人工智能_1
本节内容 预备资料:
1.FFmpeg:
链接:https://pan.baidu.com/s/1jonSAa_TG2XuaJEy3iTmHg
密码:w6hk
2.baidu-aip:
pip install baidu-aip
终于进入主题了,此篇是人工智能应用的重点,只用现成的技术不做底层算法,也是让初级程序员快速进入人工智能行业的捷径
目前市面上主流的AI技术提供公司有很多,比如百度,阿里,腾讯,主做语音的科大讯飞,做只能问答的图灵机器人等等
这些公司投入了很大一部分财力物力人力将底层封装,提供应用接口给我们,尤其是百度,完全免费的接口
既然百度这么仗义,咱们就不要浪费掉怎么好的资源,从百度AI入手,开启人工智能之旅
开启人工智能技术的大门 : http://ai.baidu.com/
看看我大百度的AI大法,这些技术全部都是封装好的接口,看着就爽
接下来咱们就一步一步的操作一下
首先进入控制台,注册一个百度的账号(百度账号通用)

开通一下我们百度AI开放平台的授权
然后找到已开通服务中的百度语音
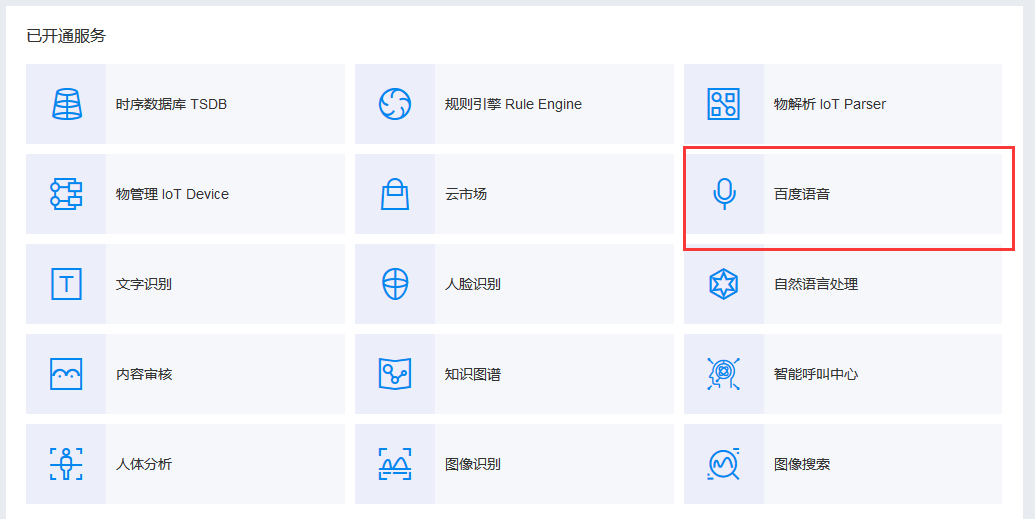
走到这里,想必已经知道咱们要从语音入手了,语音识别和语音合成
打开百度语音,进入语音应用管理界面,创建一个新的应用 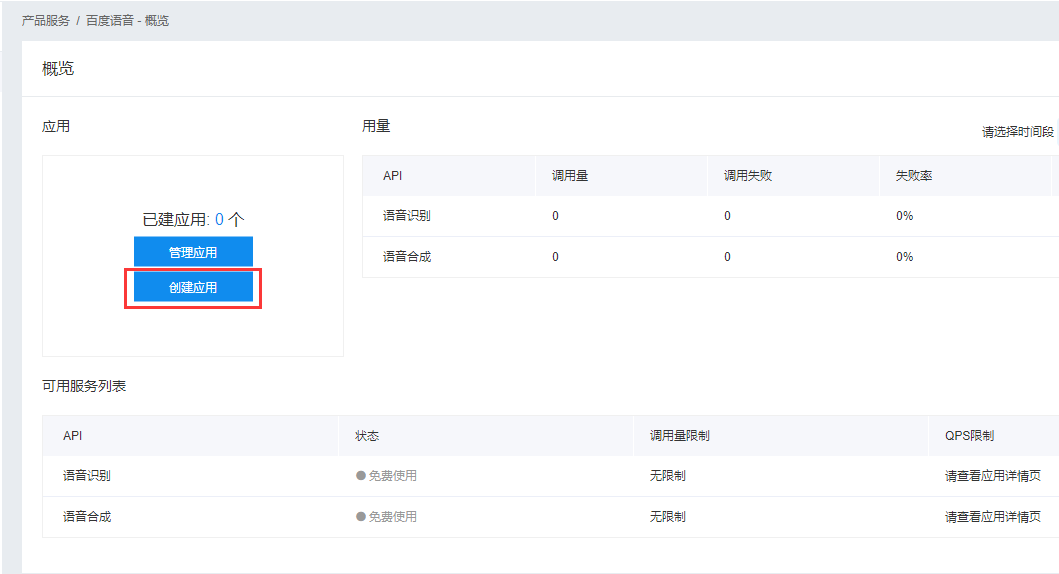
创建语音应用App

就可以创建应用了,回到应用列表我们可以看到已创建的应用了

这里面有三个值 AppID , API Key , Secret Key 记住可以从这里面看到 , 在之后的学习中我们会用到
好了 百度语音的应用已经创建完成了 接下来 我会用Python 代码作为实例进行应用及讲解
一.安装百度的人工智能SDK:
首先咱们要 pip install baidu-aip 安装一个百度人工智能开放平台的Python SDK实在是太方便了,这也是为什么我们选择百度人工智能的最大原因
安装完成之后就来测试一下:
二:语音合成:
点击技术文档--->语音合成--->SDK文档--->python SDK,即可进入百度语音,语音合成这块的官方文档。
新建AipSpeech
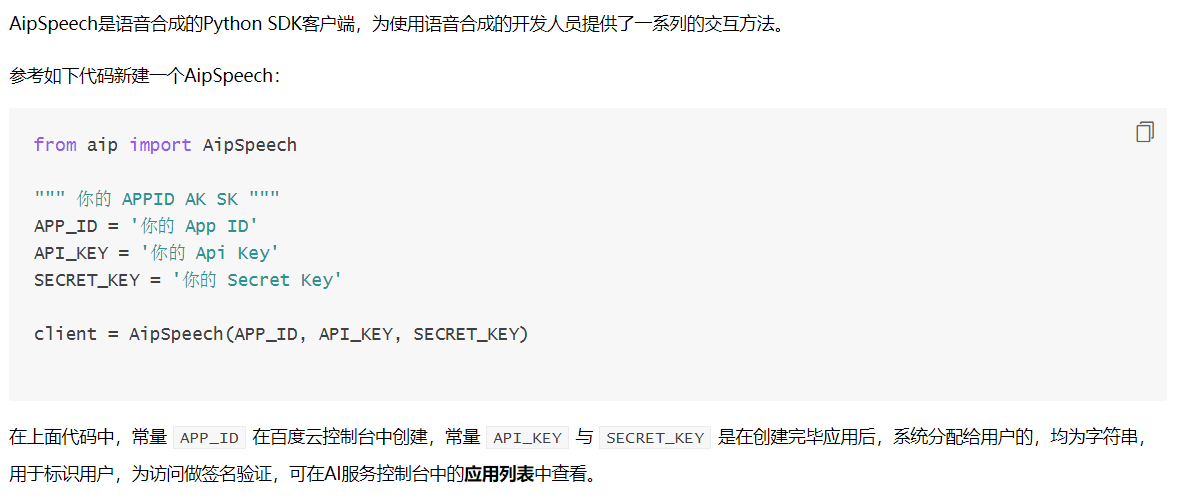
接口说明


将是上面的内容整理到一个py文件中,运行后会生成一个auido.mp3文件,右键--->show in explorer,选择文件即可播放我们设置的内容。
