DPDK QoS之分层调度器
原创翻译,转载请注明出处。
分层调度器的时机主要体现在TX侧,正好在传递报文之前。它的主要目的是在每个网络节点按照服务级别协议来对不同的流量分类和对不同的用户的报文区分优先级并排序。
一、概述
分层调度器跟以前使用网络处理器实现的每条流或一组流的报文队列和调度的流量管理器很相似。它看起来像在传输之前的一个临时存储了很大数量报文的缓冲区(入队操作)。当网卡TX请求更多报文去发送的时候,这些报文递交给网卡TX的预定义的SLA的报文选择逻辑模块之后会删除。(出队操作)。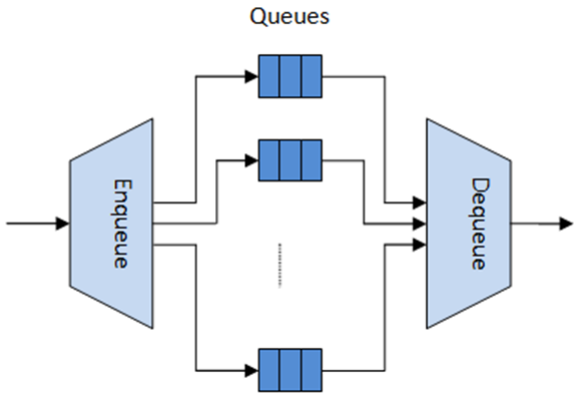
分层调度器对大数量的报文队列做了优化。当只需要小数量的队列时,会使用消息传递队列来替代。更多详情参考"Worst Case Scenarios for Performance"。
二、分层调度
如下图:
分层的第一级是 Ethernet TX 1/10/40端口,之后的分级是子端口,流水线,流分类和队列。
有代表性的是,每一个子端口表示一个预定义好的用户组,而每一个流水线表示一个个人用户。每一个流分类表示不同的流量类型,流量类型包含了具体的丢包率,时延,抖动等需求,比如语音,视频或数据传输。每一个队列从一到多个相同用户相同类型的连接里接待(原文是动词:host)报文。
下面的表格对每个分层做了功能描述:
# 级别 兄弟 功能描述
1 Port 0 1、以太端口1/10/40 GbE输出; 2、多个端口具有相同的优先级,RR调度
2 Subport 可配置,默认8个 1、使用令牌桶算法流量整形(每个子端口一个令牌桶) 2、每个流分类在子端口级别上有强制上限。 3、当高优先级不使用时,低优先级的流分类可以重用子端口的带宽
3 Pipe 可配置,默认4K 1、使用令牌桶算法流量整形,每个流水线一个令牌桶
4 Traffic Class 4 1、同一个流水线的流分类按严格优先级顺序处理 2、在流水线级别每个流分类有强制的上限 3、当高优先级不使用时,低优先级的流分类可以重用流水线的带宽 4、当子端口流分类超额订购之后(配置造成的),流水线的流分类上限是一个动态调整的值。并共享给所有子端口流水线
5 queue 4 1、同一个流分类里的队列按照预定义的权重按WRR调度
三、API
1.端口调度配置API
rte_sched.h里包含了端口,子端口和流水线的配置函数。
2.端口调度器入队API
int rte_sched_port_enqueue(struct rte_sched_port *port, struct rte_mbuf **pkts, uint32_t n_pkts)
3.端口调度器出队API
int rte_sched_port_dequeue(struct rte_sched_port *port, struct rte_mbuf **pkts, uint32_t n_pkts)
4.使用举例
1 /* File "application.c" */ 2 #define N_PKTS_RX 64 3 #define N_PKTS_TX 48 4 #define NIC_RX_PORT 0 5 #define NIC_RX_QUEUE 0 6 #define NIC_TX_PORT 1 7 #define NIC_TX_QUEUE 0 8 struct rte_sched_port *port = NULL; 9 struct rte_mbuf *pkts_rx[N_PKTS_RX], *pkts_tx[N_PKTS_TX]; 10 