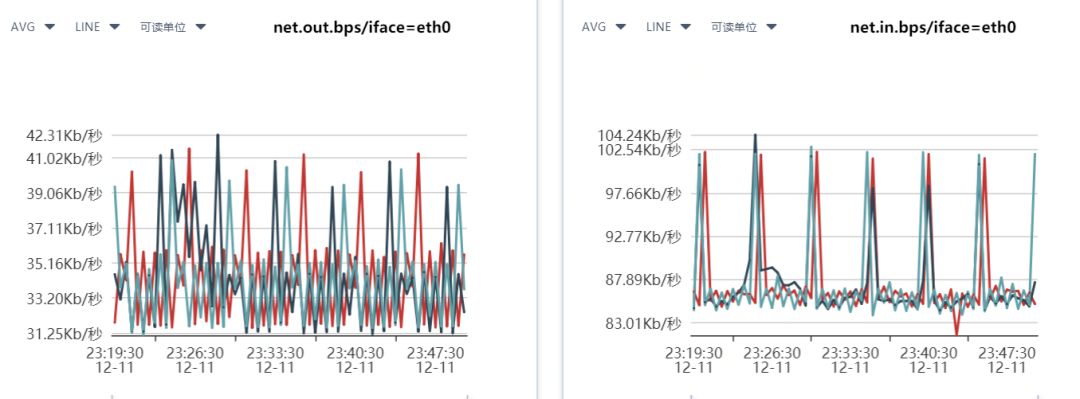
图 5:网卡流量图
2.3.1 对网卡 IO 等机器级别流量进行监控
可以及时发现服务器硬件负载的压力,当 Nginx 被用于搭建文件服务器时,此监控指标需要我们尤为关注。
2.4 饱和度监控
Google SRE 中提到,饱和度应关注服务对资源的利用率以及服务在当前运行情况下还可以承受多少负载。
Nginx 是低资源消耗的高性能服务器,但诸如在电商场景下,新产品抢购会在短时间内造成 CPU 利用率、请求连接数、磁盘写入的飙升。
CPU 利用率还要考虑通过 worker_cpu_affinity 绑定 Worker 进程到特定 CPU 核心的使用情况,处理高流量时,该配置可以减少 CPU 切换的性能损耗。
Nginx 可以接受的最大连接数在配置文件 nginx.conf 中由 worker_processes 和 worker_connections 两个参数的乘积决定。

通过 Nginx 自带的模块 http_stub_status_module 可以对 Nginx 的实时运行信息(图 6)进行监控。
因我们更关心当前 Nginx 运行情况,不对已处理的请求做过多关注,所以我们只对如下指标进行采集监控:

表 3:指标含义
三、基于开源软件搭建 Nginx 可视化监控系统
3.1 采用 Elasticsearch+Logstash+Kibana 搭建可视化日志监控
