
Python学习笔记--------进程和线程
进程和线程
1、进程和线程的概念
进程
是正在执行的程序,是多任务操作系统中执行任务的基本单元,是包含了程序指令和相关资源的集合,是程序执行时的一个实例,在程序运行时创建的。
线程
线程是进程的执行单元。在大多数程序中,可能只有一个主线程,但是为了提高效率,有些程序会采用多线程,在系统中所有线程看起来都是同时执行的。
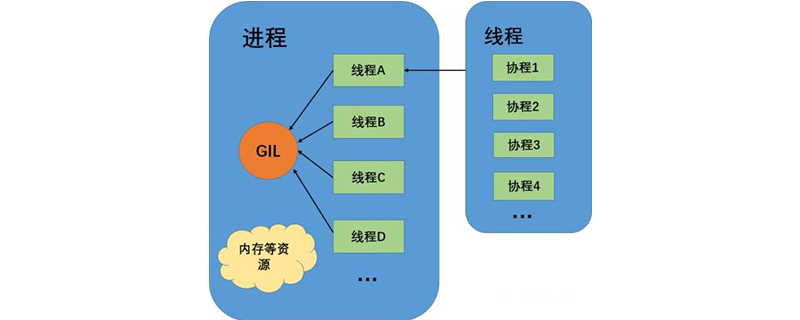
线程和进程的对比
进程是重量级的,具体包括进程映像的结构,执行细节以及进程间切换的方法。在进程中,需要处理的问题包括进程间通信,临界区管理和进程调度等,这些特性使得生成一个进程的开销是比较大的。
线程是轻便的,线程之间共享很多资源,容易进行通信,生成一个线程的开销很小,但是线程会出现死锁,数据同步和实现复杂的问题
并发编程解决方案
-
启动多个进程,每个进程只有一个线程,但多个进程可以一块执行多个任务
-
启动一个进程,在一个进程中启动多个线程,这样,多个线程也可以一起执行多个任务
-
启动多个进程,每个进程再启动多个线程,这样执行的任务更多,但是这种方法更加复杂,很少采用
python在多进程处理CPU密集型程序(各种循环处理,计数等等)比较友好,在多线程处理IO密集型代码(文件处理,网络爬虫等)比较友好
2、进程的开发
python标准库中相关模块
| 模块 | 介绍 |
|---|---|
| subprocess | python基本库中多线程编程相关模块,适用于外部进程交互,调用外部进程 |
| multiprocessing | 核心机制是fork,重开一个进程,首先会把父进程的代码copy重载一遍 |
| threading | python基本库多线程管理相关模块 |
subprocess模块
run 方法
subprocess.run(args, *, stdin=None, input=None, stdout=None, stderr=None, capture_output=False, shell=False, cwd=None, timeout=None, check=False, encoding=None, errors=None, text=None, env=None, universal_newlines=None)
- args:表示要执行的命令。必须是一个字符串,字符串参数列表。
- stdin、stdout 和 stderr:子进程的标准输入、输出和错误。其值可以是 subprocess.PIPE、subprocess.DEVNULL、一个已经存在的文件描述符、已经打开的文件对象或者 None。subprocess.PIPE 表示为子进程创建新的管道。subprocess.DEVNULL 表示使用 os.devnull。默认使用的是None,表示什么都不做。另外,stderr 可以合并到 stdout 里一起输出。
- timeout:设置命令超时时间。如果命令执行时间超时,子进程将被杀死,并弹出 TimeoutExpired 异常。
- check:如果该参数设置为 True,并且进程退出状态码不是 0,则弹 出 CalledProcessError 异常。
- encoding: 如果指定了该参数,则 stdin、stdout 和 stderr 可以接收字符串数据,并以该编码方式编码。否则只接收 bytes 类型的数据。
- shell:如果该参数为 True,将通过操作系统的 shell 执行指定的命令。
import subprocess # 调用外部命令(如window的dir,ipconfig,linux等命令等) runcmd=subprocess.run('dir D:',encoding='utf-8',shell=True) # 显示d盘下所有的目录 print(runcmd)
run方法可用文件句柄形式传参
import subprocess f=open(r'd:\\sxt2.txt','w+') run_cmd=subprocess.run('python',stdin=f,stdout=subprocess.PIPE,shell=True) #调用python程序命令 run_cmd.stdin='print("你好")' f.write(run_cmd.stdin) f.close() print(run_cmd.stdout.decode('utf-8'))
优点:可以通过执行python程序,对stdin传参,通过stdout输出
缺点:需要提前指定文件,并不方便,对进程的使用并不友好
Popen 方法
class(类) subprocess.Popen(args, bufsize=-1, executable=None, stdin=None, stdout=None, stderr=None, preexec_fn=None, close_fds=True, shell=False, cwd=None, env=None, universal_newlines=False, startupinfo=None, creationflags=0,restore_signals=True,start_new_session=False, pass_fds=(),*, encoding=None, errors=None)
常用参数
- args:shell命令,可以是字符串或者序列类型,调用的程序(如:list,元组)
- bufsize:缓冲区大小。当创建标准流的管道对象时使用,默认-1。
0:不使用缓冲区
1:表示行缓冲,仅当universal_newlines=True时可用,也就是文本模式
正数:表示缓冲区大小
负数:表示使用系统默认的缓冲区大小。 - stdin, stdout, stderr:分别表示程序的标准输入、输出、错误句柄
- shell:如果该参数为 True,将通过操作系统的 shell 执行指定的命令。
