
服务器硬件资源分享
pu,内存,硬盘之间的关系
CPU:是计算机的运算核心和控制核心,让电脑的各个部件顺利工作,起到协调和控制作用。
硬盘:存储资料和软件等数据的设备,有容量大,断电数据不丢失的特点。也被人们称之为“数据仓库”。
内存:1. 负责硬盘等硬件上的数据与CPU之间数据交换处理;2. 缓存系统中的临时数据。3. 断电后数据丢失。
然后, 我们再来看一下程序是如何执行起来的。
当我们在电脑上打开QQ时(右键-打开 或者双击QQ图标),其实是通过鼠标(输入设备)向CPU发送了一条命令,CPU接收到这条命令后,QQ程序就从硬盘里被加载到内存(加载时不通过处理器,直接从硬盘加载程序到内存里),加载完成后,CPU就开始执行QQ程序。程序执行起来后,CPU可以让QQ程序显示在我们的在显示器上。也就是你看到了QQ 程序运行起来了。如果这个时候,你用QQ截取了一张屏幕的图片,那么这张图片会首先保存到内存,在没有退出截屏状态时,你可以在这张图片上写字、画线条,等你右键保存这张图片的时候,这张图片就会保存到硬盘里。
三者之间的关系:
简单来说,硬盘用来存储我们的程序和数据,当我们运行程序的时候,CPU首先接受到我们的命令,之后CPU是告诉硬盘,我要运行你存储的程序A,你把程序A送到内存去。CPU对内存说,我让硬盘把程序A送到你这里来了,你保存一下。 等程序A被完整的送到内存之后。CPU就开始执行程序A。
过程就像上面说的,我们在举一个接近我们生活的例子。
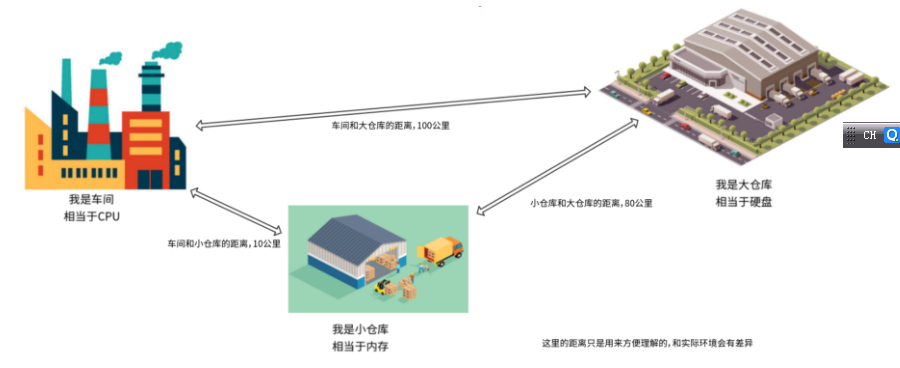
如果说把硬盘比喻成一个大仓库,CPU比喻成加工车间,那么内存就是一个临时的小仓库。从距离上来说, 相比内存到CPU的距离和硬盘到内存的距离,内存和CPU的距离更短。
硬盘(大仓库)用来保存车间需要用的原料和最终生产出来的商品。仓库太大,取出原料和存储商品太慢,耗时间。
内存(临时小仓库):原料会先放到这里,小仓库,可以很快的找到需要的原料或商品。
CPU(车间):从内存(小仓库)里拿到原料,生产商品。中间会有半成品,半成品可以放在内存(小仓库)里。
以这种方式,车间的生产速度就会提高。
参考图
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
CPU:中央处理器(CPU,Central Processing Unit)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据

二、首先要明确物理cpu个数、核数、逻辑cpu数的概念
1.物理cpu数:主板上实际插入的cpu数量,可以数不重复的 physical id 有几个(physical id)
2.cpu核数:单块CPU上面能处理数据的芯片组的数量,如双核、四核等 (cpu cores)
3.逻辑cpu数:一般情况下,逻辑cpu=物理CPU个数×每颗核数,如果不相等的话,则表示服务器的CPU支持超线程技术(HT:简单来说,它可使处理器中的1 颗内核如2 颗内核那样在操作系统中发挥作用。这样一来,操作系统可使用的执行资源扩大了一倍,大幅提高了系统的整体性能,此时逻辑cpu=物理CPU个数×每颗核数x2)
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
----------------------------------------------------------------------
