数据采集——第三次作业
作业1
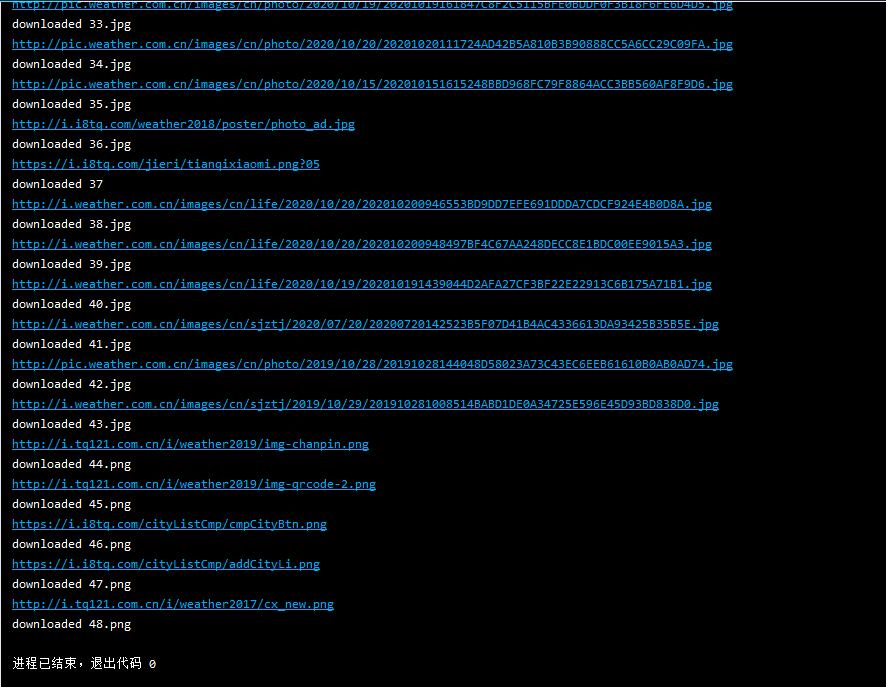
1)采用单线程及多线程爬取图片
代码
单线程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
def imageSpider(start_url):
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
images=soup.select("img")
for image in images:
try:
src=image["src"]
url=urllib.request.urljoin(start_url,src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err: print(err)
except Exception as err:
print(err)
def download(url):
global count
try:
count=count+1
#提取文件后缀扩展名
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("D:\\images\\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded "+str(count)+ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/weather/101280601.shtml"
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count=0
imageSpider(start_url)
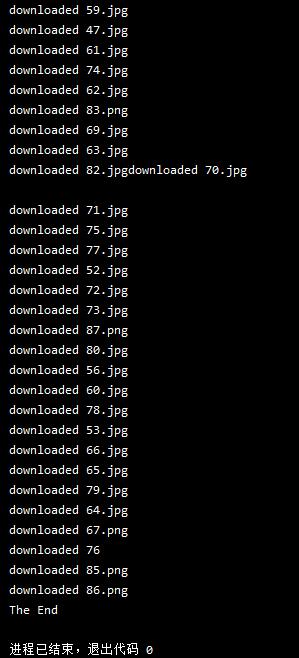
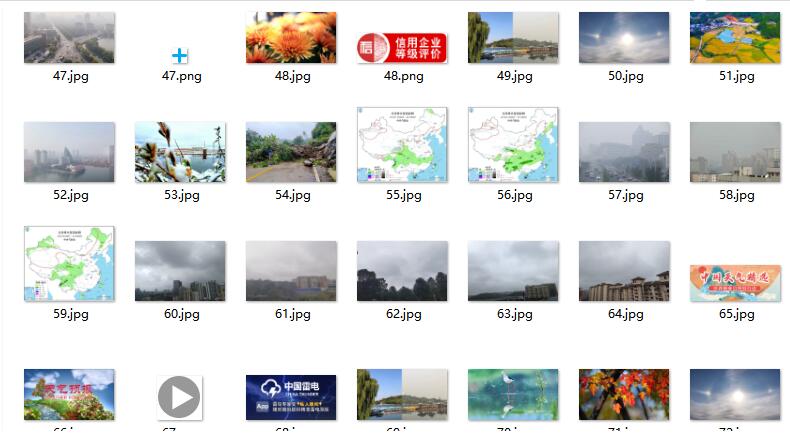
多线程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
def imageSpider(start_url):
global threads
global count
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
images=soup.select("img")
for image in images:
try:
src=image["src"]
url=urllib.request.urljoin(start_url,src)
if url not in urls:
print(url)
count=count+1
T=threading.Thread(target=download,args=(url,count))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url,count):
try:
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("D:\\images\\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded "+str(count)+ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/weather/101280601.shtml"
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre)Gecko/2008072421 Minefield/3.0.2pre"}
count=0
threads=[]
imageSpider(start_url)
for t in threads:
t.join()
print("The End")
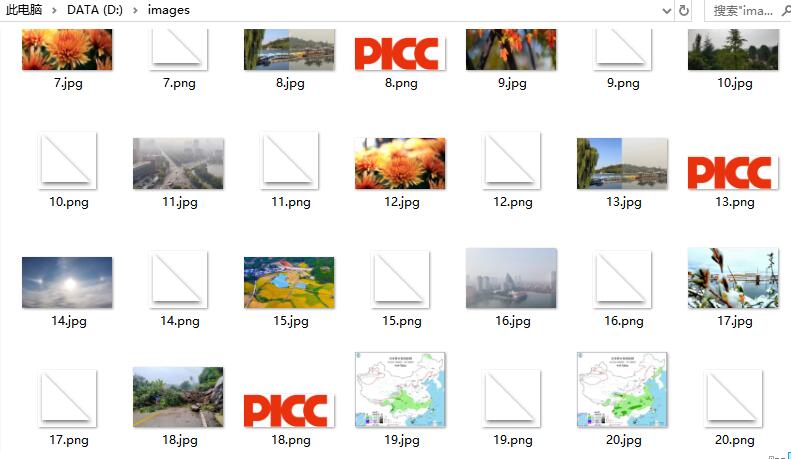
结果贴图
单线程
多线程:
心得体会
参考书上的代码进行复现,明白了单线程与多线程的意思
感觉多线程是比单线程快一丢丢喔(量不大感受不明显hhh)
作业2
1)采用scrapy框架爬取图片
没有复现第一个作业的网站,搞了一个图片网的图片集5555
代码
