数据采集——第六次作业
作业一:
要求:
用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
每部电影的图片,采用多线程的方法爬取,图片名字为电影名
了解正则的使用方法
候选网站:豆瓣电影:https://movie.douban.com/top250
输出信息:

1)作业结果
代码:
import threading
import urllib
import requests
from bs4 import BeautifulSoup
import re
'''
多线程爬取豆瓣电影top250
'''
class ConsumerThread(threading.Thread):
def __init__(self, startUrl, headers, startNum, endNum):
threading.Thread.__init__(self)
self.startUrl = startUrl
self.headers = headers
self.startNum = startNum
self.endNum = endNum
def run(self):
for page in range(self.startNum, self.endNum + 25, 25):
lst =[]
html = request_page(self.startUrl + str(page), self.headers)
# res.encoding = 'utf-8'
# print("这是html")
# print(html)
try:
# 调用bs4库里的BeautifulSoup类的方法,利用BeautifulSoup的html.parser解析网页
soup = BeautifulSoup(html, "html.parser")
div = soup.find_all('div', attrs={'class': 'item'})
for i in div:
# name = i.find_all('span') 下边为简写写法
name = i('span', attrs={'class': 'title'})
# 开始对'导演演员'进行处理
dir = str(i('p', attrs={'class': ''})).replace(' ', '').replace('\n', '').split(' ')
dir = str(dir).strip('[\'[<pclass="">导演:</p>]\']')
# print(dir)
dir1 = dir.split('\\xa0\\xa0\\xa0')
director = dir1[0] # 导演
# print(director)
try:
dir2 = dir1[1].strip('主演:').split('<br/>')
main_actor = dir2[0]
except:
main_actor = ' '
dir3 = dir2[1].split('\\xa0/\\xa0')
pbyear = dir3[0]
country = dir3[1]
moivetype = dir3[2]
#print(dir3[0], dir3[1], dir3[2])
# 评分
score = i('span', attrs={'class': 'rating_num'})
#print(score)
# 评价人数
comment1 = i('div', attrs={'class': 'star'})
comment = re.findall(r'\d+', str(comment1))[5]
# print(comment)
# 引用
try:
quote = i('span', attrs={'class': 'inq'})[0].string
# print(quote[0].string)
except Exception:
quote = " "
# 电影链接
href = i('a')
#print(href)
# 将href从bs4.element.ResultSet类型转换为str类型
for h in href:
lst.append(str(h))