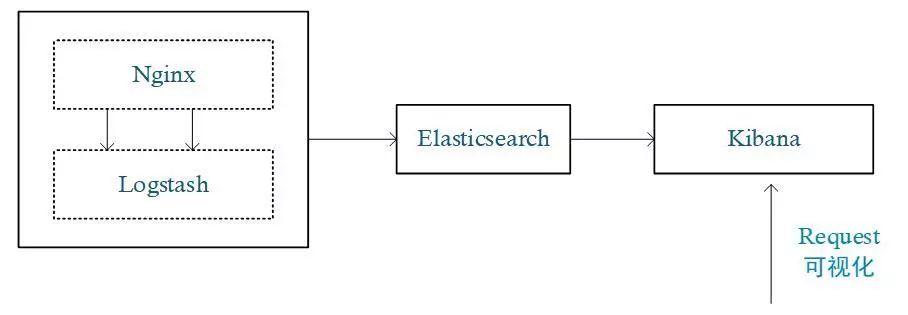
图 7:ELK 栈架构图
针对以上四个监控黄金指标,搭建的 ELK 栈仪表盘,设置常用的 Nginx 日志过滤规则(图 8),以便可以快速定位分析问题。
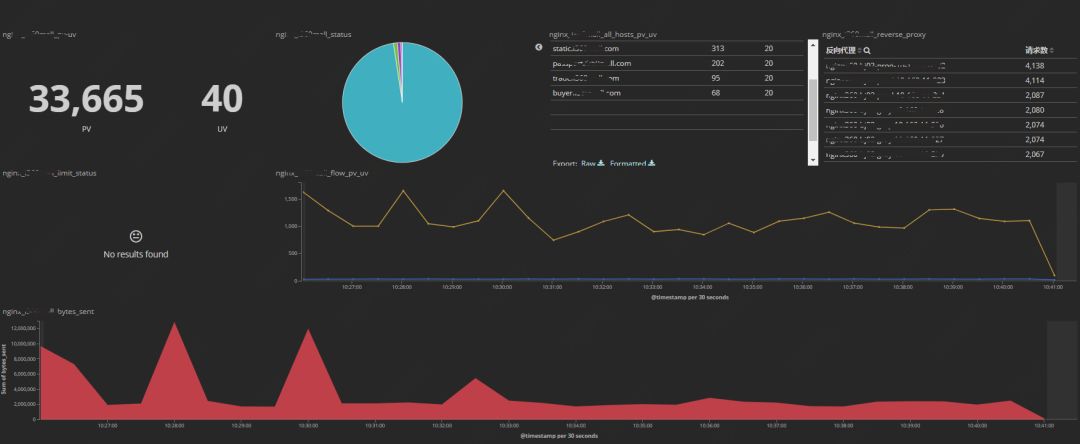
图 8:ELK 仪表盘
3.2 采用 Kibana+Elasticsearch+Rsyslog+Grafana 搭建可视化日志监控
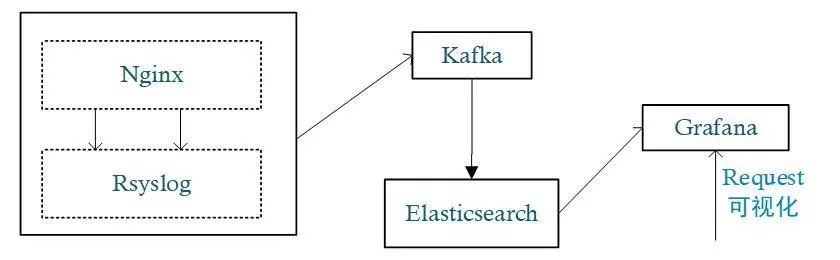
图 9:Grafana 可视化架构图
相较于 Kibana 能快速地对日志进行检索,Grafana 则在数据展示方面体现了更多的灵活性,某些情况下二者可以形成互补。
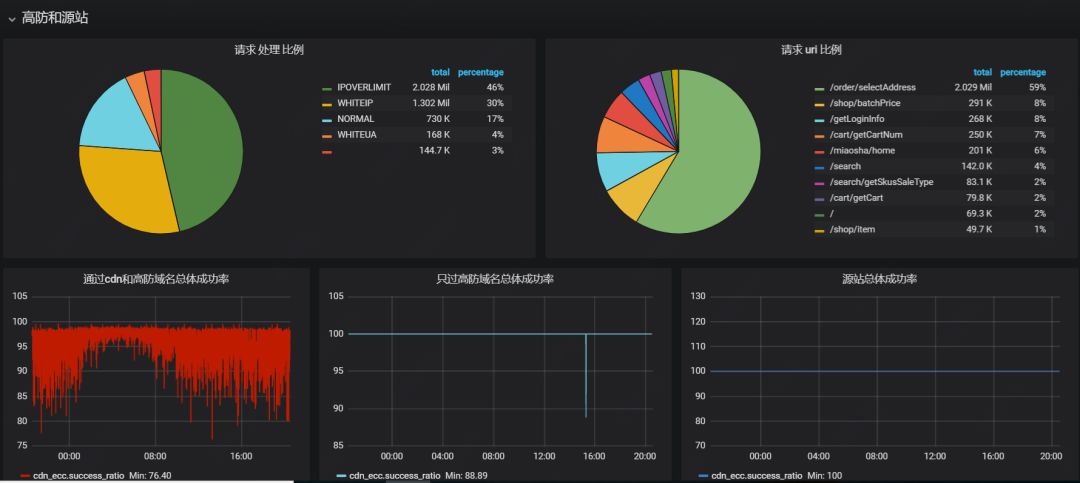
图 10:Grafana 仪表盘
我们在实践中实现上述两种架构的 Nginx 日志可视化监控;从需求本身来讲,ELK 栈模型可以提供实时的日志检索,各种日志规则的过滤和数据展示,基本可以满足 Nginx 日志监控的需求。
Grafana 架构模型无法进行日志检索和浏览,但提供了角色权限的功能,来防护一些敏感数据的访问。
另外,Grafana 更为丰富的图表类型和数据源支持,使其具有更多的应用场景。
基于 Nginx 监控发现并定位问题案例
3.3 案例 1:大流量冲击