from aip import AipSpeech """ 这里的三个参数,对应着在百度语音创建应用的三个参数 """ APP_ID = '14941553' API_KEY = 'bSpjBoeEp7vNACh8U1ZGTU8h' SECRET_KEY = 'oBBRhRZnT7RHwFG28ChjVPwGS1CNSX4f' # 这是与百度进行一次加密校验 , 认证你是合法用户 合法的应用 # AipSpeech 是百度语音的客户端 认证成功之后,客户端将被开启,这里的client 就是已经开启的百度语音的客户端了 client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) result = client.synthesis('黑化黑灰化肥灰会挥发发灰黑讳为黑灰花会回飞,灰化灰黑化肥会会挥发发黑灰为讳飞花回化为灰', # text:合成的文本,使用utf-8编码,请注意文本长度必须小于1024字节 'zh', # lang:语言,中文:zh 英文:en 1, { # ctp:客户端信息,这里就写1,写别的不好使 "spd": 5, 'vol': 5, "pit": 8, "per": 4 } # options:这是一个dict类型的参数,里面的值才是关键 # 成功返回二进制文件流 # 失败返回 # { # "err_no":500, # "err_msg":"notsupport.", # "sn":"abcdefgh", # "idx":1 # } # 错误返回格式 # 若请求错误,服务器将返回的JSON文本包含以下参数: # # error_code:错误码。 # error_msg:错误描述信息,帮助理解和解决发生的错误。 # 错误码 # 错误码 含义 # 500 不支持的输入 # 501 输入参数不正确 # 502 token验证失败 # 503 合成后端错误 ) # 如果上面的参数提填写正确的话,result就是我们音频文件的流了,如果返回失败的话,result就会是一个字典 print(result) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 # 接下来就把result写入文件。 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result)
语音识别:
声音这个东西格式太多样化了,如果要想让百度的SDK识别咱们的音频文件,就要想办法转变成百度SDK可以识别的格式PCM,使用ffmpeg工具可以达到这个效果
windows10配置环境变量,右击我的电脑,选择属性,进入如下页面,操作完成后点击确定即可 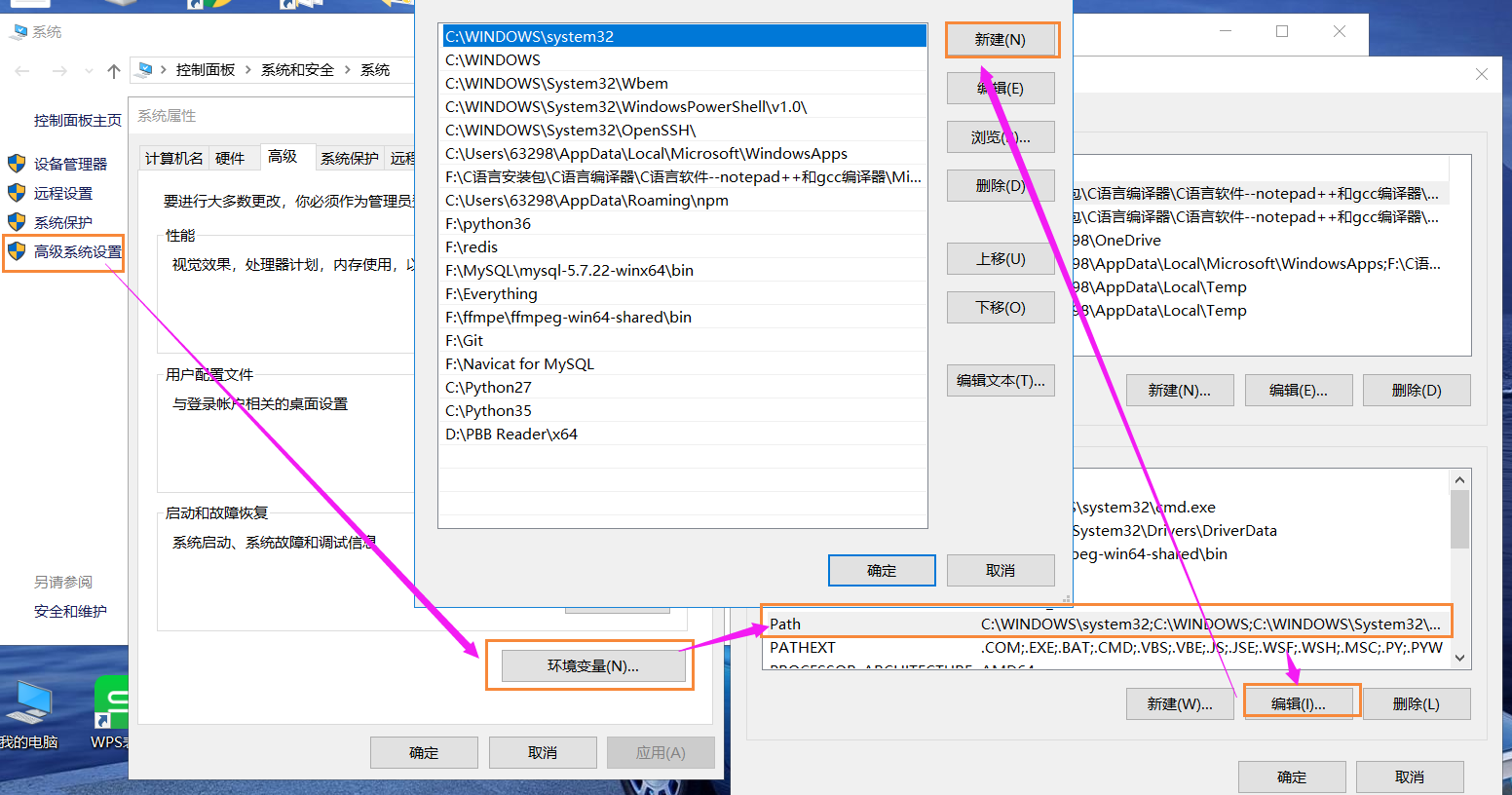
在终端输入ffmpeg,如果出现如下页面,表示添加环境变量成功

上面那个命令可以将wav wma mp3 等音频文件转换为 pcm 无压缩音频文件
先用windows自带的录音机录一段音频(讲普通话)将其命名为record.m4v
然后在终端使用命令:ffmpeg -y -i record.m4a -acodec pcm_s16le -f s16le -ac 1 -ar 16000 record.pcm