# 此时"".join(lst)即为href的str类型
soup1 = BeautifulSoup("".join(lst), "html.parser")
# Href即为得到电影的链接
Href = soup1.a.attrs['href']
# 图片链接
pic = i('a')[0]
pic = pic('img')[0]['src']
# print(pic)
# 清空lst列表
lst.clear()
# 将数据存入列表中
download(self, pic, name[0].string)
if (pic[len(pic) - 4] == "."):
ext = pic[len(pic) - 4:]
else:
ext = ""
list.append([name[0].string, director, main_actor, pbyear, country, moivetype, score[0].string, comment, quote, Href, name[0].string+ext])
except:
print("解析出错", name[0].string)
def request_page(startUrl, headers):
try:
r = requests.get(startUrl, headers=headers, timeout=20)
r.raise_for_status()
# 分析得到网页的编码格式
r.encoding = r.apparent_encoding
return r.text
except:
return "error"
def get_headers():
headers = {
'cookie': 'miid=871473411901751759; tk_trace=oTRxOWSBNwn9dPyorMJE%2FoPdY8zfvmw%2Fq5v3gzlT6TfC88%2B8VsR2LZeh0x0uZ2lavUunwk7FaQvkKtSF8tQ1fLpJrqsz14B%2FyobMQW8Exzoggkl4YwBJKriMzZBFIh%2FIQKv1FPsNnhV6P2HnGBVjbylCyWiAFwW1fvt3aOBQ3uoAwtp6Of66wJHZ8YPC4wCiq2449kBKT6ufwkDkOEQ0bb3%2BTywKDqprZHDdiDO7zqxULUBvZcPasjtJ6gwye5pjKqluzqIlGZw5KubUzluZEGHyoRYm; lLtC1_=1; t=da76da827c8812bfc2ef4d091ab75358; v=0; _tb_token_=3f7e30eaede6e; _m_h5_tk=55efe72e4a7e4752c144c9d9a52250c0_1600601808838; _m_h5_tk_enc=480b7ec5d4482475e3f5f76e0f27d20f; cna=ZgXuFztWFlECAdpqkRhAo4LI; xlly_s=1; _samesite_flag_=true; cookie2=13aa06fa1e7317d5023153e70e45e95f; sgcookie=E100jT6nEM5pUv7ZaP1urbIUwS5ucPPcz2pG%2FHs9VDYB91E14tzvEV8mMtRfZtLe4dg8rBjdN9PEuYVfhzjqARIFKQ%3D%3D; unb=2341324810; uc3=id2=UUtP%2BSf9IoxzEQ%3D%3D&nk2=t2JNBkErCYOaTw%3D%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dCufeJMlcWOvLCctE%3D; csg=6e737d42; lgc=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; cookie17=UUtP%2BSf9IoxzEQ%3D%3D; dnk=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; skt=d79995fc094af782; existShop=MTYwMDU5MTk1Ng%3D%3D; uc4