
RTX3090环境安装及性能测试体验
最近公司需要自己组装3090显卡,记录一下装机踩的坑。
首先安装Ubantu20.04,进入系统后有配置显卡所需环境有几个需要注意的地方:
一、网络设置
机器没有无线网卡只能使用usb共享手机热点联网;需要买外接网卡
chrome浏览器安装
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo dpkg -i google-chrome-stable_current_amd64.deb
二、关键软件安装
anaconda
cuda
cudnn
tensorflow
pytorch
1.anaconda
Anaconda是一个python环境的管理工具,使用它可以很方便对不同python版本的软件进行管理,所以首先安装anaconda
下载安装软件,可以从
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/
下载各个历史版本的anaconda,我下载的是Anaconda3-5.2.0-Linux-x86_64.sh
下载好之后直接放到ubantu中运行,根据提示选择就行
环境变量配置
安装的过程中会提示自动将安装路径加入到.bashrc文件中,所以安装好后需要使用
source ~/.bashrc
刷新环境变量。
Anaconda一个非常重要的功能就是可以创建不同的python虚拟环境,使用
Conda info —env命令查看当前环境
然后使用conda create -n tf1 python=3.6创建一个tf1的虚拟环境
之后可以用conda activate 和deactivate命令开启和关闭虚拟环境
也可以用conda env remove -n xxx 删除某一个虚拟环境
同样的方法创建tf2,以及putorch+python3.8环境
需要注意的是,后面每个虚拟环境里安装软件包则需要用pip命令,而不是conda命令,避免和其他环境起冲突。
一个技巧,在下载包的时候可以加上国内的源,加快下载安装的进度,需要配置vim /etc/pip.conf
在文件里编辑:
[global]
Trusted-host = mirrors.aliyun.com
index_url = http://mirrors.aliyun.com/simple
2.CUDA+CUDNN
CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 NVIDIA cuDNN是用于深度神经网络的GPU加速库。
从官方安装指南可以看出,只要把cuDNN文件复制到CUDA的对应文件夹里就可以,即是所谓插入式设计,把cuDNN数据库添加CUDA里,cuDNN是CUDA的扩展计算库,不会对CUDA造成其他影响。
一般来说,不同系列的显卡需要安装不同的CUDA,网上最新的资料都说3090需要安装最新的CUDA11.1以及配套的CUDNN8.0.5
从Nvidia官网上下载和操作系统对应的软件
