数据采集——第二次作业
作业1
1)在中国气象网上爬取某城市的7日天气预报
代码
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
url="http://www.weather.com.cn/weather/101040100.shtml"
try:
headers={"User-Agent":"Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
# UnicodeDammit 是BS内置库, 主要用来猜测文档编码.
# 编码自动检测 功能也可以在Beautiful Soup以外使用,检测某段未知编码时,可以使用这个方法
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
lis=soup.select("ul[class='t clearfix'] li")
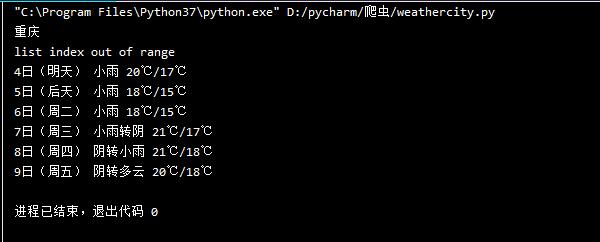
print("重庆")
for li in lis:
try:
date=li.select('h1')[0].text # 获取日期
weather=li.select('p[class="wea"]')[0].text # 获取天气情况
temp=li.select('p[class="tem"] span')[0].text+"/"+li.select('p[class="tem"] i')[0].text # 获取具体温度
print(date,weather,temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
结果图片
2)在中国气象网上爬取城市集的7日天气预报
代码
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)",
(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date=li.select('h1')[0].text
weather=li.select('p[class="wea"]')[0].text
temp=li.select('p[class="tem"] span')[0].text+"/"+li.select('p[class="tem"] i')[0].text
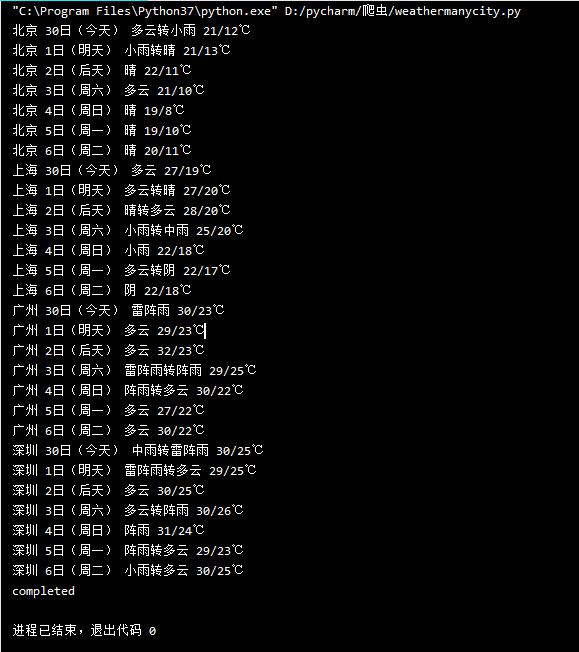
print(city,date,weather,temp)
self.db.insert(city,date,weather,temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
# self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
print("completed")
结果图片
3)心得体会
通过开发人员工具层层检索找到想要的标签,再进行爬取,整个爬取过程比较常规,
在爬取城市集时的处理用字典对爬取城市进行更改
复现书上的代码,特别之处在于代码中使用了UnicodeDammit,感觉还是蛮有用的
作业2
1)用requests和BeautifulSoup库方法定向爬取股票相关信息
通过抓包和分析js文件,获得想要爬取的信息
第一个不同:
在查找并实现时,使用哪种浏览器,就对代码的复杂程度产生影响
在最开始使用火狐浏览器时,要查询的股票信息它的js文件是这样子的:

它的数据通过字典f**来保存,这样子直接提取的正则表达式就会麻烦许多(在作业3中获取学号结尾的股票的js文件相似)
而谷歌的js文件就相对明朗了:

第二个不同:
在获取不同股票的信息时,谷歌浏览器的网址在对不同的股票中有可以区分的明显标志:

而在火狐中没有这样的标志,只能靠最后的编号进行区分:

所以还是谷歌叭
代码
import pandas as pd
#用get方法访问服务器并提取页面数据
def getHtml(cmd,page):
header = {
'cookie': 'miid=871473411901751759; tk_trace=oTRxOWSBNwn9dPyorMJE%2FoPdY8zfvmw%2Fq5v3gzlT6TfC88%2B8VsR2LZeh0x0uZ2lavUunwk7FaQvkKtSF8tQ1fLpJrqsz14B%2FyobMQW8Exzoggkl4YwBJKriMzZBFIh%2FIQKv1FPsNnhV6P2HnGBVjbylCyWiAFwW1fvt3aOBQ3uoAwtp6Of66wJHZ8YPC4wCiq2449kBKT6ufwkDkOEQ0bb3%2BTywKDqprZHDdiDO7zqxULUBvZcPasjtJ6gwye5pjKqluzqIlGZw5KubUzluZEGHyoRYm; lLtC1_=1; t=da76da827c8812bfc2ef4d091ab75358; v=0; _tb_token_=3f7e30eaede6e; _m_h5_tk=55efe72e4a7e4752c144c9d9a52250c0_1600601808838; _m_h5_tk_enc=480b7ec5d4482475e3f5f76e0f27d20f; cna=ZgXuFztWFlECAdpqkRhAo4LI; xlly_s=1; _samesite_flag_=true; cookie2=13aa06fa1e7317d5023153e70e45e95f; sgcookie=E100jT6nEM5pUv7ZaP1urbIUwS5ucPPcz2pG%2FHs9VDYB91E14tzvEV8mMtRfZtLe4dg8rBjdN9PEuYVfhzjqARIFKQ%3D%3D; unb=2341324810; uc3=id2=UUtP%2BSf9IoxzEQ%3D%3D&nk2=t2JNBkErCYOaTw%3D%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dCufeJMlcWOvLCctE%3D; csg=6e737d42; lgc=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; cookie17=UUtP%2BSf9IoxzEQ%3D%3D; dnk=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; skt=d79995fc094af782; existShop=MTYwMDU5MTk1Ng%3D%3D; uc4=id4=0%40U2l1DTh9%2F%2BK9Ym%2BCcxbZCceodFVg&nk4=0%40tRGCEUSTUyhwCCuPpi69tV6rFUkp; tracknick=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; _cc_=W5iHLLyFfA%3D%3D; _l_g_=Ug%3D%3D; sg=%E6%89%8B09; _nk_=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; cookie1=AVdDOYh1aRzl%2BX23%2BL5DKrLq3hm6%2F%2BaYgNDVsRdW80M%3D; enc=Amz2MhdAq1awG9cmHzc5MLNi%2Bing6y4cR5EbHVPlJhWJxNKvr0B40mznTsnKW0JcubOujE6qhizMA84u7mBq2Q%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; mt=ci=85