=id4=0%40U2l1DTh9%2F%2BK9Ym%2BCcxbZCceodFVg&nk4=0%40tRGCEUSTUyhwCCuPpi69tV6rFUkp; tracknick=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; _cc_=W5iHLLyFfA%3D%3D; _l_g_=Ug%3D%3D; sg=%E6%89%8B09; _nk_=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; cookie1=AVdDOYh1aRzl%2BX23%2BL5DKrLq3hm6%2F%2BaYgNDVsRdW80M%3D; enc=Amz2MhdAq1awG9cmHzc5MLNi%2Bing6y4cR5EbHVPlJhWJxNKvr0B40mznTsnKW0JcubOujE6qhizMA84u7mBq2Q%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; mt=ci=85_1; uc1=existShop=false&cookie16=WqG3DMC9UpAPBHGz5QBErFxlCA%3D%3D&cookie14=Uoe0bU1NOIsDOA%3D%3D&cookie21=WqG3DMC9Fb5mPLIQo9kR&pas=0&cookie15=UIHiLt3xD8xYTw%3D%3D; thw=cn; JSESSIONID=6ECE41F4DC42E868790A52C0B362FD3C; isg=BNTUg0Kud-Dz7-OsCcrIFwHdpRJGLfgXLSfdwW61YN_iWXSjlj3Ip4rbWVFBujBv; l=eBgY5g8rOF5Pi0CSBOfanurza77OSIRYYuPzaNbMiOCP9b1B5N21WZru8mY6C3GVh60WR3rZpo7BBeYBqQAonxv92j-la_kmn; tfstk=cyJcBsT6YI5jdt1kOx6XAqHF5iMdwE3VudJvULmsgZ-4urfcF7PEePnlzEvT1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'
}
return headers
def printList(list,num):
print("排名", '\t', "电影名", '\t',"导演",'\t', "主演", '\t',"上映时间",'\t', "国家", '\t',"电影类型", '\t',"评分", '\t',"评价人数", '\t',"引用",'\t', "电影链接",'\t', "图片链接")
count = 0
# 输出的格式
for i in range(num):
count = count + 1
lst = list[i]
print(count, '\t',lst[0],'\t', lst[1],'\t', lst[2],'\t', lst[3], '\t', lst[4], '\t', lst[5],'\t', lst[6], '\t', lst[7],'\t', lst[8],'\t', lst[9],'\t',lst[10])
def download(self, url, movieName):
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("./image/" + movieName + ext, "wb")
fobj.write(data)
fobj.close()
if __name__ == '__main__':
url = 'https://movie.douban.com/top250?start='
list = []
header = get_headers()
thread1 = ConsumerThread(url, header, 0, 100)
thread2 = ConsumerThread(url, header, 125, 225)
thread1.start()
thread1.join()
thread2.start()
thread2.join()