**问题:**某平台,进行了一次新产品的抢购活动。活动期间因流量飙升导致商品详情页、下单等核心功能处理耗时增加的情况。
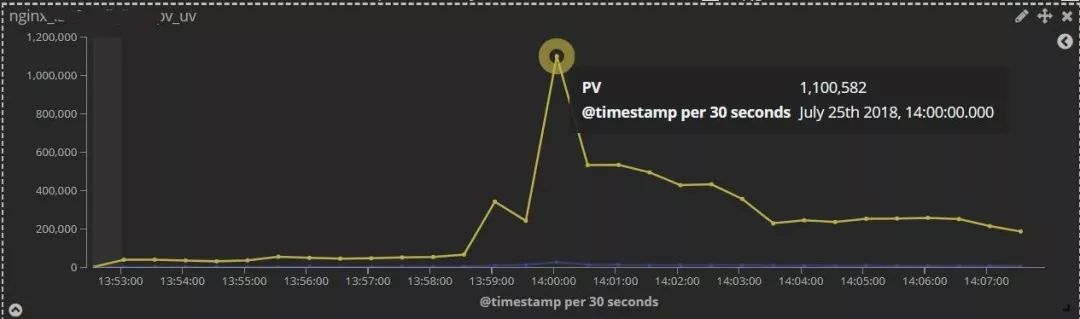
图 11:PV 飙升图
**解决:**订单监控及 Nginx 的 PV、请求时间等监控指标发出报警后,运维人员迅速通过自建的 ELK 监控仪表盘,关注网站流量变化,查看用户请求 top IP、top URL;发现存在大量黄牛的恶意抢购行为,导致服务后端处理延时。
因此,我们通过降低高防产品、Nginx 限流配置中相关接口防攻击阈值,及时拦截了对系统负载造成压力的刷单行为,保障了新品促销活动顺利开展。
3.4 案例 2:Nginx 错误状态码警示服务异常
**问题:**某平台进行后端服务器调整,某个 Nginx 的 upstream 指向的后端服务器配置错误,指向了一个非预期的后端服务。
当错误的配置被发布到线上后,网站开始出现概率性的异常,并伴有 500 和 302 错误状态码数量的飙升。
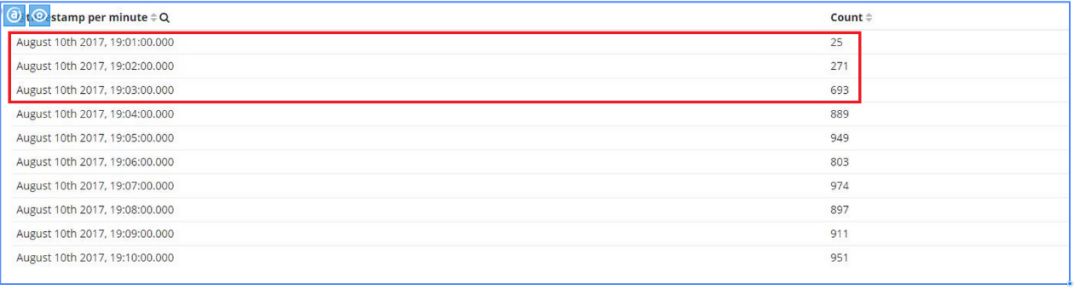
图 12:302 错误码统计
**解决:**Nginx 错误状态码告警后,通过 ELK 平台过滤 302 错误码下用户请求的 URL,发现请求错误的 URL 均与后端的某个模块相关,该请求都被重定向到了网站首页。
进一步定位发现,某台 Nginx 指向了错误的后端服务器,导致服务器返回大量 500 错误,但因 Nginx 配置中对 500 错误做了重定向,并因此产生了很多 302 状态码。