_1; uc1=existShop=false&cookie16=WqG3DMC9UpAPBHGz5QBErFxlCA%3D%3D&cookie14=Uoe0bU1NOIsDOA%3D%3D&cookie21=WqG3DMC9Fb5mPLIQo9kR&pas=0&cookie15=UIHiLt3xD8xYTw%3D%3D; thw=cn; JSESSIONID=6ECE41F4DC42E868790A52C0B362FD3C; isg=BNTUg0Kud-Dz7-OsCcrIFwHdpRJGLfgXLSfdwW61YN_iWXSjlj3Ip4rbWVFBujBv; l=eBgY5g8rOF5Pi0CSBOfanurza77OSIRYYuPzaNbMiOCP9b1B5N21WZru8mY6C3GVh60WR3rZpo7BBeYBqQAonxv92j-la_kmn; tfstk=cyJcBsT6YI5jdt1kOx6XAqHF5iMdwE3VudJvULmsgZ-4urfcF7PEePnlzEvT1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}
url = "http://nufm.dfcfw.com/EM_Finance2014NumericApplication/JS.aspx?cb=jQuery112406115645482397511_1542356447436&type=CT&token=4f1862fc3b5e77c150a2b985b12db0fd&sty=FCOIATC&js=(%7Bdata%3A%5B(x)%5D%2CrecordsFiltered%3A(tot)%7D)&cmd="+cmd+"&st=(ChangePercent)&sr=-1&p="+str(page)+"&ps=20"
r = requests.get(url, headers=header)
pat = "data:\[(.*?)\]"
data = re.compile(pat,re.S).findall(r.text)
return data
#获取单个页面股票数据
def getOnePageStock(cmd,page):
data = getHtml(cmd,page)
datas = data[0].split('","')
stocks = []
for i in range(len(datas)):
stock = datas[i].replace('"',"").split(",")
stocks.append(stock)
return stocks
def main():
cmd = {
"上证指数":"C.1",
"深圳指数":"C.5",
}
for i in cmd.keys():
page = 1
stocks = getOnePageStock(cmd[i],page)
#自动爬取多页,并在结束时停止
while True:
page +=1
if getHtml(cmd[i],page)!= getHtml(cmd[i],page-1):
stocks.extend(getOnePageStock(cmd[i],page))
else:
break
df = pd.DataFrame(stocks)
columns = {1:"股票代码",2:"名称",3:"最新价格",4:"涨跌额",5:"涨跌幅",6:"成交量",7:"成交额",8:"振幅",9:"最高",10:"最低",11:"今开",12:"昨收"}
df.rename(columns = columns,inplace=True)
df.to_excel("股票/"+i+".xls")
print("已保存"+i+".xls")
main()
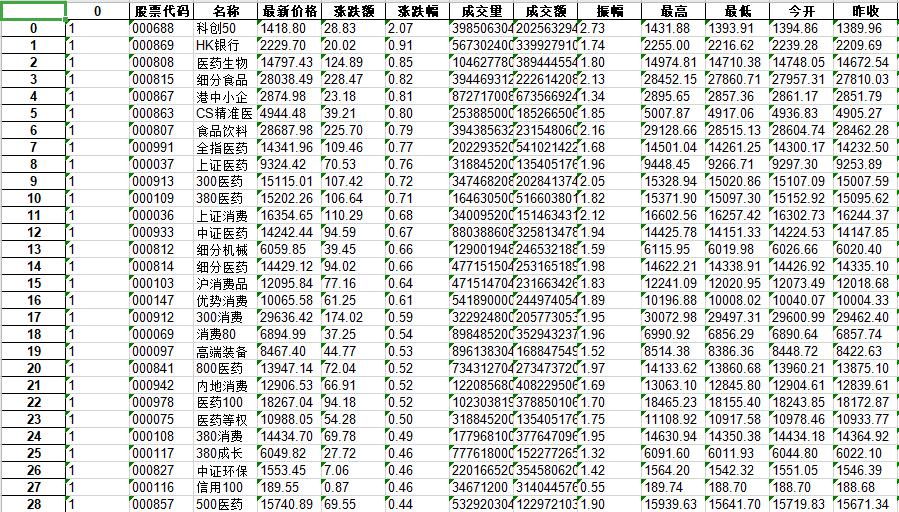
结果图片