printList(list, 250)
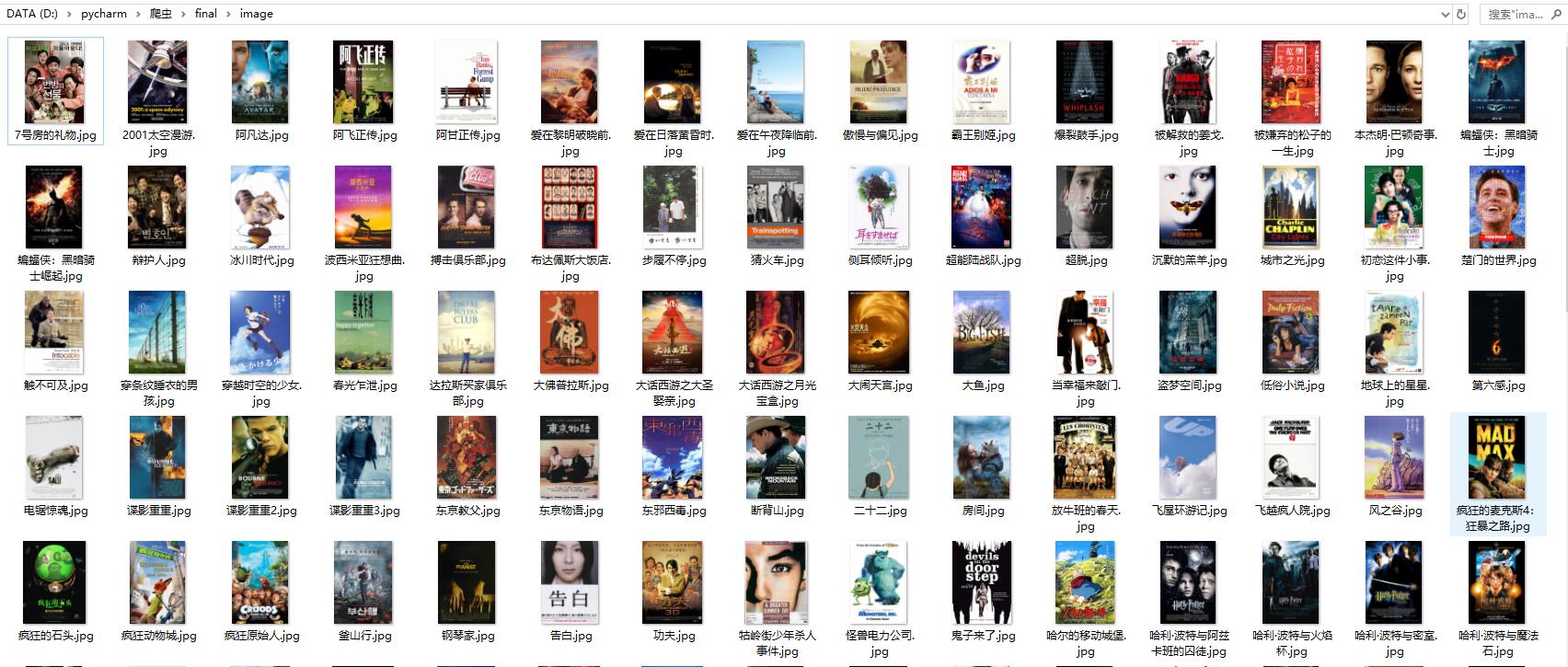
结果贴图
结果输出

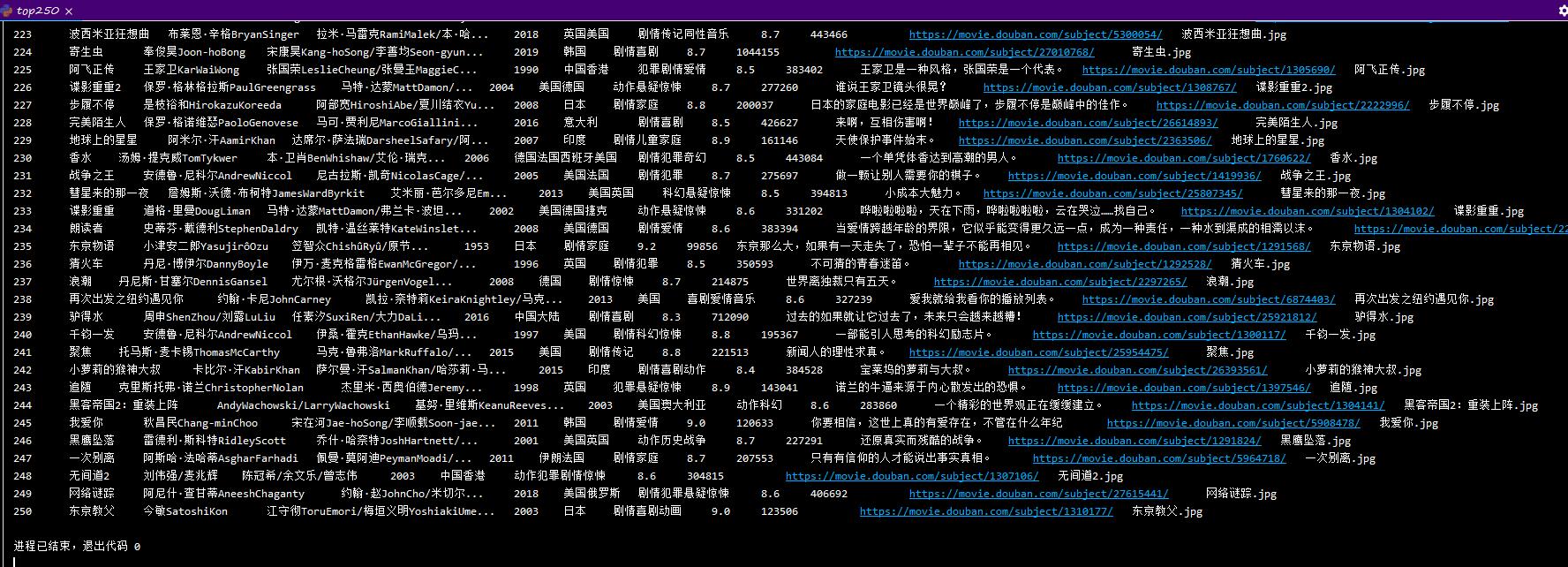
电影封面
2)心得体会
这次的多线程采用了前一半和后一半使用两个线程进行爬取
大体上结构以及下载图片都可以仿照以前的作业
但是在内容爬取上,不好搞哇,折腾了半天
在爬取时会有几部电影的结构不符合自己写的爬取思路,反复修改
最后没有在纠结输出格式了,有一些乱
作业二:
要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
候选网站:https://www.shanghairanking.cn/rankings/bcur/2020
关键词:学生自由选择
输出信息:MYSQL的输出信息如下

1)作业结果
代码:
rank
import scrapy
from bs4 import UnicodeDammit
import urllib.request
from ..items import RankingItem
class RankSpider(scrapy.Spider):
name = 'rank'
start_urls = 'https://www.shanghairanking.cn/rankings/bcur/2020'
def start_requests(self):
url = RankSpider.start_urls
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
try:
dammit = UnicodeDammit(response.body, ["utf-8", "gbk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//div[@id='content-box']/div[2]/table/tbody/tr")
for li in lis:
try:
num = li.xpath("./td[position()=1]/text()").extract_first()
# print(num)
schoolname = li.xpath("./td[@class='align-left']/a/text()").extract_first()
# print(schoolname)
city = li.xpath("./td[position()=3]/text()").extract_first()
# print(city)
page_URL = li.xpath("././td[@class='align-left']/a/@href").extract_first()
# print(page_URL)
school_page_URL = 'https://www.shanghairanking.cn'+page_URL
# 链接学校
html = urllib.request.urlopen(school_page_URL)
html = html.read()
dammit = UnicodeDammit(html, ["utf-8", "gbk"])
data2 = dammit.unicode_markup
selector2 = scrapy.Selector(text=data2)
schoolinfo = selector2.xpath("//div[@class='univ-introduce']/p/text()").extract_first()
# print(schoolinfo)
officalURL = selector2.xpath("//div[@class='univ-website']/a/@href").extract_first()
# print(officalURL)
mfile = selector2.xpath("//td[@class='univ-logo']/img/@src").extract_first()
# print(mfile)
self.download(mfile, schoolname)
item = RankingItem()