uint32_t n_pkts_rx, n_pkts_tx; 11 /* Initialization */ 12 <initialization code> 13 /* Runtime */ 14 while (1) { 15 /* Read packets from NIC RX queue */ 16 n_pkts_rx = rte_eth_rx_burst(NIC_RX_PORT, NIC_RX_QUEUE, pkts_rx, N_PKTS_RX); 17 /* Hierarchical scheduler enqueue */ 18 rte_sched_port_enqueue(port, pkts_rx, n_pkts_rx); 19 /* Hierarchical scheduler dequeue */ 20 rte_sched_port_enqueue(port, pkts_rx, n_pkts_rx); 21 /* Hierarchical scheduler dequeue */ 22 n_pkts_tx = rte_sched_port_dequeue(port, pkts_tx, N_PKTS_TX); 23 /* Write packets to NIC TX queue */ 24 rte_eth_tx_burst(NIC_TX_PORT, NIC_TX_QUEUE, pkts_tx, n_pkts_tx); 25 }
4.实现细节
每个端口的内部数据结构,下面是原理解释图:
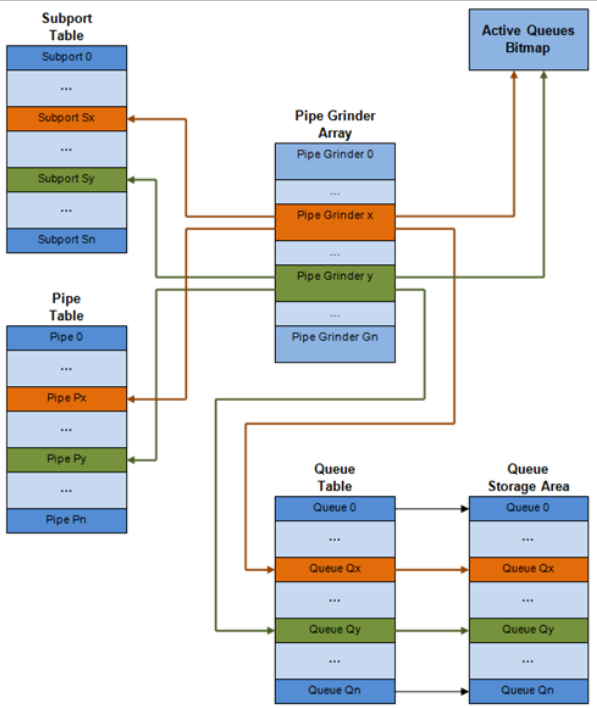
# 数据结构 大小(bytes) #每个端口 入队 出队 功能描述
1 子端口表项 64 #端口的子端口数 . Rd,Wr 子端口的持久化数据(如积分,等等)
2 流水线表项 64 #端口的流水线数 . Rd,Wr 流水线和它的流分类依据队列(积分)(这些会在运行期间被更新)的持久化数据。流水线配置参数在运行期间不支持修改。相同流水线的配置参数会多个流水线共享,所以它们不是流水线表的一部分。
3 队列表项 4 #端口的队列数 Rd,Wr Rd,Wr 队列的持久化数据(比如读写指针)。所有队列的每一个流分类,都是一样的队列大小。任何一个流水线的流水线表项都是存在同一个cache line里。
5.多核扩展策略
(1) 不同的物理端口运行不同的线程。同一个端口的入队和出队在同一个线程里执行。
(2) 不同的线程使用同一个物理端口,通过分隔同一个物理端口(虚拟端口)的不同的子端口集合来运行。同样,一个子端口也能分隔成多个子端口集合,来运行不同的线程,出队和入队都是在同一个端口的同一个线程。唯一的要求是,考虑到性能,不能在一个核里处理全部的端口。
6.在同一个出端口入队和出队
在不同的CPU核上执行同一个出端口入队和出队的操作,会对调度器的性能有显著影响,所以是不推荐这么做。
端口的入队和出队操作由如下的数据结构来共享访问:
(1)报文描述符
(2)队列表
(3)队列存储区域
(4)活动队列的位图(bitmap)
能预料到的性能损耗是由于:
(1)需要保证队列和位图操作是线程安全的,这就需要用锁来保证原子访问(比如自旋锁/信号量)或者使用无锁的原子访问(比如:Test/Set, Compare And Swap(CAS)等等)。这比前面说的情况影响更大。
(2)在2个CPU核的缓存结构(满足缓存一致性)里,双向(Ping-pong)地在高速缓存线(cache line)存放共享数据结构
