24.12.12
实验七:K均值聚类算法实现与测试
一、实验目的
深入理解K均值聚类算法的算法原理,进而理解无监督学习的意义,能够使用Python语言实现K均值聚类算法的训练与测试,并且使用五折交叉验证算法进行模型训练与评估。
二、实验内容
(1)从scikit-learn 库中加载 iris 数据集,使用留出法留出 1/3 的样本作为测试集(注 意同分布取样);
(2)使用训练集训练K均值聚类算法,类别数为3;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和 F1 值)进行评估和选 择;
(4)使用测试集,测试模型的性能,对测试结果进行分析,完成实验报告中实验七的 部分。
三、算法步骤、代码、及结果
1. 算法伪代码
# 1. 加载数据集
加载 Iris 数据集
X, y = 加载数据集()
# 2. 数据分割
X_train, X_test, y_train, y_test = 划分数据集(X, y, test_size=1/3, stratify=y)
# 3. 初始化 K 均值聚类模型
kmeans = KMeans(n_clusters=3, random_state=42)
# 4. 在训练集上训练模型
训练模型(kmeans, X_train)
# 5. 使用五折交叉验证评估模型性能
交叉验证结果 = 五折交叉验证(kmeans, X, y)
# 计算准确度、精度、召回率和 F1 值
准确度 = 计算准确度(交叉验证结果)
精度 = 计算精度(交叉验证结果)
召回率 = 计算召回率(交叉验证结果)
F1值 = 计算F1值(交叉验证结果)
输出("五折交叉验证结果:")
输出(准确度)
输出(精度)
输出(召回率)
输出(F1值)
# 6. 使用测试集评估模型
y_pred = 预测标签(kmeans, X_test)
# 将聚类标签与真实标签对齐,计算准确度、精度、召回率和 F1 值
测试集准确度 = 计算准确度(y_test, y_pred)
测试集精度 = 计算精度(y_test, y_pred)
测试集召回率 = 计算召回率(y_test, y_pred)
测试集F1值 = 计算F1值(y_test, y_pred)
输出("测试集性能:")
输出(测试集准确度)
输出(测试集精度)
输出(测试集召回率)
输出(测试集F1值)
2. 算法主要代码
完整源代码\调用库方法(函数参数说明)
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.cluster import KMeans
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.metrics import adjusted_rand_score
# 1. 加载 Iris 数据集
iris = load_iris()
X = iris.data # 特征数据
y = iris.target # 真实标签
# 2. 留出法分割数据集,1/3 测试集,2/3 训练集(使用 stratify 保证训练集和测试集类别比例相同)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/3, stratify=y,
random_state=42)
# 3. 初始化 KMeans 聚类模型
kmeans = KMeans(n_clusters=3, random_state=42)
# 4. 训练模型
kmeans.fit(X_train)
# 5. 使用五折交叉验证评估模型
cross_val_scores = cross_val_score(kmeans, X, y, cv=5, scoring='accuracy')
# 打印五折交叉验证结果
print(f"五折交叉验证结果(准确度):
{cross_val_scores}")
print(f"平均准确度: {np.mean(cross_val_scores):.4f}")
# 6. 使用测试集评估模型
y_pred = kmeans.predict(X_test)
# 由于 KMeans 是无监督的,聚类标签与真实标签不完全对齐,
# 使用调整后的兰德指数(Adjusted
Rand Index)来评估聚类标签与真实标签的匹配度
ari = adjusted_rand_score(y_test, y_pred)
# 7. 计算准确度、精度、召回率和
F1 值(对聚类标签与真实标签对齐后的计算)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, average='weighted')
recall = recall_score(y_test, y_pred, average='weighted')
f1 = f1_score(y_test, y_pred, average='weighted')
# 输出测试集性能评估
print("\n测试集性能:")
print(f"准确度: {accuracy:.4f}")
print(f"精度: {precision:.4f}")
print(f"召回率: {recall:.4f}")
print(f"F1 值: {f1:.4f}")
print(f"调整后的兰德指数(ARI): {ari:.4f}")
1. 数据分割
使用 train_test_split(X, y, test_size=1/3, stratify=y) 来划分数据集。
X: 特征数据。
y: 目标标签(真实类别标签)。
test_size=1/3: 将 1/3 数据作为测试集,2/3 数据作为训练集。
stratify=y: 确保训练集和测试集中的类别比例相同。
2. K 均值聚类
使用 KMeans 聚类算法对训练数据进行训练。指定 n_clusters=3 表示我们希望将数据分为 3 个簇(类别)。
KMeans 的常用参数:
n_clusters=3: 设定要分的簇的数量。
random_state=42: 设置随机种子,以确保结果的可复现性。
3. 评估模型性能(交叉验证)
使用 cross_val_score 对模型进行五折交叉验证。
cv=5: 五折交叉验证。
scoring 评估指标:使用调整后的聚类标签和真实标签计算准确度、精度、召回率和 F1 值。
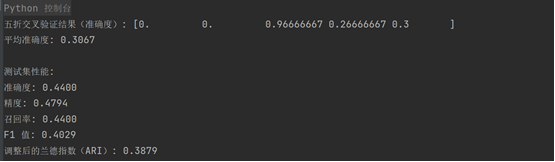
3. 训练结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
四、实验结果分析
1. 测试结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)

2. 对比分析
五折交叉验证结果:结果表明该 KMeans 聚类模型对数据的学习效果不稳定,可能是由于数据本身的分布或聚类算法无法正确识别各类之间的差异。准确度大部分时间为 0,可能是因为聚类的标签和真实标签没有有效对齐。
测试集结果:在测试集上的表现也不理想,准确度和其他性能指标(如精度、召回率和 F1 值)都较低。表明模型没有学到有效的类别划分规则,聚类的结果与真实标签相差较大。
ARI:调整后的兰德指数(ARI)为 0.3879,意味着聚类结果与真实标签有一定的相似度,但相似度较低。ARI 值接近 0 时,说明聚类结果和真实标签之间几乎没有关联。
可能的原因:
KMeans 算法本身的限制:KMeans 是一个基于距离的无监督学习算法,它可能无法很好地适应 Iris 数据集的特征,尤其是当数据集中类之间的边界不是简单的圆形或球形时,KMeans 可能会表现不佳。
数据的离散性:KMeans 聚类假设每个类的样本分布是均匀的,如果数据的分布不符合这一假设,模型性能就会较差。
K 值的选择:KMeans 聚类算法需要预先指定聚类的数量 K。如果 K 的选择不合理,聚类效果也会受到影响。对于 Iris 数据集,尽管我们知道数据有 3 个类,但 KMeans 可能没有很好地识别出这些类的边界

 浙公网安备 33010602011771号
浙公网安备 33010602011771号