item["num"] = num.strip() if num else ""
item["schoolname"] = schoolname.strip() if schoolname else ""
item["city"] = city.strip() if city else ""
item["officalURL"] = officalURL.strip() if officalURL else ""
item["schoolinfo"] = schoolinfo.strip() if schoolinfo else ""
item["mfile"] = mfile.strip() if mfile else ""
yield item
except:
print("不存在该大学信息\n")
except Exception as err:
print(err)
def download(self, url, schoolname):
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
data = urllib.request.urlopen(url, timeout=100)
data = data.read()
fobj = open("D:\\pycharm\\爬虫\\final\\image_school_logo\\" + schoolname + ext, "wb")
fobj.write(data)
fobj.close()
piplines
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import pymysql
class RankingPipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="gh02120425", db="gc2",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from ranking")
self.opened = True
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
def process_item(self, item, spider):
try:
print(item["num"])
print(item["schoolname"])
print(item["city"])
print(item["officalURL"])
print(item["schoolinfo"])
print(item["mfile"])
print('\n')
if self.opened:
self.cursor.execute(
"insert into ranking (n, school_name, school_city, school_officalURL, schoolinfo, mfile) values (%s,%s,%s,%s,%s,%s)",
(item['num'], item['schoolname'], item['city'], item['officalURL'], item['schoolinfo'],
item['mfile']))
except Exception as err:
print(err)
return item
items
import scrapy
class DownimageItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_url = scrapy.Field()
file_name = scrapy.Field()
title = scrapy.Field()
settings
ITEM_PIPELINES = {
'ranking.pipelines.RankingPipeline': 300,
}
结果贴图
结果输出
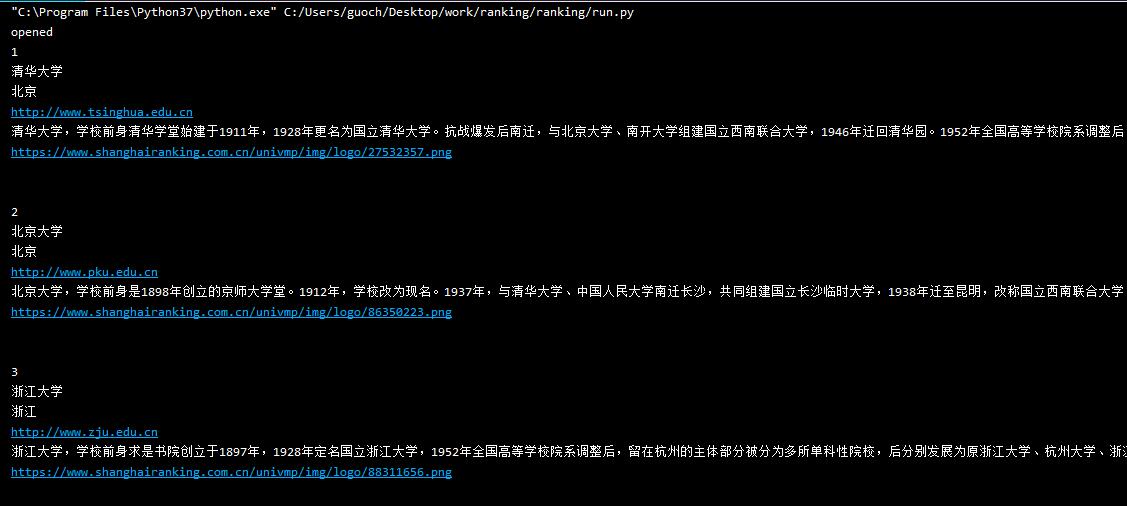
数据库
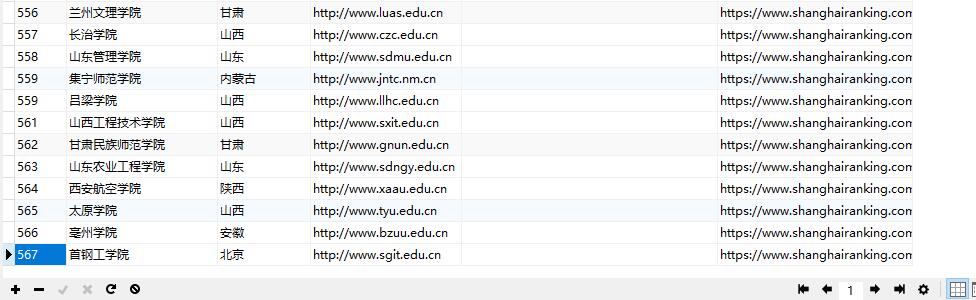
logo集

2)心得体会
这道题就好很多了!
