
SQL基础——
1.要求查询所有列
——有两种方式,
方式一:select * from 表名;
方式二:select 列名1,列名2,列名3... from 表名;
实际开发中,更建议使用第二种,因为第一种实际上需要先将*转化为每个列名,然后再开始查询,运行时间相对第二种更久,内存占用更高。
且在实际的业务需求中,通过第二种方式 select 列名 来查询可以自定义显示的顺序,以及显示的字段,更加灵活。
2.运营只需要查看前2个用户明细设备ID数据,请你从用户信息表 user_profile 中取出相应结果
——有三种方式,
select device_id from user_profile limit 0,2---运行效率高
select device_id from user_profile limit 2 ---运行效率低
也可结合 limit offset: 一起使用时,limit表示要取的数量,offset表示初始位置
select device_id from user_profile limit 2 offset 0 // 从第一条数据开始取,取两条数据 ---运行效率中
使用LIMIT限制结果集
LIMIT 子句可以被用于强制 SELECT 语句返回指定的记录数。
LIMIT 接受一个或两个数字参数。参数必须是一个整数常量。
如果只给定一个参数,它表示返回最大的记录行数目。
如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。
为了检索从某一个偏移量到记录集的结束所有的记录行,可以指定第二个参数为 -1。
初始记录行的偏移量是 0(而不是 1)。
检索记录行 6-10——SELECT * FROM table LIMIT 5,5
SELECT * FROM table LIMIT 10,-1检索前 5 个记录行——SELECT * FROM table LIMIT 5
3.需要查看前2个用户明细设备ID数据,并将列名改为 'user_infos_example',请你从用户信息表取出相应结果
select device_id user_infos_example from user_profile limit 0,2;
//1.as 写不写都可//2.别名加不加引号(单双)都可 //加引号:别名就是引号内的内容。 //不加引号:别名如果为小写,会解析为大写,别名实际为大写。//以上两点在调用别名时要注意,易报错:找不到对应的列(大小写对应的是不同的列)
4.现在运营想要筛选出所有北京大学的学生进行用户调研,请你从用户信息表中取出满足条件的数据,结果返回设备id和学校
select device_id, university from user_profile where university = '北京大学';
可以优化一下,
使用索引覆盖效率提升80%
select语句中使用的索引覆盖所有需要查询的字段
覆盖索引的原理:就是查询字段在 二级索引中全部找到,不需要回表查询
覆盖索引只是特定于具体select语录而言的联合索引。也就是说一个联合索引对于某个select语句,通过索引可以直接获取查询结果,而不再需要回表查询啦,就称该联合索引覆盖了这条select语句。
本题中经过测试,device_id,university 为联合索引,因此:
Select device_id,university FROM user_profile where university = "北京大学" and device_id = user_profile.device_id;
device_id = user_profile.device_id 这一步是100%成立的,使用的目的就是索引覆盖,以此实现提升查询效率
5.
用where过滤空值
方法1:select device_id,gender,age,university from user_profile where age is not NULL --运行效率高
方法2:select device_id,gender,age,university from user_profile where age !='' --运行效率低
6.
-
_ :下划线 代表匹配任意一个字符;
-
% :百分号 代表匹配0个或多个字符;
-
[]: 中括号 代表匹配其中的任意一个字符;
-
[^]: ^尖冒号 代表 非,取反的意思;不匹配中的任意一个字符。
tips:面试常问的一个问题:你了解哪些数据库优化技术?
SQL语句优化也属于数据库优化一部分,而我们的like模糊查询会引起全表扫描,速度比较慢,应该尽量避免使用like关键字进行模糊查询。
7.