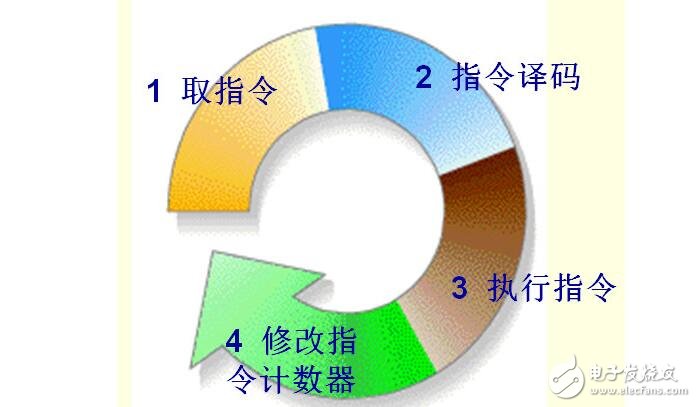
CPU的运行原理就是:
1、取指令:CPU的控制器从内存读取一条指令并放入指令寄存器。指令的格式一般是这个样子滴:

操作码就是汇编语言里的mov,add,jmp等符号码;操作数地址说明该指令需要的操作数所在的地方,是在内存里还是在CPU的内部寄存器里。
2、指令译码:指令寄存器中的指令经过译码,决定该指令应进行何种操作(就是指令里的操作码)、操作数在哪里(操作数的地址)。
3、 执行指令,分两个阶段“取操作数”和“进行运算”。
4、 修改指令计数器,决定下一条指令的地址。
------------------------------------------------------------------------------------------------------------------------------------------------------
获取cpu数据:vmstat 2

字段含义说明:(参考文档:https://www.cnblogs.com/tommyli/p/3746187.html)
|
类别 |
项目 |
含义 |
说明 |
|
Procs(进程) |
r |
等待执行的任务数 |
展示了正在执行和等待cpu资源的任务个数。当这个值超过了cpu个数,就会出现cpu瓶颈。 |
|
B |
等待IO的进程数量 |
|
|
|
Memory(内存) |
swpd |
正在使用虚拟的内存大小,单位k |
|
|
free |
空闲内存大小 |
|
|
|
buff |
已用的buff大小,对块设备的读写进行缓冲 |
|
|
|
cache |
已用的cache大小,文件系统的cache |
|
|
|
inact |
非活跃内存大小,即被标明可回收的内存,区别于free和active |
具体含义见:概念补充(当使用-a选项时显示) |
|
|
active |
活跃的内存大小 |
具体含义见:概念补充(当使用-a选项时显示) |
|
|
Swap |
si |
每秒从交换区写入内存的大小(单位:kb/s) |
|
|
so |
每秒从内存写到交换区的大小 |
|
|
|
IO |
bi |
每秒读取的块数(读磁盘) |
现在的Linux版本块的大小为1024bytes |
|
bo |
每秒写入的块数(写磁盘) |
|
|
|
system |
in |
每秒中断数,包括时钟中断 |
这两个值越大,会看到由内核消耗的cpu时间会越多 |
|
cs |
每秒上下文切换数 |
||
|
CPU(以百分比表示) |
Us |
用户进程执行消耗cpu时间(user time) |
us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期超过50%的使用,那么我们就该考虑优化程序算法或其他措施了 |
|
Sy |
系统进程消耗cpu时间(system time) |
sys的值过高时,说明系统内核消耗的cpu资源多,这个不是良性的表现,我们应该检查原因。 |
|
|
Id |
空闲时间(包括IO等待时间) |
|
|
|
wa |
等待IO时间 |
Wa过高时,说明io等待比较严重,这可能是由于磁盘大量随机访问造成的,也有可能是磁盘的带宽出现瓶颈。 |
常见问题处理
如果r经常大于4,且id经常少于40,表示cpu的负荷很重。
如果pi,po长期不等于0,表示内存不足。