import subprocess popen=subprocess.Popen('python',stdin=subprocess.PIPE,stdout=subprocess.PIPE,shell=True) # 调用python这个程序命令,从标准输入里面写入,在标准输出输出 popen.stdin.write('print("hello")\n'.encode('utf-8')) popen.stdin.write('import math\n'.encode('utf-8')) popen.stdin.write("print(math.sqrt(4))\n".encode('utf-8')) popen.stdin.close() result=popen.stdout.read().decode('utf-8') popen.stdout.close() print(result)
Popen 对象方法
poll(): 检查进程是否终止,如果终止返回 returncode,否则返回 None。wait(timeout):等待子进程终止,设定timeout,超过这个时间就自动结束。communicate(input,timeout): 和子进程交互,发送和读取数据。terminate(): 停止子进程,也就是发送SIGTERM信号到子进程。kill(): 杀死子进程。发送 SIGKILL 信号到子进程
multprocessing模块
class(类) multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, daemon=None)
常用参数
-
group:一般都为None
-
target:run()方法调用的函数
-
name:表示进程调用的名字
-
args:表示目标调用的元组
-
kwargs:表示目标调用的字典
-
daemon:表示守护线程,当父进程结束后,子进程会强制结束
常用方法
run():表示进程活动的方法。你可以在子类中重载此方法。标准 run方法用传递给对象构造函数的可调用对象作为目标参数(如果有),分别从 args 和 kwargs 参数中获取顺序和关键字参数。start():启动进程活动。这个方法每个进程对象最多只能调用一次。它会将对象的 放法安排在一个单独的进程中调用。join([timeout])如果可选参数 timeout 是 None (默认值),则该方法将阻塞,直到调用 join方法的进程终止。如果 timeout 是一个正数,它最多会阻塞 timeout 秒。请注意,如果进程终止或方法超时,则该方法返回None。检查进程的 exitcode 方法的进程终止。如果 timeout 是一个正数,它最多会阻塞 timeout 秒。请注意,如果进程终止或方法超时,则该方法返回None。close()关闭Process对象,释放与之关联的所有资源。
创建子进程(函数)
import multiprocessing import os import time def fun(name): print("该进程的序号",name) print("父进程的id",os.getpid())# getpid获取当前进程的id地址 print("子进程的id",os.getpid()) print() time.sleep(3) # 停格三秒 if __name__ == '__main__': # 创建多个子进程来调用函数 start=time.time() for i in range(10): p=multiprocessing.Process(target=fun,args=('进程%d'%i,)) # 创建一个子进程 p.start() # 开启一个子进程 print("进程完成") # 进程之间并不会出现堵塞的现象,父进程会跟着子进程所有的代码结束才会完全停止 end=time.time() print(end-start) # 计算整个程序的时间
创建子进程(类)
#封装一个进程类 from multiprocessing import Process import os import time #自定义一个进程类 class MyProcess(Process): # Process 是父进程,重载Process类 def __init__(self,xname): Process.__init__(self) #加载父类给我们提供的功能 self.name = xname def run(self): #子进程在运行过程中执行的代码 print('当前进程的ID', os.getpid()) # getpid获取当前调用函数的进程的id print("父进程的ID", os.getppid()) # getppid获取当前进程的父进程ID print('当前进程的名字', self.name) time.sleep(2) # 该线程的运行时间推迟到两秒 if __name__ == '__main__': # 开始的时间戳 start = time.time() #创建10个子进程放入一个列表中 list = [] for i in range(10): p = MyProcess('process-%d'%(i+1)) # 创建我们自定义的进程类 p.start() #开始子进程 list.append(p) for p in list: p.join() # 我们一般都会父进程等待所有子进程结束,才执行后面的代码,join()等待当前子进程结束 # 所有子进程已经结束 r = time.time() - start print('十个子进程一共执行的时间是',r) # 整个线程所需要的时间两秒左右
queue实现多个进程间通信
queue实现多个进程之间的通信,就是使用了操作系统给开辟的一个队列空间,各个进程可以把数据放在该队列中,当然也可以从队列中把自己需要的消息取走。