就可以将这段录音的格式转化为pcm格式。
切换到项目目录下:D:\s13\ai_1
pcm文件已经得到了,和下面的文件要在同一个命令下
百度语音识别sdk的应用:
from aip import AipSpeech # 百度语音识别 """ 这里的三个参数,对应着在百度语音创建应用的三个参数 """ APP_ID = '14941553' API_KEY = 'bSpjBoeEp7vNACh8U1ZGTU8h' SECRET_KEY = 'oBBRhRZnT7RHwFG28ChjVPwGS1CNSX4f' # 这是与百度进行一次加密校验 , 认证你是合法用户 合法的应用 # AipSpeech 是百度语音的客户端 认证成功之后,客户端将被开启,这里的client 就是已经开启的百度语音的客户端了 client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read() # 识别本地文件 res = client.asr(get_file_content('record.pcm'), 'pcm', 16000, { 'dev_pid': 1536, }) print(res.get("result")[0]) # 超哥超哥就是屌没电也能跑 print(res) # {'corpus_no': '6628135090218706981', 'err_msg': 'success.', 'err_no': 0, 'result': ['超哥超哥就是屌没电也能跑'], 'sn': '259433396051543232959'}
百度语音自动识别
from aip import AipSpeech import os # 百度语音自动识别 """ 这里的三个参数,对应着在百度语音创建应用的三个参数 """ APP_ID = '14941553' API_KEY = 'bSpjBoeEp7vNACh8U1ZGTU8h' SECRET_KEY = 'oBBRhRZnT7RHwFG28ChjVPwGS1CNSX4f' # 这是与百度进行一次加密校验 , 认证你是合法用户 合法的应用 # AipSpeech 是百度语音的客户端 认证成功之后,客户端将被开启,这里的client 就是已经开启的百度语音的客户端了 client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 读取文件 def get_file_content(filePath): # os.system(f"ffmpeg -y -i record.m4a -acodec pcm_s16le -f s16le -ac 1 -ar 16000 