xpath还是好用啊,scrapy框架也是仿照之前的作业
唯一就是爬着爬着突然报错,后来发现是有一个学校连接error,maybe是没有了叭hhhh
作业三:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
其中模拟登录账号环节需要录制gif图。
候选网站: 中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式如下

1)作业结果
代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
import pymysql
import pandas as pd
import time
import datetime
class MOOC:
header = {
"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072531 Minefield/3.0.2pre"
}
def startUp(self, url):
chrome_options = Options()
chrome_options.add_argument("——headless")
chrome_options.add_argument("——disable-gpu")
self.driver = webdriver.Chrome(options=chrome_options)
try:
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd='gh02120425',
db="gc2", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from mooc")
self.opened = True
except Exception as err:
print(err)
self.opened = False
self.driver.get(url)
time.sleep(2.0)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
self.opened = False
except Exception as err:
print(err)
def showMOOC(self):
try:
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd='gh02120425', db="gc2",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.opened = True
sqlcmd = "select * from mooc"
a = pd.read_sql(sqlcmd, self.con)
print(a)
self.opened = False
except Exception as err:
print("出错,无法打印")
print(err)
def gif(self):
# 一系列点击到手机号密码登陆界面
time.sleep(0.5)
self.driver.find_element_by_xpath("//div[@class='_3uWA6']").click()
time.sleep(0.5)
self.driver.find_element_by_xpath("//span[@class='ux-login-set-scan-code_ft_back']").click()
time.sleep(0.5)
self.driver.find_element_by_xpath("//ul[@class='ux-tabs-underline_hd']/li[2]").click()
time.sleep(1.0)
# 手机号密码的方式登录慕课网
self.driver.switch_to.frame(1)
self.driver.find_element_by_xpath("//input[@placeholder='请输入手机号']").clear() # 找到手机号的框框
self.driver.find_element_by_xpath("//input[@placeholder='请输入手机号']").send_keys("13123186121")
time.sleep(1.0)
print('ok1')
self.driver.find_element_by_xpath("//input[@placeholder='请输入密码']").clear() # 找到输入密码的框框
self.driver.find_element_by_xpath("//input[@placeholder='请输入密码']").send_keys("gh02120425")
time.sleep(1.0)
print('ok2')
self.driver.find_element_by_xpath("//a[@class='u-loginbtn btncolor tabfocus ']").click()
print('ok3')
time.sleep(2.0)
def processMOOC(self):
time.sleep(2)
try:
self.driver.find_element_by_xpath("//div[@class='_3uWA6']").click()
self.driver.get(self.driver.current_url) # 获取当前页面
time.sleep(1.0)
lis = self.driver.find_elements_by_xpath("//div[@class='course-panel-body-wrapper']//div[@class='course-card-wrapper']")
