24.12.13
实验八:随机森林算法实现与测试
一、实验目的
深入理解随机森林的算法原理,进而理解集成学习的意义,能够使用Python语言实现 随机森林算法的训练与测试,并且使用五折交叉验证算法进行模型训练与评估。
二、实验内容
(1)从scikit-learn 库中加载 iris 数据集,使用留出法留出 1/3 的样本作为测试集(注 意同分布取样);
(2)使用训练集训练随机森林分类算法;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和 F1 值)进行评估和选 择;
(4)使用测试集,测试模型的性能,对测试结果进行分析,完成实验报告中实验八的 部分。
三、算法步骤、代码、及结果
1. 算法伪代码
1. 加载数据集
- 加载 Iris 数据集
- 将特征数据存储在 X 中,将标签数据存储在 y 中
2. 数据集划分
- 使用留出法将数据集划分为训练集和测试集
- 训练集:2/3 的数据
- 测试集:1/3 的数据
- 确保划分时各类别的样本比例相同(同分布取样)
3. 创建并训练模型
- 创建一个随机森林分类器(RandomForestClassifier)
- 使用训练集数据(X_train 和 y_train)训练模型
4. 五折交叉验证
- 对模型进行五折交叉验证,计算以下性能指标:
- 准确度(accuracy)
- 精度(precision)
- 召回率(recall)
- F1 值(F1 score)
5. 测试集性能评估
- 使用训练好的模型对测试集进行预测
- 计算以下测试集性能指标:
- 准确度(accuracy)
- 精度(precision)
- 召回率(recall)
- F1 值(F1 score)
6. 输出结果
- 输出五折交叉验证的结果(平均准确度、精度、召回率、F1 值)
- 输出测试集的性能评估结果(准确度、精度、召回率、F1 值)
2. 算法主要代码
完整源代码\调用库方法(函数参数说明)
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# 1. 加载 iris 数据集
iris = datasets.load_iris()
X = iris.data # 特征数据
y = iris.target # 真实标签
# 2. 使用留出法分割数据集,1/3 的数据作为测试集,2/3
的数据作为训练集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/3, random_state=42,
stratify=y)
# 3. 创建并训练随机森林分类器
rf_clf = RandomForestClassifier(random_state=42)
rf_clf.fit(X_train, y_train)
# 4. 使用五折交叉验证评估模型性能
cross_val_scores_accuracy = cross_val_score(rf_clf, X, y, cv=5, scoring='accuracy')
cross_val_scores_precision = cross_val_score(rf_clf, X, y, cv=5, scoring='precision_weighted')
cross_val_scores_recall = cross_val_score(rf_clf, X, y, cv=5, scoring='recall_weighted')
cross_val_scores_f1 = cross_val_score(rf_clf, X, y, cv=5, scoring='f1_weighted')
# 输出五折交叉验证结果
print(f"五折交叉验证准确度: {cross_val_scores_accuracy.mean():.4f}")
print(f"五折交叉验证精度: {cross_val_scores_precision.mean():.4f}")
print(f"五折交叉验证召回率: {cross_val_scores_recall.mean():.4f}")
print(f"五折交叉验证 F1 值: {cross_val_scores_f1.mean():.4f}")
# 5. 使用测试集进行预测
y_pred = rf_clf.predict(X_test)
# 6. 测试集性能评估
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')
# 输出测试集的性能评估
print(f"\n测试集准确度: {accuracy:.4f}")
print(f"测试集精度: {precision:.4f}")
print(f"测试集召回率: {recall:.4f}")
print(f"测试集 F1 值: {f1:.4f}")
1. sklearn.datasets.load_iris(return_X_y=False,
as_frame=False)
该函数用于加载 Iris 数据集。
参数说明:
return_X_y (默认 False):
False(默认):返回包含数据集的字典格式。字典中包含 data(特征矩阵)和 target(标签向量)。
True:直接返回特征数据(X)和标签(y),而不使用字典封装。
as_frame (默认 False):
False(默认):返回一个 Bunch 类型的字典。
True:返回一个 pandas.DataFrame,使数据能够更方便地与 Pandas 进行操作。
返回值:
如果 return_X_y=False:返回一个包含 data 和 target 的 Bunch 对象。
如果 return_X_y=True:返回一个元组 (X, y),X 为特征数据,y 为标签数据。
2. train_test_split()
该函数用于将数据集分割为训练集和测试集。
sklearn.model_selection.train_test_split(*arrays,
test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
参数说明:
arrays:要分割的数据,可以是特征数据 X 和标签数据 y(通常为 NumPy
数组或 Pandas DataFrame)。
test_size(默认 None):
用于指定测试集的大小。如果是浮动数值(如
0.33),表示测试集占总数据集的比例。
也可以指定整数,表示测试集样本的绝对数量。
train_size(默认 None):
用于指定训练集的大小。可以是浮动数值或整数。如果不设置(默认为 None),则由 test_size 自动推断。
random_state(默认 None):
设置随机种子,确保每次分割数据时都能得到相同的结果。
shuffle(默认 True):
True:在划分数据集之前,先随机打乱数据。
False:不进行打乱操作。
stratify(默认 None):
None:不进行分层抽样。
如果设置为 y,则按照 y 中的标签分层抽样,确保每个类别在训练集和测试集中的比例相同。
返回值:
返回四个数组:X_train, X_test, y_train, y_test,分别是划分后的训练特征、测试特征、训练标签和测试标签。
3. RandomForestClassifier()
该函数用于创建一个随机森林分类器。
sklearn.ensemble.RandomForestClassifier(n_estimators=100,
criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1,
random_state=None, n_jobs=None, verbose=0)
参数说明:
• n_estimators(默认 100):
• 随机森林中树的数量。更多的树通常会提高模型的性能,但计算成本也更高。
• criterion(默认 'gini'):
• 用于划分的标准。可以选择:
• 'gini':基尼不纯度。
• 'entropy':信息增益。
• max_depth(默认 None):
• 树的最大深度。None 表示树会一直生长,直到叶子节点只包含一个样本。如果设置为正整数,树会在该深度时停止生长。
• min_samples_split(默认 2):
• 分裂内部节点所需的最小样本数。设置较大的值可以防止模型过拟合。
• min_samples_leaf(默认 1):
• 叶节点上的最小样本数。如果一个叶子节点包含的样本数小于这个值,它将不会分裂。
• random_state(默认 None):
• 控制随机性。用于初始化随机数生成器,确保结果可重复。
• n_jobs(默认 None):
• 控制用于计算的作业数量。None 表示使用所有可用的处理器。若设置为 -1,则使用所有CPU核心。
• verbose(默认 0):
• 控制是否输出详细信息。0 表示不输出,较大的值会输出更多调试信息。
返回值:
• 返回一个已训练的 RandomForestClassifier 对象,可以通过该对象进行预测和评估。
4. cross_val_score()
该函数用于通过交叉验证评估模型的性能。
sklearn.model_selection.cross_val_score(estimator,
X, y=None, scoring=None, cv=None, n_jobs=None, verbose=0, fit_params=None,
pre_dispatch='2*n_jobs')
参数说明:
estimator:
要评估的模型或估算器,例如 RandomForestClassifier。
X:
输入特征数据。
y(默认 None):
目标标签数据。
scoring(默认 None):
评估模型的指标。可以是:
'accuracy':准确度。
'precision':精度。
'recall':召回率。
'f1':F1 值。
或者自定义评分函数。
cv(默认 None):
交叉验证的折数。如果是整数,则为交叉验证的折数。例如 cv=5 表示五折交叉验证。也可以传入一个交叉验证生成器对象。
n_jobs(默认 None):
控制计算时并行化的作业数。None 使用所有可用的核心,-1 使用所有 CPU 核心,其他值指定使用的核心数。
verbose(默认 0):
输出日志的详细程度,0 表示没有输出,1 表示输出进度信息。
fit_params(默认 None):
模型的拟合参数。如果估算器需要额外的拟合参数,可以通过这个参数传递。
pre_dispatch(默认 '2*n_jobs'):
控制任务的提前调度。如果为 None,则立即调度;'2*n_jobs' 表示每个作业最多调度两次。
返回值:
返回一个包含交叉验证评分的数组。
3. 训练结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
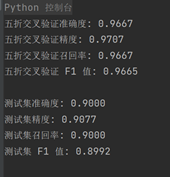
四、实验结果分析
1. 测试结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)

2. 对比分析
准确度:
五折交叉验证中的准确度为 96.67%,而测试集的准确度为 90.00%。这表明在训练数据上,模型的表现更好,可能是因为训练数据的样本量和多样性较高,模型对其拟合得更好。测试集的准确度下降可能是由于模型在新数据上的泛化能力较弱。
精度:
五折交叉验证中的精度为 97.07%,测试集精度为 90.77%。精度反映了模型预测正类的准确性,在训练集上的表现要好于测试集。这意味着在训练集上,模型能够较好地区分正负样本,但在测试集上,可能存在一定的误判。
召回率:
五折交叉验证的召回率为 96.67%,测试集的召回率为 90.00%。召回率衡量模型正确识别正类样本的能力。五折交叉验证中的召回率较高,说明模型能较好地识别正类,但在测试集上,模型可能未能有效捕捉到所有正类样本,导致召回率下降。
F1 值:
F1 值综合考虑了精度和召回率,五折交叉验证的 F1 值为 96.65%,而测试集为 89.92%。F1 值的下降表明测试集上的精度和召回率存在一定的权衡,模型的表现稍逊色于训练集。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号