spider.py(我写的是down.py)
# -*- coding: utf-8 -*-
import scrapy
from downimage.items import DownimageItem
class DownSpider(scrapy.Spider):
name = 'down'
allowed_domains = ['win4000.com']
start_urls = ['http://www.win4000.com/meinv163506.html']
index = 1
def parse(self, response):
page = response.xpath("//*[@class='ptitle']/span/text()").extract()[0] # 获取图片当前页数
total = response.xpath("//*[@class='ptitle']/em/text()").extract()[0] # 获取一个图片集总共多少张
print("总共多少张:"+total)
item = DownimageItem()
item['image_url'] = response.xpath("//*[@class='pic-large']/@url").extract()[0] #获取url
item['title'] = response.xpath("//*[@class='ptitle']/h1/text()").extract()[0] #获取图片标题,存取
# print(item['title'])
item['file_name'] = page
print("page是:"+item['file_name'])
yield item
#如果当前页数小于总的张数,继续翻页
if page < total:
next_page_url = response.xpath("//*[@class='pic-meinv']/a/@href").extract()[0] #下一张图片的网址
yield scrapy.Request(next_page_url,callback=self.parse)
items.py
import scrapy
class DownimageItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_url = scrapy.Field()
file_name = scrapy.Field()
title = scrapy.Field()
piplines.py
from itemadapter import ItemAdapter
import requests
import os
class DownimagePipeline(object):
def process_item(self, item, spider):
headers = {
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36',
}
dir_path = r"D:\2020test\cat\{}".format(item['title'])
if not os.path.exists(dir_path):
os.mkdir(path=dir_path)
file_path = dir_path + "\{}.jpg".format(item['file_name'])
url = item['image_url']
# 用request来获得图片
response = requests.get(url, headers=headers, timeout=10)
if response.status_code == 200:
image = response.content
with open(file_path, 'wb') as f:
f.write(image)
f.close()
return item
settings.py
ITEM_PIPELINES = {
'downimage.pipelines.DownimagePipeline': 300,
}
结果贴图

2)心得体会
从刚开始做一脸懵到可以自己尝试修改编写代码爬取结果,感觉还是不错哒
为什么感觉scrapy框架更难写一点
就是记错题目了555跟第一题爬取的不是同一个网站
补充!!!!