from multiprocessing import Queue,Process import os,time #定义一个传入的类 class send(Process): def __init__(self,name,queue): Process.__init__(self) self.name=name self.queue=queue def run(self): print("父进程的id开启!",os.getpid()) for i in range(5): self.queue.put(i) time.sleep(1) print("父进程为id的程序结束",os.getpid()) #定义一个传出的类 class recieve(Process): def __init__(self,name,queue): Process.__init__(self) self.name=name self.queue=queue def run(self): print("子进程的id开始",os.getpid()) while True: t=self.queue.get(True) print(t) if __name__ == '__main__': q=Queue() #创建两个进程的通讯 qs=send('write',q) qr=recieve('recieve',q) #开启两个进程 qs.start() qr.start() #等子程序结束后,父程序才结束 qs.join() #因为收到的程序无法停止,所以父程序没法停止,所以需要设定一个强制停止的设置 qr.terminate() print("程序结束")
Pipe实现两个进程间通信
返回的两个连接对象 Pipe() 表示管道的两端。每个连接对象都有 send() 和 recv() 方法(相互之间的)。请注意,如果两个进程(或线程)同时尝试读取或写入管道的 同一 端,则管道中的数据可能会损坏。当然,在不同进程中同时使用管道的不同端的情况下不存在损坏的风险。
from multiprocessing import Pipe,Process import os,time #定义一个传入的类 class send(Process): def __init__(self,name,pipe): Process.__init__(self) self.name=name self.pipe=pipe def run(self): print("父进程的id开启!",os.getpid()) for i in range(5): self.pipe.send(i) time.sleep(1) print("父进程为id的程序结束",os.getpid()) #定义一个传出的类 class recieve(Process): def __init__(self,name,pipe): Process.__init__(self) self.name=name self.pipe=pipe def run(self): print("子进程的id开始",os.getpid()) while True: t=self.pipe.recv() print(t) if __name__ == '__main__': start=time.time() q1,q2=Pipe() #创建两个进程的通讯 qs=send('write',q1) qr=recieve('recieve',q2) #开启两个进程 qs.start() qr.start() #等子程序结束后,父程序才结束 qs.join() end=time.time() #因为收到的程序无法停止,所以父程序没法停止,所以需要设定一个强制停止的设置 qr.terminate() print("程序结束,所需的时间是%f"%(end-start))
进程间同步(数据同步)
multiprocessing包含来自 threading的所有同步原语的等价物。例如,可以使用锁来确保一次只有一个进程打印到标准输出。可以用同步锁的形式将数据进行限制,不会导致数据的输出错误,加了锁程序就变为串行执行,并不是并行执行。
*multiprocessing.Value(typecode_or_type, args[, lock])参数使用
typecode_or_type:一般是cpython结构,借鉴python的struct参数args:传递给typecode_or_type类型的参数
import multiprocessing as mp from multiprocessing import Lock import time def job(v, num,l): #加锁 with l: for _ in range(10): time.sleep(0.1) v.value += num print(v.value) def multicore(): l=Lock() # 将数据放在共享内存映射中 v = mp.Value('i', 0) #先进行p1进程,因为加了锁,所以两个不会因为抢资源而造成数据错误 p1 = mp.Process(target=job, args=(v, 1,l)) #p1进程结束后,在进行p2进程 p2 = mp.Process(target=job, args=(v, 3,l)) p1.start() p2.start() p1.join() p2.join() if __name__ == '__main__': multicore()
进程池
Pool类可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就会创建一个新的进程来执行请求。如果池满,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求。
函数使用
- apply_async(func[, args[, kwds[, callback]]]) 它是非阻塞,apply(func[, args[, kwds]])是阻塞的。
- close() 关闭pool,使其不在接受新的任务。