gId = 0
for li in lis:
li.find_element_by_xpath(".//div[@class='box']").click()
now_window = self.driver.window_handles[-1]
self.driver.switch_to.window(now_window)
time.sleep(2.0)
self.driver.find_element_by_xpath("//div[@class='f-fl info']//a").click()
last_now_window = self.driver.window_handles[-1]
self.driver.switch_to.window(last_now_window)
time.sleep(2.0)
gId = gId + 1
gCourse = self.driver.find_element_by_xpath("//span[@class='course-title f-ib f-vam']").text
print(gCourse)
gCollege = self.driver.find_element_by_xpath("//div[@class='m-teachers']//a").get_attribute("data-label")
print(gCollege)
gTeacher = self.driver.find_element_by_xpath("//div[@class='cnt f-fl']//h3[@class='f-fc3']").text
print(gTeacher)
gT = self.driver.find_elements_by_xpath("//div[@class='cnt f-fl']//h3[@class='f-fc3']")
try:
gTeam = gT[0].text
for i in range(len(gT)):
if i > 0:
gTeam = gTeam + "," + gT[i].text
except Exception as err:
print(err)
print(gTeam)
gCount = self.driver.find_element_by_xpath("//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text
print(gCount)
gProcess = self.driver.find_element_by_xpath("//div[@class='course-enroll-info_course-info_term-info_term-time']//span[2]").text
print(gProcess)
gBrief = self.driver.find_element_by_xpath("//div[@class='course-heading-intro_intro']").text
print(gBrief)
self.cursor.execute(
"insert into mooc(gId,gCourse,gCollege,gTeacher,gTeam,gCount,gProcess,gBrief)"
"values (%s, %s, %s, %s, %s, %s, %s, %s)",
(gId, gCourse, gCollege, gTeacher, gTeam, gCount, gProcess, gBrief))
self.driver.close()
self.driver.switch_to.window(self.driver.window_handles[0])
except Exception as err:
print(err)
def executeMOOC(self, url):
starttime = datetime.datetime.now()
print("starting!")
self.startUp(url)
self.gif()
print("processing!")
self.processMOOC()
print("closing!")
self.closeUp()
print("complete!")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total", elapsed, "seconds elasped")
url = "https://www.icourse163.org/"
spider = MOOC()
while True:
print("1.登陆并爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3);")
if s == "1":
MOOC().executeMOOC(url)
continue
elif s == "2":
MOOC().showMOOC()
continue
elif s == "3":
break
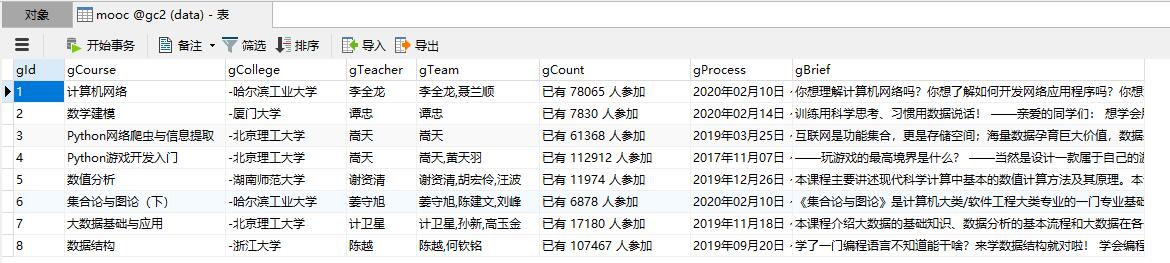
结果贴图
结果输出


数据库
gif
2)心得体会
使用了上次的selenium框架,我觉得注意的点在于是否产生新页面,产生要定位到最后一个页面才能成功爬取
以及课程详情爬取完成后要关闭详情页,再跳转到第一个页面
在爬取时,Google会弹出一个data页面,后来百度是因为Google版本与webdriver版本不一致,那只能让程序多sleep一会儿,我手动×掉了hhh
后来发现下载了对应版本发现还是会出现,可能还有其他问题叭


 浙公网安备 33010602011771号
浙公网安备 33010602011771号