正常爬取天气网!!!
代码:(参考单线程)
pic.py
class PicSpider(scrapy.Spider):
name = 'pic'
allowed_domains = ['weather.com']
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
url = response.xpath('//body//div//img/@src') # 定位
for u in url.extract(): # 解析
item = WPicItem()
item["url"] = u
print(u)
yield item
print("031804113")
piplines.py
class WPicPipeline: # 使用单线程的算法进行修改
count = 0
def process_item(self, item, spider):
WPicPipeline.count += 1
#提取文件后缀扩展名
url = item["url"]
if(url[len(url)-4]=="."):
ext = url[len(url)-4:]
else:
ext = ""
req = urllib.request.Request(url)
data = urllib.request.urlopen(req)
data = data.read()
fobj = open("D:\\images\\"+str(WPicPipeline.count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded "+str(WPicPipeline.count)+ext)
return item
items.py
class WPicItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
pass
setting.py
ITEM_PIPELINES = {
'W_pic.pipelines.WPicPipeline': 300,
}
结果贴图


赶上了555555
作业3
1)用scrapy爬取股票信息
代码
spider.py(我写的是stocks)
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = 'stocks'
start_urls = ['https://hq.gucheng.com/gpdmylb.html']
def parse(self, response):
# 循环获取列表中a标签的链接信息
for href in response.css('a::attr(href)').extract():
try:
print("是啥:"+href)
# 通过正则表达式获取链接中想要的信息
stock = re.findall(r"[S][HZ]\d{6}", href)[0]
print("是stock:"+stock)
# 生成百度股票对应的链接信息
url = 'http://gu.qq.com/' + stock + '/gp'
print("是网址"+url)
# yield是生成器
# 将新的URL重新提交到scrapy框架
# callback给出了处理这个响应的处理函数为parse_stock
yield scrapy.Request(url, callback=self.parse_stock)