如果disk经常不等于0,且在b中的队列大于3,表示io性能不好。
1.)如果在processes中运行的序列(process r)是连续的大于在系统中的CPU的个数表示系统现在运行比较慢,有多数的进程等待CPU。
2.)如果r的输出数大于系统中可用CPU个数的4倍的话,则系统面临着CPU短缺的问题,或者是CPU的速率过低,系统中有多数的进程在等待CPU,造成系统中进程运行过慢。
3.)如果空闲时间(cpu id)持续为0并且系统时间(cpu sy)是用户时间的两倍(cpu us)系统则面临着CPU资源的短缺。
解决办法:
当发生以上问题的时候请先调整应用程序对CPU的占用情况.使得应用程序能够更有效的使用CPU.同时可以考虑增加更多的 CPU. 关于CPU的使用情况还可以结合mpstat, ps aux top prstat –a等等一些相应的命令来综合考虑关于具体的CPU的使用情况,和那些进程在占用大量的CPU时间.一般情况下,应用程序的问题会比较大一些.比如一些 sql语句不合理等等都会造成这样的现象.
内存问题现象:
内存的瓶颈是由scan rate (sr)来决定的.scan rate是通过每秒的始终算法来进行页扫描的.如果scan rate(sr)连续的大于每秒200页则表示可能存在内存缺陷.同样的如果page项中的pi和po这两栏表示每秒页面的调入的页数和每秒调出的页数. 如果该值经常为非零值,也有可能存在内存的瓶颈,当然,如果个别的时候不为0的话,属于正常的页面调度这个是虚拟内存的主要原理.
解决办法:
1.调节applications & servers使得对内存和cache的使用更加有效.
2.增加系统的内存.
3. Implement priority paging in s in pre solaris 8 versions by adding line "set priority paging=1" in /etc/system. Remove this line if upgrading from Solaris 7 to 8 & retaining old /etc/system file.
关于内存的使用情况还可以结ps aux top prstat –a等等一些相应的命令来综合考虑关于具体的内存的使用情况,和那些进程在占用大量的内存.一般情况下,如果内存的占用率比较高,但是,CPU的占用很低 的时候,可以考虑是有很多的应用程序占用了内存没有释放,但是,并没有占用CPU时间,可以考虑应用程序,对于未占用CPU时间和一些后台的程序,释放内 存的占用。
- 先看CPU利用率,如果CPU利用率不高,但是系统的Throughput和Latency上不去了,这说明程序并没有忙于计算,而是忙做其它事,比如IO。(另外,CPU的利用率还要看内核态的和用户态的,内核态的上去了,整个系统的性能就下来了。而对于多核CPU来说,CPU 0 是相当关键的,如果CPU 0的负载高,那么会影响其它核的性能,因为CPU各核间是需要有调度的,这靠CPU0完成)
- 然后,我们可以查看一下IO大小,IO和CPU一般是反着来的,CPU利用率高则IO不大,IO大则CPU就小。关于IO,我们要看三个事,一个是磁盘文件IO,一个是驱动程序的IO(如:网卡),一个是内存换页率。这三个事都会影响系统性能。
- 然后,查看一下网络带宽使用情况。
- 如果CPU不高,IO不高,内存使用不高,网络带宽使用不高。但是系统的性能上不去。这说明你的程序有问题,比如,你的程序被阻塞了。可能是因为等那个锁,可能是因为等某个资源,或者是在切换上下文。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