上证指数的结果
2)心得体会
代码参考老师给出的链接,整个代码也是比较常规,重点在正则表达式提取需要的信息跟翻页处理,
学习到了翻页处理的思路和代码,get!
作业3
1)根据自选3位数+学号后3位选取股票,获取印股票信息
我选择的是300113——顺网科技
在要爬取的页面上,需要的数据是这个:

所以抓跑找到的数据,是这样子的,用f**区分想要的信息:(还是躲不掉)

数据文件:

可以看到,需要的数据在f44最高,f46今开,f51涨停,f57代码,f58名称,f162市盈,f168换手,f169涨跌
所以直接修改网址,得到想要的数据:

代码
import requests
import re
import pandas as pd
#用get方法访问服务器并提取页面数据
def getHTMLText(url):
header = {
'cookie': 'miid=871473411901751759; tk_trace=oTRxOWSBNwn9dPyorMJE%2FoPdY8zfvmw%2Fq5v3gzlT6TfC88%2B8VsR2LZeh0x0uZ2lavUunwk7FaQvkKtSF8tQ1fLpJrqsz14B%2FyobMQW8Exzoggkl4YwBJKriMzZBFIh%2FIQKv1FPsNnhV6P2HnGBVjbylCyWiAFwW1fvt3aOBQ3uoAwtp6Of66wJHZ8YPC4wCiq2449kBKT6ufwkDkOEQ0bb3%2BTywKDqprZHDdiDO7zqxULUBvZcPasjtJ6gwye5pjKqluzqIlGZw5KubUzluZEGHyoRYm; lLtC1_=1; t=da76da827c8812bfc2ef4d091ab75358; v=0; _tb_token_=3f7e30eaede6e; _m_h5_tk=55efe72e4a7e4752c144c9d9a52250c0_1600601808838; _m_h5_tk_enc=480b7ec5d4482475e3f5f76e0f27d20f; cna=ZgXuFztWFlECAdpqkRhAo4LI; xlly_s=1; _samesite_flag_=true; cookie2=13aa06fa1e7317d5023153e70e45e95f; sgcookie=E100jT6nEM5pUv7ZaP1urbIUwS5ucPPcz2pG%2FHs9VDYB91E14tzvEV8mMtRfZtLe4dg8rBjdN9PEuYVfhzjqARIFKQ%3D%3D; unb=2341324810; uc3=id2=UUtP%2BSf9IoxzEQ%3D%3D&nk2=t2JNBkErCYOaTw%3D%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&vt3=F8dCufeJMlcWOvLCctE%3D; csg=6e737d42; lgc=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; cookie17=UUtP%2BSf9IoxzEQ%3D%3D; dnk=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; skt=d79995fc094af782; existShop=MTYwMDU5MTk1Ng%3D%3D; uc4=id4=0%40U2l1DTh9%2F%2BK9Ym%2BCcxbZCceodFVg&nk4=0%40tRGCEUSTUyhwCCuPpi69tV6rFUkp; tracknick=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; _cc_=W5iHLLyFfA%3D%3D; _l_g_=Ug%3D%3D; sg=%E6%89%8B09; _nk_=%5Cu6E90%5Cu6E90%5Cu624B%5Cu62C9%5Cu624B; cookie1=AVdDOYh1aRzl%2BX23%2BL5DKrLq3hm6%2F%2BaYgNDVsRdW80M%3D; enc=Amz2MhdAq1awG9cmHzc5MLNi%2Bing6y4cR5EbHVPlJhWJxNKvr0B40mznTsnKW0JcubOujE6qhizMA84u7mBq2Q%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; mt=ci=85_1; uc1=existShop=false&cookie16=WqG3DMC9UpAPBHGz5QBErFxlCA%3D%3D&cookie14=Uoe0bU1NOIsDOA%3D%3D&cookie21=WqG3DMC9Fb5mPLIQo9kR&pas=0&cookie15=UIHiLt3xD8xYTw%3D%3D; thw=cn; JSESSIONID=6ECE41F4DC42E868790A52C0B362FD3C; isg=BNTUg0Kud-Dz7-OsCcrIFwHdpRJGLfgXLSfdwW61YN_iWXSjlj3Ip4rbWVFBujBv; l=eBgY5g8rOF5Pi0CSBOfanurza77OSIRYYuPzaNbMiOCP9b1B5N21WZru8mY6C3GVh60WR3rZpo7BBeYBqQAonxv92j-la_kmn; tfstk=cyJcBsT6YI5jdt1kOx6XAqHF5iMdwE3VudJvULmsgZ-4urfcF7PEePnlzEvT1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36'}
r = requests.get(url, headers=header, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
def getresult(result, html):
try:
pat = "\"data\"\:\{(.*?)\}"
data = re.findall(pat,html) # 提取data里需要的数据
# print(data[0])
data = ''.join(data) # 将列表化为字符串,方便后面进行分割提取数字数据
data = re.split(',|:',data) # 使用re库的split按照,和:对data进行分割
# print(data[0]) 每次print可以看出是想要的结果
# print(data)
# 直接打印
list = ["最高","今开","涨停","代码","名称","市盈","换手","涨跌"]
for i in range(len(list)):
print(list[i]+' '+data[2*i+1])
# 使用表格形式输出
d = []
d.append({list[0]:data[1],list[1]:data[3],list[2]:data[5],list[3]:data[7],list[4]:data[9],list[5]:data[11],list[6]:data[13],list[7]:data[15]})
df = pd.DataFrame(d)
print(df)
except:
print("error")
def main():
url = "http://push2.eastmoney.com/api/qt/stock/get?ut=fa5fd1943c7b386f172d6893dbfba10b&invt=2&fltt=2&fields=f57,f58,f46,f44,f51,f168,f162,f169&secid=0.300113&cb=jQuery112406595774665693546_1601708336071&_=1601708336072"
result = []
html = getHTMLText(url)
# print(html)
getresult(result, html)
main()
结果图片

2)心得体会
最后一个任务是完全靠自己写的啦(hhhh)
有了前一个作业经验以及踩过的坑,自己更加熟悉这一套流程,感觉也很有意思
但是在写正则表达式的时候也是尝试了很多种,最后出来想要的结果就很happy

 浙公网安备 33010602011771号
浙公网安备 33010602011771号