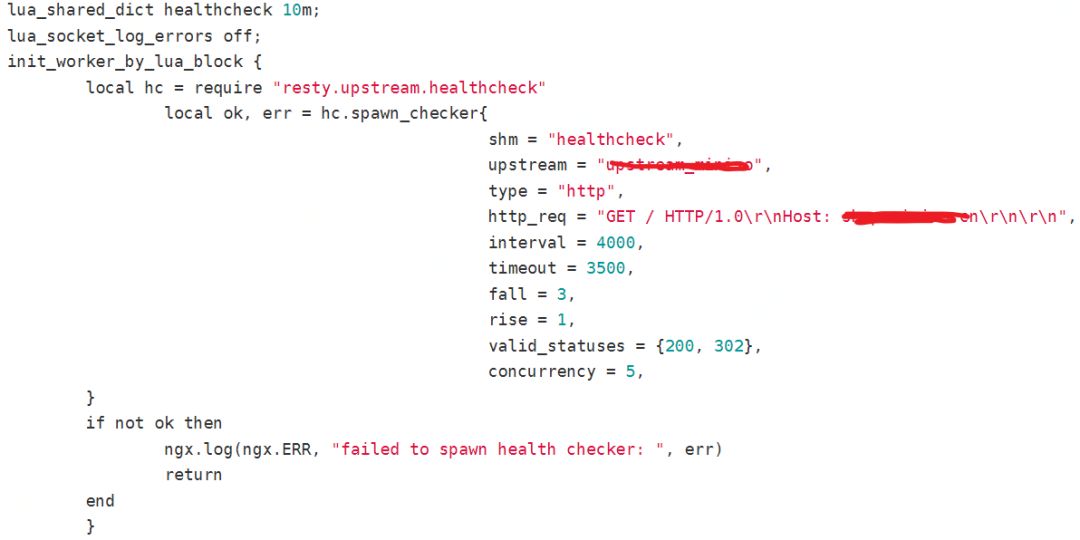
图 13:配置 upstream 健康监测
在后续改进中,我们通过升级 Nginx,采用 openresty+lua 方式来对后端服务器进行健康监测(图 13),以动态更新 upstream 中的 server,可以快速摘除异常的后端服务器,达到快速止损的目的。
3.5 案例 3:Nginx 服务器磁盘空间耗尽导致服务异常
**问题:**Nginx 作为图片服务器前端,某天其中一实例在生产环境无任何变更的情况下收到报警提示:500 状态码在整体流量中占比过高。
**解决:**快速将此机器从生产环境中摘除,不再提供服务,经排查 Nginx 错误日志发现如下报错:
open() "/home/work/upload/client_body_temp/0000030704"failed ( 28: No spaceleftondevice)
Nginx 处理请求时,会将客户端 POST 长度超过 client_body_buffer_size 请求的部分或者全部内容暂存到 client_body_temp_path 目录,当磁盘空间被占满时,产生了以上的报错。
最终,我们确认了本次异常是产品升级后支持上传的图片大小由 15MB 改为 50MB,并且运营方进行了新产品推广活动,用户上传图片量激增快速打满磁盘空间所致。