内存是计算机中重要的部件之一,它是与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大。内存(Memory)也被称为内存储器,其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。只要计算机在运行中,CPU就会把需要运算的数据调到内存中进行运算,当运算完成后CPU再将结果传送出来,内存的运行也决定了计算机的稳定运行。
CPU就好比是搬运工人,搬运工的耐力和搬运的速度,就好比CPU的性能和频率。
数据就好比是砖头,砖头数量越多说明数据越大。
砖场就好比是硬盘,放置砖头的地方,砖场越大存放的砖就越多。就好比硬盘,容量越大里面存储的数据量越大。
拖车就好比是内存。拖车大,一次性拖的砖头就越多。就好比内存一次性读取的数据也越多。
----------------------------------------------------------------------------------------------------------------------------------------------------------------
内存是计算机中重要的部件之一,它是与CPU进行沟通的桥梁。计算机中所有程序的运行都是在内存中进行的,因此内存的性能对计算机的影响非常大。内存(Memory)也被称为内存储器,其作用是用于暂时存放CPU中的运算数据,以及与硬盘等外部存储器交换的数据。只要计算机在运行中,CPU就会把需要运算的数据调到内存中进行运算,当运算完成后CPU再将结果传送出来,内存的运行也决定了计算机的稳定运行。
cat /proc/meminfo
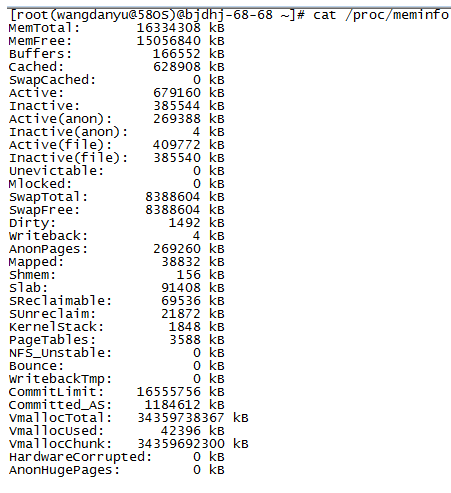
MemTotal: 所有可用RAM大小 (即物理内存减去一些预留位和内核的二进制代码大小)
MemFree: LowFree与HighFree的总和
Buffers: 用来给块设备做的缓冲大小(只记录文件系统的metadata以及 tracking in-flight pages,就是说 buffers是用来存储,目录里面有什么内容,权限等等。)
Cached: 用来给文件做缓冲大小(直接用来记忆我们打开的文件). 它不包括SwapCached
SwapCached: 已经被交换出来的内存,但仍然被存放在swapfile中。用来在需要的时候很快的被替换而不需要再次打开I/O端口。
Active: 最近经常被使用的内存,除非非常必要否则不会被移作他用.
Inactive: 最近不经常被使用的内存,非常用可能被用于其他途径.
HighTotal:
HighFree: 高位内存是指所有在860MB以上的内存空间,该区域主要用于用户空间的程序或者是缓存页面。内核必须使用不同的手法使用该段内存,因此它比低位内存要慢一些。
LowTotal:
LowFree: 低位可以达到高位内存一样的作用,而且它还能够被内核用来记录一些自己的数据结构。
Among many other things, it is where everything from the Slab is
allocated. Bad things happen when you're out of lowmem.