从网上的各种资料看,大部分主流的资料都说3090的显卡需要cuda11.1加上cudnn8,然后tensorflow则需要配最新的tf2.5;还有部分资料说当前匹配不了cuda11.1,需要安装cuda11.0
但是由于已经习惯使用tf1.x版本,发现需要使用cuda10.0和cudnn7。
所以不确定哪个版本真正的可以使用3090,于是把3个版本都下载下来,然后安装3个版本,通过命令行切换软链接。安装cuda的时候根据提示就行,然后就是安装完成后配置环境变量,再把cudnn的相关文件根据网站的提示加到指定的位置。
需要注意的是不同的cuda版本是使用不同版本的gcc编译的,在安装的过程中还要对gcc进行升级和降级的操作。
还有一种方案是直接在anaconda的虚拟环境中安装不同版本的cuda,需要把真实环境中的cuda先卸载掉,这个方案也很灵活,但是我已经安装了cuda,也就没用这个方案了。
最终可以使用nvidia-smi查看gpu驱动的情况
然后使用nvcc -V查看当前的cuda版本
cat cuda/include/cudnn_version.h |grep ^# 查看cudnn版本
3.测试是否使用gpu加速
主要需要确认一下几个步骤:
(1)tensorflow能否检测到gpu设备
Import tensor flow as tf
print(tf.test.is_gpu_available())
如果为true表示tensorflow安装成功,且能检测到gpu设备
(2)跑训练模型查看日志是否加载cudnn的lib64的相关文件,如果没有加载则说明tensorflow版本和cuda版本不匹配
(3)使用nvidia-smi命令监控gpu的利用率,注意是利用率,因为程序跑通可能会占用gpu内存,但是如果没有看到gpu利用率发生变化则也可能是存在问题的。
三、BERT微调以及预训练测试
BERT微调主要包括以下几个步骤:下载预训练好的bert模型文件;准备微调的文本;加载模型进行微调。
此次微调使用的是哈工大的预训练好的中文bert文件,微调的文本则是做测试用的情感识别的二分类以及句子相似度任务的分类。
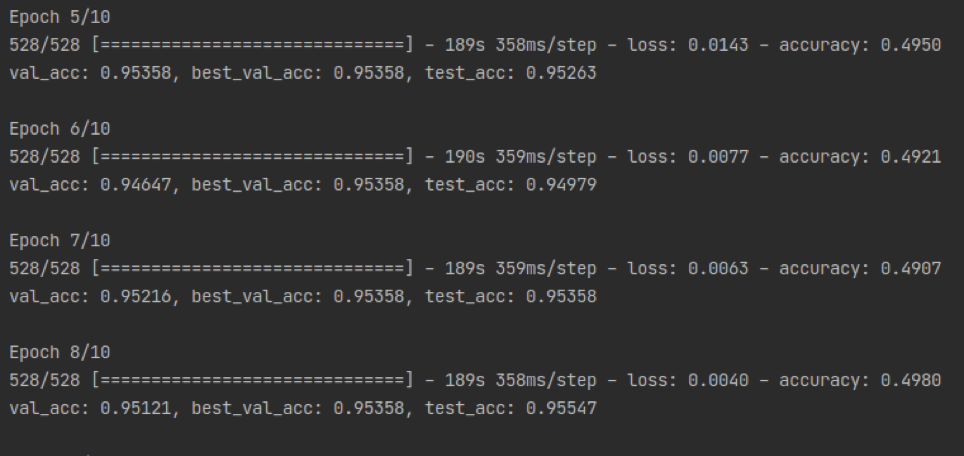
上图是对二分类任务的微调测试,框架使用的是tensorflow2.5,文本按照每条句子进行输入,跑一条句子是时间平均下来为360ms,与网上相关文章对比发现性能有点偏慢,可能是因为加上了对原始文本进行分词的时间。
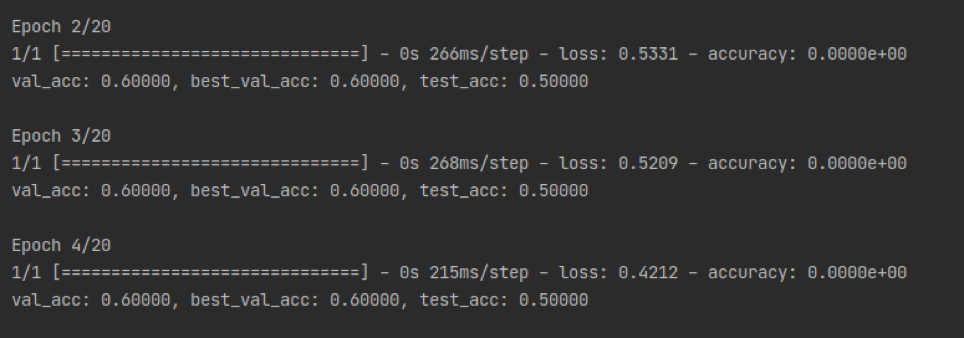
上图则是一个句子相似度任务的微调测试,每条句子用时差不多268ms,时间比分类任务
少,原因是输入的文本更短。
由于tensorflow2.0以上版本变化太大,不能很好地兼容bert预训练任务,于是使用pytorch对文本进行预训练任务测试,测试文本使用的是86000条新闻标题短文本,训练过程如下图:
跑完一个完整的数据大概需要68分钟,每条数据大概46ms,对比网上1080ti每条216ms快了差不多5倍。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号