
Python 正则表达式Ⅳ
repl 参数是一个函数
以下实例中将字符串中的匹配的数字乘以 2:
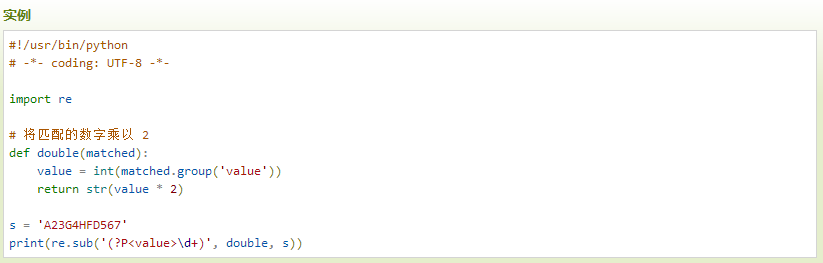
执行输出结果为:

re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
语法格式为:

参数:
-
pattern : 一个字符串形式的正则表达式
-
flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
- re.I 忽略大小写
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M 多行模式
- re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和 # 后面的注释
实例

在上面,当匹配成功时返回一个 Match 对象,其中:
group([group1, …])方法用于获得一个或https://www.xuanhe.net/多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用group()或group(0);start([group])方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;end([group])方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;span([group])方法返回(start(group), end(group))。
再看看一个例子:

findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
语法格式为:

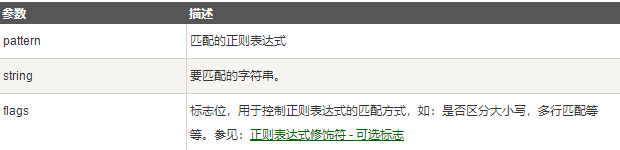
参数:
- string : 待匹配的字符串。
- pos : 可选参数,指定字符串的起始位置,默认为 0。
- endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。
查找字符串中的所有数字:
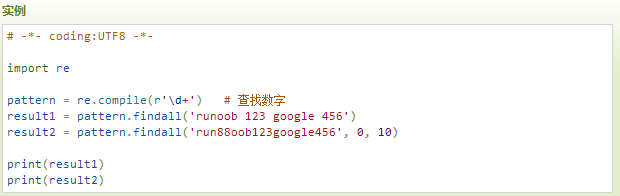
输出结果:

re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。

参数:
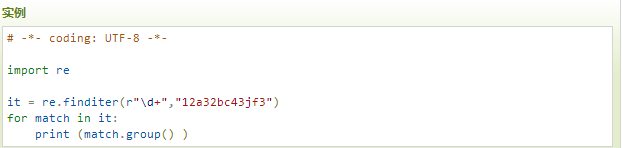
输出结果:

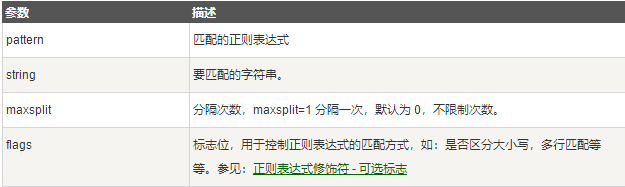
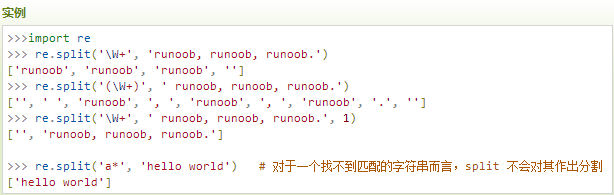
re.split
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:

参数:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号