- terminate() 结束工作进程,不在处理未完成的任务。
- join() 主进程阻塞,等待子进程的退出, join方法要在close或terminate之后使用。
from multiprocessing.pool import Pool import os,time,random def run(name): start=time.time() print('进程id已经开启',os.getpid()) time.sleep(random.choice([1,2,3,4,5])) end=time.time() print("进程id为%d结束!花费的时间%.3f"%(os.getpid(),end-start)) if __name__ == '__main__': p=Pool(5) for i in range(10): #用异步进行进程调用run函数(不会出现堵塞现象) p.apply_async(run,args=('progress-%d'%i,)) p.close() p.join() print("父进程结束")
3、线程的开发
threading模块
threading.Thread(self, group=None, target=None, name=None,agrs=(),kwargs=None, *, daemon=None)
常用参数
-
group:是预留的,用于将来扩展 -
target:是一个可调用对象,在线程启动后执行 -
name:是线程的名字。默认值为“Thread-N“,N是一个数字 -
args和kwargs:分别表示调用target时的参数列表和关键字参数

import threading,time class Mthread(threading.Thread): def run(self): for i in range(3): print("第%d个进程为%s的程序已经启动!\n"%((i+1),self.name)) time.sleep(1) print("第%d个进程为%s结束"%((i+1),self.name)) if __name__ == '__main__': s='abcdef' list=[] start=time.time() for i in range(5): t=Mthread(name=s[i]) t.start() list.append(t) # 父进程等待子进程全部结束或者超时 for j in list: j.join() end=time.time() print("程序结束,花费的时间是%f"%(end-start))
数据的私有变量
使用 local() 函数创建的变量,可以被各个线程调用,但和公共资源不同,各个线程在使用 local() 函数创建的变量时,都会在该线程自己的内存空间中拷贝一份。这意味着,local() 函数创建的变量看似全局变量(可以被各个线程调用),但各线程调用的都是该变量的副本(各调用各的,之间并无关系)。
import threading # 创建全局ThreadLocal对象: local = threading.local() def process(): # 3.获取当前线程关联的resource: res = local.resource print (res + "http://c.biancheng.net/python/") def process_thread(res): # 1.为当前线程绑定ThreadLocal的resource: local.resource = res # 2.线程的调用函数不需要传递res了,可以通过全局变量local访问 process() t1 = threading.Thread(target=process_thread, args=('t1线程',)) t2 = threading.Thread(target=process_thread, args=('t2线程',)) t1.start() t2.start()
数据共享(全局变量)
因为线程之间是可以相互联通的,在线程之间的公共资源会处于共享的状态,此时就需要设置全局变量来实现数据共享
from threading import Thread import time #定义一个全局变量 g_num=0 def run1(): global g_num for i in range(10): g_num+=1 print('线程1,执行后的结果是%d'%g_num) def run2(): global g_num print('线程2,执行后的结果是%d'%g_num) if __name__ == '__main__': t1=Thread(target=run1) t2=Thread(target=run2) t1.start() time.sleep(1)#延迟时间,让线程1的所有操作完成 t2.start() print('主线程结束,全局变量的值是%d'%g_num) #方法2 def run3(num): num[0]=0 #变量为了多个线程可以共享,我们必须选择可变的数据类型 for i in range(15): num[0]+=1 print('线程3,执行后的结果是%d'%num[0]) def run4(num): print('线程4,执行后的结果是%d'%num[0]) if __name__ == '__main__': i=[0] t1=Thread(target=run3,args=(i,)) t2=Thread(target=run4,args=(i,)) t1.start() time.sleep(1)#延迟时间,让线程1的所有操作完成 t2.start() print('主线程结束,全局变量的值是%s'%i) #在一个进程内所有的线程共享全局变量,能够在不使用其他方式的前提下完成多线程之间的数据共享 #缺点,线程是对全局变量随意纂改可能造成多线程之间对全局变量的混乱(即线程非安全)