因此,调度器的入队和出队操作必须在同一个线程里执行,这样队列和位图的操作就没有线程安全的性能损耗以及可以保存调度器数据结构在同一个CPU核上。
7.性能调优
增加网卡端口的数量仅仅只需要成比例的增加用来流量调度的CPU核的数量。
8.入队流水线
每一个报文的步骤顺序是:
(1)mbuf里数据字段的访问要求识别出报文的目的队列。这些字段包括:端口,子端口,流分类和流分类的队列,这些都是分类阶段设置的。
(2)访问队列数据结构要识别出写操作在队列数组中的位置。如果队列是满的,那么这个报文会被丢弃。
(3)访问队列数组存储报文的位置(比如:写mbuf指针)
需要注意的是,这些步骤是有强相关的数据依赖的。比如,第2步和第3步不能在第1步和第2步的返回可用的结果之前启动。这样就阻止了CPU通过乱序执行来显著提高性能的优化行为。
考虑到很高速率的报文接收以及很大数量的队列,可以预料到在当前CPU,对当前报文入队需要访问的数据结构是不在L1,或者L2缓存的,因此会去内存中访问,这样会导致L1和L2数据缓存未命中(cache miss)。大量的L1、L2缓存未命中在性能上肯定是不可接受的。
一个解决方案是通过预先读取需要的数据结构。预取操作有一个执行延迟,数据结构在当前预取的状态时,CPU是不能访问它的,这个时候,CPU可以去执行其他的工作。其他工作是去执行其他报文的入队顺序不同阶段的操作,因此就实现了入队操作的流水线。
下图阐述了流水线4个阶段的入队操作实现,每个阶段执行2个报文。没有那个报文可以在同一时间处于大于一个流水线阶段。

拥塞管理方案通过队列流水线来描述就非常简单了:
报文入队直到特定的队列满了,这时,所有的报文都只能到同一个丢包队列,直到报文被消耗完(通过出队操作),这里可以通过使能RED/WRED来改进队列流水线,通过查看队列的使用情况和特定报文的报文优先级来决定出队或丢弃。(这就与任意的让所有报文都入队/丢弃所有报文不同了。)
9.出队状态机
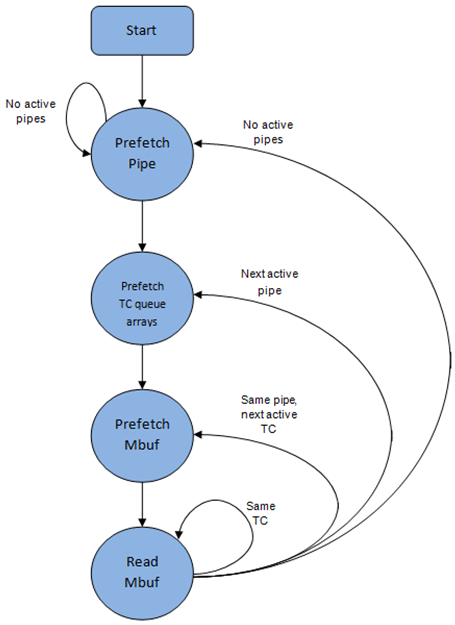
从当前流水线调度下一个报文的步骤顺序是:
(1)使用bitmap扫描识别出下一个活动流水线,预取流水线。
(2)读取流水线数据结构。更新当前流水线和它的子端口的积分。识别当前流水线的第一个活动流分类,通过WRR来选择下一个队列,预取当前流水线的16个队列的队列指针。
(3)从当前WRR队列里读取下一个元素并预取它的报文描述符。
(4)从报文描述符(mbuf数据结构)里读取报文长度。基于报文长度和可用积分(如当前流水线,流水线流分类,子端口和子端口流分类),来执行或不执行调度。
为了避免缓存未命中,上述的数据结构(流水线,队列,队列数组,mbufs)都会在访问之前预取过来。隐藏预取操作的延迟方案是在当前流水线的预取指令发出之后立即从当前流水线(流水线 grinder A)切换到另外一个流水线(grinder B)。这就给了足够的时间在执行权切换回之前的流水线(grinder A)之前来完成预取操作。
出队流水线状态机利用数据在CPU高速缓存里会提高性能的原理,因此,在从同一个流水线的活动流分类移动到另外一个流水线之前,它会尝试从一个流水线和流水线流分类里发送尽可能多的报文(直到最大的可用报文和积分)
10.时钟同步
出端口在调度器调度数据传输的时候就像在模仿一个有很多槽位的传送带装置。对于10GbE,上面有12.5亿个字节槽位需要端口调度器每秒去填充。如果调度器不能够快去填充,那么就有足够的报文和积分继续存在,这样那些槽位就不会被使用,也就浪费了带宽。
原则上,分层调度器出队操作是有网卡TX触发的。通常,一旦网卡Tx输入队列的使用降低到了一个预设的阀值,端口调度器就会被唤醒(基于中断或者基于轮询,通过持续的监视队列的使用率)来将更多的报文加入到队列。