except:
continue
# 定义单个页面中提取信息的方法
def parse_stock(self, response):
# 因为每个页面返回 的是一个字典类型,所以定义一个空字典
infoDict = {}
stockName = response.css('.title_bg')
# print(stockName)
stockInfo = response.css('.col-2.fr')
# print(stockInfo)
name = stockName.css('.col-1-1').extract()[0]
# print(name)
code = stockName.css('.col-1-2').extract()[0]
# print(code)
info = stockInfo.css('li').extract()
# 将提取的信息保存到字典中
for i in info[:13]:
key = re.findall('>.*?<', i)[1][1:-1]
key = key.replace('\u2003', '')
key = key.replace('\xa0', '')
try:
val = re.findall('>.*?<', i)[3][1:-1]
except:
val = '--'
infoDict[key] = val
# 对股票的名称进行更新
infoDict.update({'股票名称': re.findall('\>.*\<', name)[0][1:-1] + \
re.findall('\>.*\<', code)[0][1:-1]})
yield infoDict
piplines.py
class BaidustocksInfoPipeline(object):
def process_item(self, item, spider):
return item
class BaidustocksInfoPipeline(object):
# 当爬虫被调用时
def open_spider(self, spider):
self.f = open('gupiao.txt', 'w')
# 当爬虫关闭时
def close_spider(self, spider):
self.f.close()
# 对每一个item处理时
def process_item(self, item, spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item
settings.py
ITEM_PIPELINES = {
'BaiduStocks.pipelines.BaidustocksInfoPipeline': 300,
}
items没做修改
结果贴图
这个贴图是https://hq.gucheng.com/gpdmylb.html股票网站爬虫结果
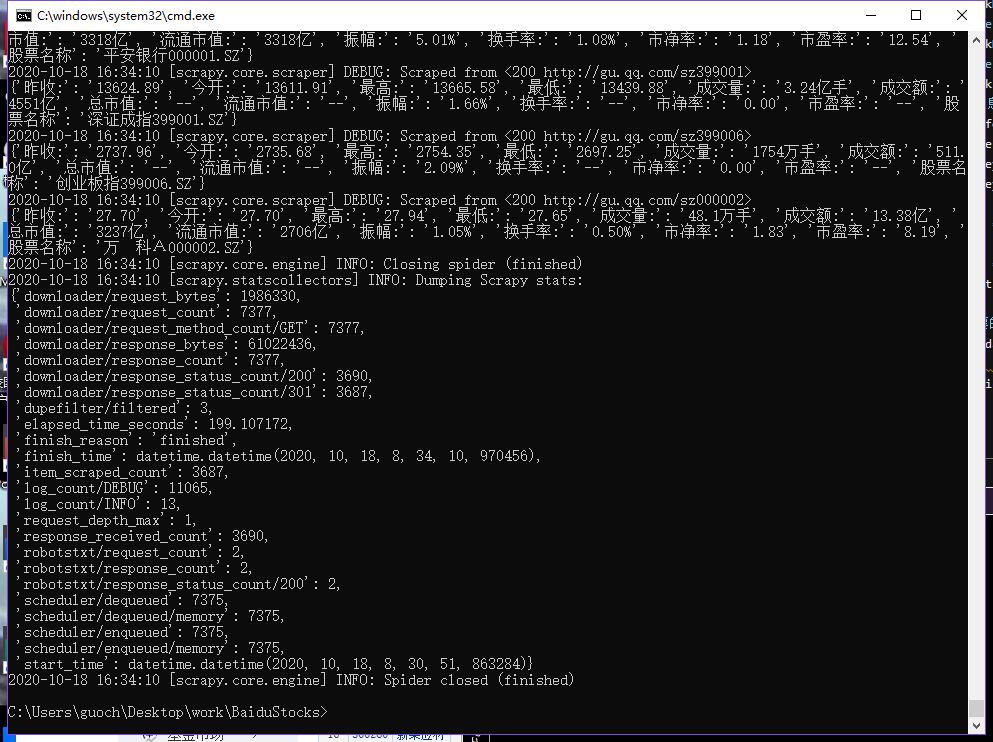
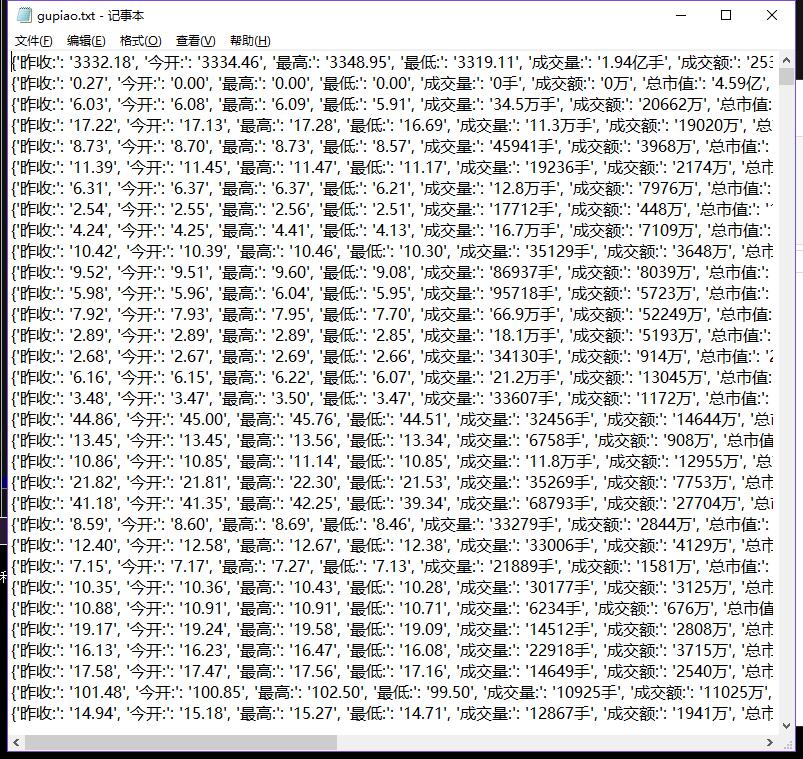
2)心得体会
爬取股票网站确实是会麻烦很多,一步一步筛选需要的信息
感觉还是不太会啊
选择了一个新的股票网站,感觉差别还不小

 浙公网安备 33010602011771号
浙公网安备 33010602011771号