record.pcm") os.system(f"ffmpeg -y -i {filePath} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filePath}.pcm") with open(f"{filePath}.pcm", 'rb') as fp: return fp.read() # 识别本地文件 res = client.asr(get_file_content('auido.mp3'), 'pcm', 16000, { # res = client.asr(get_file_content('record.m4a'), 'pcm', 16000, { 'dev_pid': 1536, }) # 这里必须自己录音,用接口转化的都不时连贯的,会发生歧义 # 使用此方法时,必须将pycharm重启,释放掉进程后,重新加载资源才能成功 print(res.get("result")[0]) # 黑化黑灰化肥灰会挥发发灰吹出来黑灰花会回飞灰化灰黑化肥灰黑灰玫瑰飞花非花玫瑰 # print(res.get("result")[0]) # 超哥超哥就是屌没电也能跑 # print(res)
asr函数需要四个参数,第四个参数可以忽略,自有默认值,参照一下这些参数是做什么的
第一个参数: speech 音频文件流 建立包含语音内容的Buffer对象, 语音文件的格式,pcm 或者 wav 或者 amr。(虽说支持这么多格式,但是只有pcm的支持是最好的)
第二个参数: format 文件的格式,包括pcm(不压缩)、wav、amr (虽说支持这么多格式,但是只有pcm的支持是最好的)
第三个参数: rate 音频文件采样率 如果使用刚刚的FFmpeg的命令转换的,你的pcm文件就是16000
第四个参数: dev_pid 音频文件语言id 默认1537(普通话 输入法模型)
成功的dict中 result 就是我们要的识别文本
失败的dict中 err_no 就是我们要的错误编码,错误编码代表什么呢?

根据文本和语音的相互转化,实现简单的判断逻辑
from aip import AipSpeech import os # 跟我们学说话 """ 这里的三个参数,对应着在百度语音创建应用的三个参数 """ APP_ID = '14941553' API_KEY = 'bSpjBoeEp7vNACh8U1ZGTU8h' SECRET_KEY = 'oBBRhRZnT7RHwFG28ChjVPwGS1CNSX4f' # 这是与百度进行一次加密校验 , 认证你是合法用户 合法的应用 # AipSpeech 是百度语音的客户端 认证成功之后,客户端将被开启,这里的client 就是已经开启的百度语音的客户端了 client = AipSpeech(APP_ID, API_KEY, SECRET_KEY) # 语音识别,将声音文件转成文本信息。 