WHERE, GROUP BY, HAVING
当查询语句的目标列中包含聚合函数时,若没有分组子句,则目标列中只能写聚合函数,而不能再写其他列名。若包含分组子句,则在查询的目标列中除了可以写聚合函数外,只能写分组依据列。
WHERE子句用来筛选FROM子句中指定的数据源所产生的行数据。
GROUP BY子句用来对经WHERE子句筛选后的结果数据进行分组。
HAVING子句用来对分组后的结果数据再进行筛选。
对于可以在分组操作之前应用的搜索条件,在WHERE子句中指定它们更有效,这样可以减少参与分组的数据行。
应当在HAVING子句中指定的搜索条件应该是那些必须在执行分组操作之后应用的搜索条件。
建议将所有行搜索条件放在WHERE子句中而不是HAVING子句中
UNION(并)
使用 UNION可以实现将多个查询结果集合并为一个结果集。
所有查询语句中列的个数和列的顺序必须相同。
所有查询语句中对应列的数据类型必须兼容。
ORDER BY语句要放在最后一个查询语句的后边。
union 会去重。而使用union all 可以将查询结果合并且不去重。
9.现在运营想要将用户划分为25岁以下和25岁及以上两个年龄段,分别查看这两个年龄段用户数量
select case when age < 25 or age is null then '25岁以下'
when age >= 25 then '25岁及以上'
end as age_cut, count(*) as number
from user_profile
group by age_cut
CASE函数
是一种多分支的函数,可以根据条件列表的值返回多个可能的结果表达式中的一个。
可用在任何允许使用表达式的地方,但不能单独作为一个语句执行。
分为:
简单CASE函数
搜索CASE函数
10.计算用户的平均次日留存率
现在运营想要查看用户在某天刷题后第二天还会再来刷题的平均概率。请你取出相应数据
所谓次日留存,指的是同一用户(在本题中则为同一设备,即device_id)在当天和第二天都进行刷题。注意,在这题我们不关心同一用户(设备)在这天答了什么题、答题结果如何,只关心他是否答题,因此对于这题来说存在重复的数据,需要使用 DISTINCT 去重。
而次日留存率可以这样表示:
具体而言,使用两个子查询,查询出两个去重的数据表,并使用条件(q2.date应该是q1.date的后一天)进行筛选
因为使用的是q1左级联q2,所以q1的所有信息是显示的;而q2中只显示留存的信息,否则为null。
最后,分别统计q1.device_id 和 q2.device_id 作去重后的所有条目数和去重后的次日留存条目数,即可算出次日留存率。
注意,MySQL中 COUNT在对列进行计数时不统计值为 null的条目
SELECT
COUNT(q2.device_id) / COUNT(q1.device_id) AS avg_ret
FROM
(SELECT DISTINCT device_id, date FROM question_practice_detail) AS q1
LEFT JOIN
(SELECT DISTINCT device_id, date FROM question_practice_detail) AS q2
ON q1.device_id = q2.device_id AND q2.date = DATE_ADD(q1.date, interval 1 day)
substring_index()函数
substring_index()函数用来截取字符串
substring_index(str,delim,count)
str:要处理的字符串
delim:分隔符
count:计数如 str=www.wiki.com
则 substring_index(str,'.',1) 处理的结果是:www
substring_index(str,'.',2) 得到的结果是:www.wiki
也就是说,如果count是正数,那么就是从左往右数,第N个分隔符的左边的全部内容,
相反,如果是负数,那么就是从右边开始数,第N个分隔符右边的所有内容。
如:
substring_index(str,'.',-2) 得到的结果为:http://wikibt.com
如果要中间的的 wiki 怎么办?
很简单的,需要从两个方向截取:
先截取从右数第二个分隔符的右边的全部内容,再截取从左数的第一个分隔符的左边的全部内容:
substring_index(substring_index(str,'.',-2),'.',1);
