

HDFS读数据流程
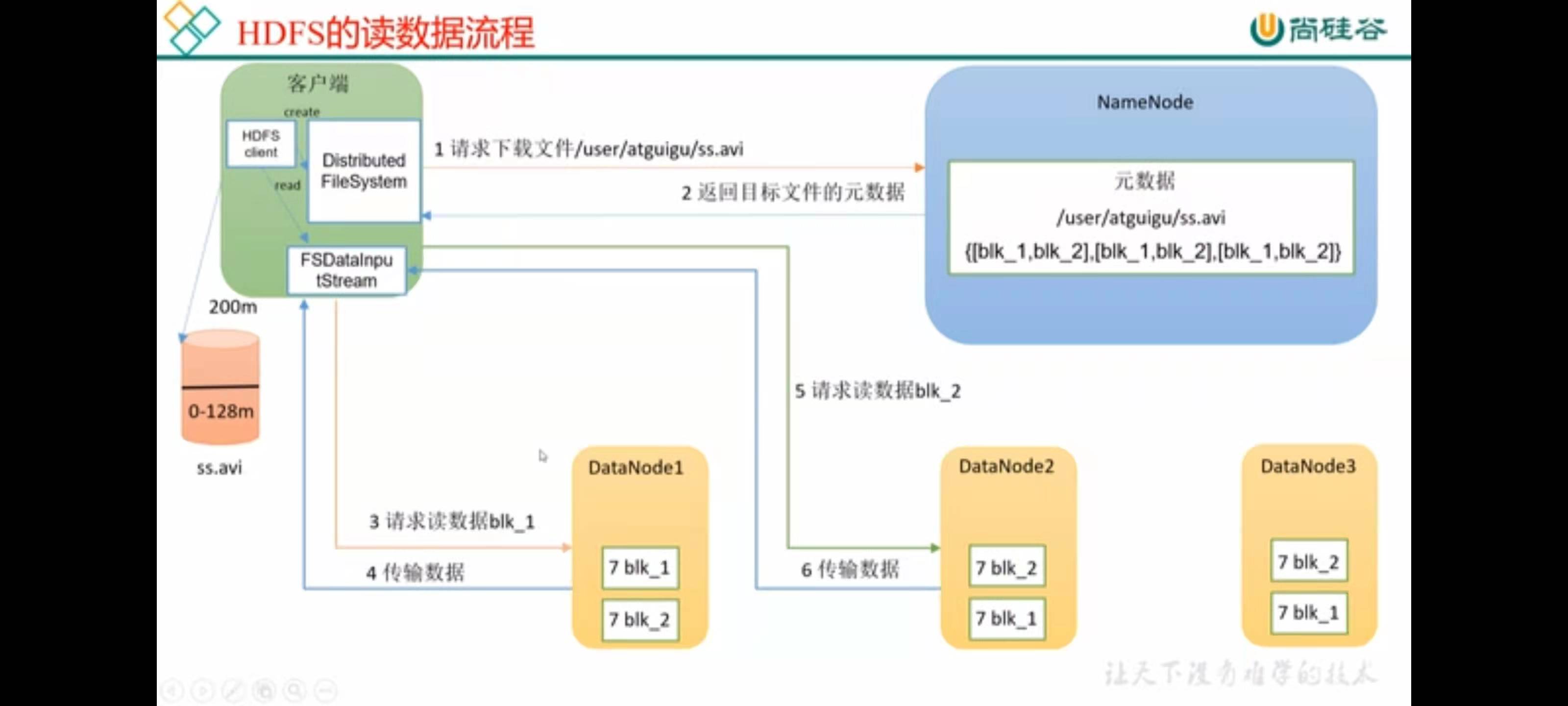
(1) 客户端向NameNode发起RPC请求,来获取请求文件Block数据块所在的位置。
(2) NameNode检测元数据文件,会视情况返回Block块信息或者全部Block块信息,对于每个Block块,NameNode都会返回含有该Block副本的DataNode地址。
(3) 客户端会选取排序靠前的DataNode来依次读取Block块(如果客户端本身就是DataNode,那么将从本地直接获取数据),每一个Block都会进行CheckSum(完整性验证),若文件不完整,则客户端会继续向NameNode获取下一批的Block列表,直到验证读取出来文件是完整的,则Block读取完毕。
(4) 客户端会把最终读取出来所有的Block块合并成一个完整的最终文件(例如:1.txt)。
小提示:
NameNode返回的DataNode地址,会按照集群拓扑结构得出DataNode与客户端的距离,然后进行排序。排序有两个规则:网络拓扑结构中距离客户端近的则靠前;心跳机制中超时汇报的DataNode状