(1)内部时钟参考源
为了提升积分逻辑,调度器需要保持对时钟跟踪,因为积分的更新是基于时钟。举个栗子,子端口和流水线流量整形,流分类强制上限等等。
每当调度器决定发送一个报文给网卡TX的时候,调度器会相应地增加它的内部时钟参考源。因此,以字节为单位保持内部时钟参考源是很方便的,尤其是要求在物理接口的传输介质上发送一个字节来表示时间片的时候。这样,当一个报文被调度到发送的时候,时钟按(n + h)增加,n是报文长度的字节数,h是每个报文的帧前导字节数。
(2)内部时钟参考源再同步
调度器需要调整对齐端口传输带上的内部时钟参考源。原因是为了防止丢包,调度器不能给网卡TX喂大于物理介质线速的字节数。(丢包处理通过调度器,因为网卡TX输入队列满了,或者随后在网卡TX)
调度器读取每一个队列调用的当前时间。CPU 时间戳可以通过读取TSC(Time Stamp Counter)寄存器或者HPET(high precision event timer)寄存器来获取。当前CPU时间戳是从CPU时钟字节数转换而来的,time_bytes = time_cycles/cycles_per_byte.cycles_per_byte是CPU周期数,等于在电缆中传输一个字节的时间。(举个栗子:一个CPU频率为2GHZ和一个10GbE端口,cycles_per_byte = 1.6)。
调度器维护了一个网卡时间的内核时钟参考源。每当一个报文被调度时,网卡时间会按照报文长度(包含帧前导字节数)增加。每一个出队调用时,调度器会检查它的网卡时间的内部参考源,相对于当前时间:
1.如果网卡时间在将来(即:网卡时间 >= 当前时间),不需要调整网卡时间。这意味着调度器有能力在网卡实际需要多少报文时去调度网卡上的报文,因此网卡TX可以很多出路这些报文;
2.如果网卡时间在过去(即:网卡时间 < 当前时间),那么网卡时间应该调整到当前时间,这意味着调度器不能保持网卡字节传输带上的速度,因此网卡带宽会因为网卡TX处理较少报文而浪费。
(3)调度器的精度(accuracy)和粒度(granularity)
调度器的往返延迟(SRTD)是通过调度器在同一个流水线上的两个连续检测的时间(CPU周期的数量)。为了充分利用输出端口(就是避免带宽损失),调度器应该有能力在调度n个报文的速度上比网卡TX发送n个报文的速度要快。在假设流水线令牌桶没有配置超额的情况下,调度器要跟得上每个独立的流水线的速度。这意味着令牌桶的大小应该设置的足够大才能防止因为过大的往返延迟(SRTD)溢出,因为这样的话,会导致流水线的积分损失和带宽损失。
11.积分规则(logic)
(1)调度决策
当下面全部条件都满足时,发送下一个报文(从子端口S,流水线P,流分类TC,队列Q)到报文发送完成的调度决策是最佳的:
1.子端口S的流水线P是从当前端口(grinders)选择的
2.流分类TC是流水线P活动的流分类里优先级最高的
3.队列Q是流水线P的流分类TC里通过WRR选择的下一个队列
4.子端口S有足够的积分去发送这个报文
5.子端口S有足够的积分给流分类TC来发送这个报文
6.流水线P有足够的积分去发送这个报文
7.流水线P有足够的积分给流分类TC来发送这个报文
如果上述条件都满足了,那么在子端口S,子端口S的流分类TC,流水线P,流水线P的流分类TC上要发送的报文和需要积分就会被扣除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号