12.对于申请参与比赛的用户,blog_url字段中url字符后的字符串为用户个人博客的用户名,
现在运营想要把用户的个人博客用户字段提取出单独记录为一个新的字段,请取出所需数据
切割、截取、删除、替换
select
-- 替换法 replace(string, '被替换部分','替换后的结果')
-- device_id, replace(blog_url,'http:/url/','') as user_name
-- 截取法 substr(string, start_point, length*可选参数*)
-- device_id, substr(blog_url,11,length(blog_url)-10) as user_nam
-- 删除法 trim('被删除字段' from 列名)
-- device_id, trim('http:/url/' from blog_url) as user_name
-- 字段切割法 substring_index(string, '切割标志', 位置数(负号:从后面开始))
device_id, substring_index(blog_url,'/',-1) as user_name
from user_submit;
13.SQL中的表连接
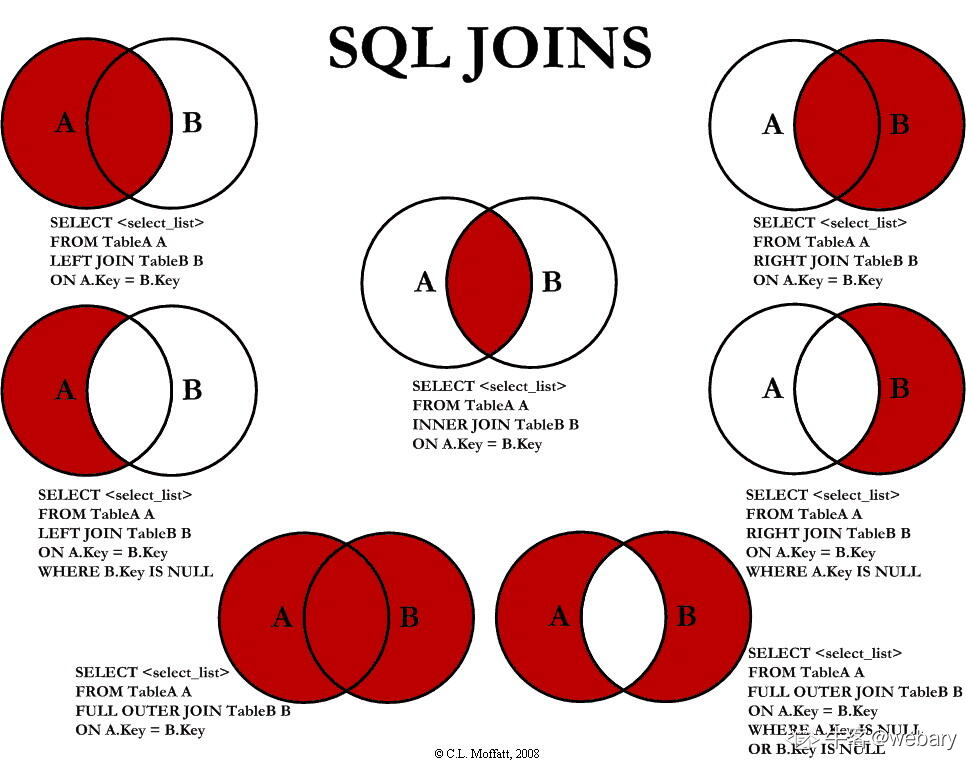
14.SQL中有关字符串的操作:
- 字符串的截取:substring(字符串,起始位置,截取字符数) 注意:起始位置是从1开始的,而不是从0开始
- 字符串的拼接:concat(字符串1,字符串2,字符串3,...)
- 字母大写:upper(字符串)
15.
- join---连接表,对列操作
- union--连接表,对行操作
- union--将两个表做行拼接,同时自动删除重复的行
- union all---将两个表做行拼接,保留重复的行
16.
插入记录的方式汇总:
- 普通插入(全字段):INSERT INTO table_name VALUES (value1, value2, ...)
- 普通插入(限定字段):INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...)
- 多条一次性插入:INSERT INTO table_name (column1, column2, ...) VALUES (value1_1, value1_2, ...), (value2_1, value2_2, ...), ...
- 从另一个表导入:INSERT INTO table_name SELECT * FROM table_name2 [WHERE key=value]
- 带更新的插入:REPLACE INTO table_name VALUES (value1, value2, ...) (注意这种原理是检测到主键或唯一性索引键重复就删除原记录后重新插入)
17.
删除记录的方式汇总:
- 根据条件删除:DELETE FROM tb_name [WHERE options] [ [ ORDER BY fields ] LIMIT n ]
- 全部删除(表清空,包含自增计数器重置):TRUNCATE tb_name
时间差:
- TIMESTAMPDIFF(interval, time_start, time_end)可计算time_start-time_end的时间差,单位以指定的interval为准,常用可选:
- SECOND 秒
- MINUTE 分钟(返回秒数差除以60的整数部分)
- HOUR 小时(返回秒数差除以3600的整数部分)
- DAY 天数(返回秒数差除以3600*24的整数部分)
- MONTH 月数
- YEAR 年数
18.
- 自增ID:AUTO_INCREMENT;
- 设置主键:PRIMARY KEY;
- 唯一性约束:UNIQUE
- 非空约束:NOT NULL
- 设置默认值:DEFAULT 0
- 当前时间戳:CURRENT_TIMESTAMP
- 评论/注释:COMMENT
- 如果该表已创建过,正常返回:IF NOT EXISTS
19.
如果题目要求排序时将某字段的两个值排到最后,怎么办?
可以使用 ... order by 字段 in ('值1','值2')
这样的话,在排序的时候如果该字段符合这两个值,就会被设为1,其余值为0,而sql默认排序为降序,就会把这两个值的数据放在最后了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号