SwapTotal: 交换空间的总和
SwapFree: 从RAM中被替换出暂时存在磁盘上的空间大小
Dirty: 等待被写回到磁盘的内存大小。
Writeback: 正在被写回到磁盘的内存大小。
Mapped: 影射文件的大小。
Slab: 内核数据结构缓存
VmallocTotal: vmalloc内存大小
VmallocUsed: 已经被使用的虚拟内存大小。
VmallocChunk: largest contigious block of vmalloc area which is free
CommitLimit:
Committed_AS:
m.MemFree + m.Buffers + m.Cached=总空闲内存
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
网络
系统应用之间的交互,尤其是跨机器之间的,都是基于网络的,因此网络宽带,响应时间,网络延迟,阻塞都是响应系统性能的因素。

-----------------------------------------------------------------------------------------------------------------------------------------------------------------
i/o
访问应用离不开系统的磁盘数据读写,I/0读写的性能直接影响系统程序的性能,磁盘i/o是系统中最慢的部分。针对I/o场景模型,我们要考虑io的tps,平均i/o数据,平均队列长度,平均服务时间,平均等待时间,io利用率。
参考文档:https://blog.csdn.net/qq_20332637/article/details/82146753
iostat -x -k -d vda 2

| 选项 | 说明 |
|---|---|
| rrqm/s | 每秒对该设备的读请求被合并次数,文件系统会对读取同块(block)的请求进行合并 |
| wrqm/s | 每秒对该设备的写请求被合并次数 |
| r/s | 每秒完成的读次数 |
| w/s | 每秒完成的写次数 |
| rkB/s | 每秒读数据量(kB为单位) |
| wkB/s | 每秒写数据量(kB为单位) |
| avgrq-sz | 平均每次IO操作的数据量(扇区数为单位) |
| avgqu-sz | 平均等待处理的IO请求队列长度 |
| await | 平均每次IO请求等待时间(包括等待时间和处理时间,毫秒为单位) |
| svctm | 平均每次IO请求的处理时间(毫秒为单位) |
| %util | 采用周期内用于IO操作的时间比率,即IO队列非空的时间比率 |
如果%util接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈,idle小于70% IO压力就较大了,一般读取速度有较多的wait。同时可以结合vmstat(virtual memory status)查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)
另外还可以参考svctm,由于它一般要小于 await (因为同时等待的请求的等待时间被重复计算了),svctm 的大小一般和磁盘性能有关,CPU/内存的负荷也会对其有影响,请求过多也会间接导致svctm 的增加。await 的大小一般取决于服务时间(svctm) 以及 I/O 队列的长度和 I/O 请求的发出模式。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果await 远大于 svctm,说明 I/O 队列太长,应用得到的响应时间变慢,如果响应时间超过了用户可以容许的范围,这时可以考虑更换更快的磁盘,调整内核 elevator 算法,优化应用,或者升级 CPU。队列长度(avgqu-sz)也可作为衡量系统 I/O 负荷的指标,但由于 avgqu-sz 是按照单位时间的平均值,所以不能反映瞬间的 I/O 洪水。
例子(I/O 系统 vs. 超市排队)
举一个例子,我们在超市排队 checkout 时,怎么决定该去哪个交款台呢? 首当是看排的队人数,5个人总比20人要快吧? 除了数人头,我们也常常看看前面人购买的东西多少,如果前面有个采购了一星期食品的大妈,那么可以考虑换个队排了。还有就是收银员的速度了,如果碰上了连钱都点不清楚的新手,那就有的等了。另外,时机也很重要,可能 5 分钟前还人满为患的收款台,现在已是人去楼空,这时候交款可是很爽啊,当然,前提是那过去的 5 分钟里所做的事情比排队要有意义(不过我还没发现什么事情比排队还无聊的)。
I/O 系统也和超市排队有很多类似之处:
r/s+w/s 类似于交款人的总数
平均队列长度(avgqu-sz)类似于单位时间里平均排队人的个数
平均服务时间(svctm)类似于收银员的收款速度
平均等待时间(await)类似于平均每人的等待时间
平均I/O数据(avgrq-sz)类似于平均每人所买的东西多少
I/O 操作率(%util)类似于收款台前有人排队的时间比例。
标准:iwait 不能低于5ms %util 不能超过80%
参考:http://blog.51cto.com/lfsoul/1176501
标准:iwait 不能低于5ms %util 不能超过80%