def audio_to_text(filename): os.system(f"ffmpeg -y -i {filename} -acodec pcm_s16le -f s16le -ac 1 -ar 16000 {filename}.pcm") with open(f"{filename}.pcm", 'rb') as fp: res = client.asr(fp.read(), 'pcm', 16000, { 'dev_pid': 1536, }) print(res.get("result")[0]) return res.get("result")[0] # audio_to_text("record.m4a") # 超哥超哥就是屌没电也能跑 # 将文本信息转化成语音文件 def text_to_audio(text): result = client.synthesis(text, # text:合成的文本,使用utf-8编码,请注意文本长度必须小于1024字节 'zh', # lang:语言,中文:zh 英文:en 1, { # ctp:客户端信息,这里就写1,写别的不好使 "spd": 5, 'vol': 5, "pit": 8, "per": 4 }) # 如果上面的参数提填写正确的话,result就是我们音频文件的流了,如果返回失败的话,result就会是一个字典 # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 # 接下来就把result写入文件。 if not isinstance(result, dict): with open('auido.mp3', 'wb') as f: f.write(result) os.system("auido.mp3") # # windows有个环境变量的配置,可以根据文件.后面的格式自己调用默认的播放器 # text_to_audio("四十五度仰望天空") # 调用的结果:语音读出来四十五度仰望天空 text=audio_to_text("record.m4a") if "超哥超哥就是屌没电也能跑" in text: text_to_audio("你怎么不去死呢") else: text_to_audio(f"你刚才是不是说,{text}")
如果err_no不是0的话,就参照一下错误码表
到此百度AI语音部分的调用就结束了,是不是感觉很简单
刚刚学完练习一下:
1.尝试从语音识别中拿出result对应的中文
2.尝试你说一句话,然后让百度AI学你说话
3.尝试使用对话的方式,得到你叫什么名字,你今年几岁了,这样简单问题的答案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号