同步锁
因为数据在共享过程中,会出现竞争资源导致数据错误,此时就需要设计同步锁,使得数据在完成一个线程之后,在进行另外一个线程。切记,获得一个锁,一定要解开上一把锁,才可以进行获得下一个锁,不然会造成死锁。即,逻辑要通顺,才不会导致死锁的产生。
写法
lock=Lock() with lock: 语句 lock.acquire() 语句 lock.release()
from threading import Thread, current_thread from threading import * g_num=0 def run(): #获得这把锁的钥匙 lock.acquire() print("当前进程%s,开始启动"%(current_thread().name)) global g_num #当for的数据不是很大时,不会出现问题,当for的数据很大时,则会出现数据混乱 for i in range(500000): g_num+=1 print("线程%s,执行之后的g_num的是指是%s"%(current_thread().name,g_num)) #释放这把锁 lock.release() if __name__ == '__main__': #创建同步锁 lock=Lock() thread=[] for i in range(20): t=Thread(target=run) t.start() thread.append(t) for j in thread: j.join() print('主线程结束,g_num的值为%s'%g_num) #线程不安全是指没有控制多个线程对同一资源的访问,导致对数据的破坏
递归锁
在程序中不可以同时使用两把锁(例如lock.acquire(),lock.acquire(),lock.release(),lock.release(),这样会导致死锁的产生),若想在一个线程里面,多次调用,可以使用递归锁(rlock)。
import threading #上递归锁 lock = threading.RLock() def h(): with lock: do_something2() def do_something1(): print('do_something1') def do_something2(): print('do_something2') # Create and run threads as follows if __name__ == '__main__': threading.Thread( target=h ).start() threading.Thread( target=h ).start() threading.Thread( target=h ).start()
生产者和消费者模式
队列
Python的Queue模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列PriorityQueue。这些队列都实现了锁原语(可以理解为原子操作,即要么不做,要么就做完),能够在多线程中直接使用。可以使用队列来实现线程间的同步。
生产者和消费者模式
在线程世界里,生产者就是生产数据的线程,消费者就是消费数据的线程。在多线程开发当中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者。为了解决这个问题于是引入了生产者和消费者模式。
import threading import time import queue #创建一个队列,1000表示最大值 q=queue.Queue(100) class producer(threading.Thread): def run(self): #定义全局变量 global q count=0 while True: if q.qsize()<100: for i in range(10): count+=1 msg='产品{}'.format(count) q.put(msg) print(msg) time.sleep(1) class consumer(threading.Thread): def run(self): global q while True: for i in range(10): msg=q.get() print("消费线程的到的数据{}".format(msg)) time.sleep(1) if __name__ == '__main__': t1=producer() t2=consumer() t1.start() t2.start()
线程之间的同步事件
用于线程间的通信,某个线程需要根据其他线程的状态来判断自己的下一步操作。
参数
- set() ——将_flag(标志位)设置为True;
- clear()——将_flag设置为False;
- is_set()——返回当前_flag的状态。等同于isSet()。
- wait()——阻塞当前线程的执行,直到_flag被设置为True。只有当_flag = False时,调用wait()才会阻塞当前线程的运行,此时wait()方法相当于pass(什么也不做)。
#线程1:门,每三秒自动关闭,如果有人通过,则需要重新刷卡开启 #线程2:人,人通过门,门是开着的,则直接通过,之后没人的话,则关闭门 from re import T import threading import time,random from sympy import O, per event=threading.Event()#创建一个事件 event.set() status=0 #status表示门的状态,0-3代表打开,如果等于3,代表关闭 def door(): global status while True: print("当前门的状态{}".format(status)) if event.is_set(): print("当前门是打开的,可以同行!") else: print("门已经关了,需要用户刷卡!") event.wait()#门的吸纳成堵塞等待 if status>=3: print("当门已经打开了,需要自动关闭") event.clear() time.sleep(1) status+=1 def person(): global status n=0 #人的一个计数器,来记录有多少人进入门里面 while True: n+=1 if event.is_set(): print("门开着,{}号进入门".format(n)) else: print('门关着{}号刷卡之后,进入门里里面'.format(n)) event.set() #标志改为TRUE status=0 time.sleep(random.randint(1,10)) if __name__ == '__main__': d=threading.Thread(target=door) d1=threading.Thread(target=person) d.start() d1.start()
异步
同步,就是调用某个东西是,调用方得等待这个调用返回结果才能继续往后执行。异步,和同步相反 调用方不会理解得到结果,而是在调用发出后调用者可用继续执行后续操作,被调用者通过状体来通知调用者,或者通过回掉函数来处理这个调用。简单地说,同步只能等待一个程序执行完之后才可以执行另外一个程序,异步是边执行一个程序的同时,开启另外一个程序,多个程序同时进行。
from multiprocessing import Pool #调用multipeocessing中的pool import time,os def test1(): print("当前进程id{0},它的父进程是{1}".format(os.getpid(),os.getpid())) print("女儿叫你起床,你慢慢的起床") time.sleep(3) print("你起来") return '123' def test2(): print("女儿开始早读,当前进程是%s"%os.getpid()) time.sleep(2) print("女儿早读完成") def test3(args): print("一起吃早餐,当前进程的id是%s"%os.getpid()) print("参数是%s"%args) if __name__ == '__main__': pool=Pool(4) pool.apply_async(func=test1,callback=test3)#回调函数 #主进程代表女叫父亲起床,然后早读 test2() print("主进程完成,主进程%s"%os.getpid())
4、协程
在一个线程中的某个函数中,我们可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的 ,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定。简单地说,根据多个函数需要停顿和切换的时间,来切换到另外的函数。
#greenlet是需要手动的设置切换 from greenlet import greenlet def ask(name): print("%s,我要买一个手提包"%name)# 第2个语句 b.switch("吕布") print("%s:我要学习python"%name)# 第4个语句 b.switch()#人物的切换 def answer(name): print('%s:买买买'%name)# 第1个语句 a.switch() print("%s:好的,买!"%name)# 第3个语句 if __name__ == '__main__': a=greenlet(ask) #创建一个协程 b=greenlet(answer) a.switch("貂蝉")#每个函数在第一次切换的时候才需要传参,后面不需要传参 #gevent实现不需要手动交互切换 print() import gevent def ask1(name): print("%s,我要买一个手提包"%name)#2 gevent.sleep(0) print("%s:我要学习python"%name)#4 def answer2(name): print('%s:买买买'%name)#1 gevent.sleep(0) print("%s:好的,买!"%name)#3 a1=gevent.spawn(ask1,'小桥') b1=gevent.spawn(answer2,'周瑜') gevent.joinall([a1,b1]) #自动切换并执行 #asynico异步并发 print() #当fun1等待的时候,fun2就正在执行,也就是说两个函数是并发的,需要的总时间是5秒 import asyncio,time async def fun1():#定义一个协程 for i in range(5): print('协程a!!') await asyncio.sleep(1) # sleep遇到堵塞的话就切换另外一个函数的使用 async def fun2(): for i in range(5): print('协程b!!') await asyncio.sleep(1) #获取循环事件 start=time.time() loop=asyncio.get_event_loop() #启动多个自行并发执行 loop.run_until_complete(asyncio.gather(fun1(),fun2())) loop.close()#关闭 end=time.time() print("完成两个并发函数需要的时间是%f"%(end-start))
本文作者:灰之魔女伊蕾娜
本文链接:https://www.cnblogs.com/daohengdao/p/15953263.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步