

24.12.10
实验五:BP神经网络算法实现与测试
一、实验目的
深入理解BP神经网络的算法原理,能够使用Python语言实现BP神经网络的训练与测 试,并且使用五折交叉验证算法进行模型训练与评估。
二、实验内容
(1)从scikit-learn 库中加载 iris 数据集,使用留出法留出 1/3 的样本作为测试集(注 意同分布取样);
(2)使用训练集训练BP神经网络分类算法;
(3)使用五折交叉验证对模型性能(准确度、精度、召回率和 F1 值)进行评估和选 择;
(4)使用测试集,测试模型的性能,对测试结果进行分析,完成实验报告中实验五的部分。
三、算法步骤、代码、及结果
1. 算法伪代码
1. 加载 iris 数据集
Dataset ← Load iris dataset
2. 划分数据集为训练集和测试集
(X_train, X_test, y_train, y_test) ← TrainTestSplit(Dataset, test_size=1/3, stratify=y, random_state=42)
3. 初始化 BP 神经网络模型
BP_Model ← MLPClassifier(hidden_layer_sizes=(100), max_iter=200, solver='adam', random_state=42)
4. 训练 BP 神经网络模型
BP_Model.fit(X_train, y_train)
5. 五折交叉验证
For each fold in 5-fold cross-validation:
- 训练子集 ← 训练数据中的 4 份
- 验证子集 ← 训练数据中的 1 份
- 训练模型 BP_Model
- 验证模型,记录预测结果
End For
计算五折交叉验证的性能指标:
Accuracy_cv ← Calculate accuracy from cross-validation predictions
Precision_cv ← Calculate precision from cross-validation predictions
Recall_cv ← Calculate recall from cross-validation predictions
F1_cv ← Calculate F1-score from cross-validation predictions
6. 使用测试集评估模型性能
y_test_pred ← BP_Model.predict(X_test)
计算测试集的性能指标:
Accuracy_test ← Calculate accuracy from y_test and y_test_pred
Precision_test ← Calculate precision from y_test and y_test_pred
Recall_test ← Calculate recall from y_test and y_test_pred
F1_test ← Calculate F1-score from y_test and y_test_pred
7. 输出结果
输出五折交叉验证结果 (Accuracy_cv, Precision_cv, Recall_cv, F1_cv)
输出测试集性能结果 (Accuracy_test, Precision_test, Recall_test, F1_test)
2. 算法主要代码
完整源代码\调用库方法(函数参数说明)
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score, cross_val_predict
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, classification_report
from sklearn.neural_network import MLPClassifier
# (1) 加载 iris 数据集并划分训练集和测试集
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.33, stratify=data.target, random_state=42)
# (2) 使用训练集训练 BP 神经网络
# 初始化 MLPClassifier(BP 神经网络)模型
bp_model = MLPClassifier(hidden_layer_sizes=(100,), max_iter=200, solver='adam', random_state=42)
# 模型训练
bp_model.fit(X_train, y_train)
# (3) 五折交叉验证评估模型性能
# 使用 cross_val_predict 来获取每一折的预测结果,并计算多项评估指标
y_train_pred = cross_val_predict(bp_model, X_train, y_train, cv=5)
# 计算交叉验证评估指标
cv_accuracy = accuracy_score(y_train, y_train_pred)
cv_precision = precision_score(y_train, y_train_pred, average='weighted')
cv_recall = recall_score(y_train, y_train_pred, average='weighted')
cv_f1 = f1_score(y_train, y_train_pred, average='weighted')
print("五折交叉验证结果:")
print(f"准确度:{cv_accuracy:.4f}")
print(f"精度:{cv_precision:.4f}")
print(f"召回率:{cv_recall:.4f}")
print(f"F1值:{cv_f1:.4f}")
# (4) 使用测试集评估模型性能
y_test_pred = bp_model.predict(X_test)
# 计算测试集评估指标
test_accuracy = accuracy_score(y_test, y_test_pred)
test_precision = precision_score(y_test, y_test_pred, average='weighted')
test_recall = recall_score(y_test, y_test_pred, average='weighted')
test_f1 = f1_score(y_test, y_test_pred, average='weighted')
print("\n测试集性能:")
print(f"准确度:{test_accuracy:.4f}")
print(f"精度:{test_precision:.4f}")
print(f"召回率:{test_recall:.4f}")
print(f"F1值:{test_f1:.4f}")
1. MLPClassifier 类
MLPClassifier 是用于多层感知器(BP 神经网络)分类的模型,常用于解决分类问题。
主要参数及其说明
• hidden_layer_sizes
o 作用:指定隐藏层的神经元数量及层数。
o 类型:元组,例如 (100,) 表示一个隐藏层,包含 100 个神经元;(100, 50) 表示两层,第一层 100 个神经元,第二层 50 个神经元。
o 默认值:(100,)。
• activation
o 作用:指定激活函数类型。
o 可选值:
'identity':恒等函数。
'logistic':Sigmoid 函数。
'tanh':双曲正切函数。
'relu':整流线性单元函数(默认值)。
o 默认值:'relu'。
• solver
o 作用:指定优化算法。
o 可选值:
'lbfgs':准牛顿法,适用于小数据集。
'sgd':随机梯度下降。
'adam':自适应矩估计(默认值)。
o 默认值:'adam'。
• alpha
o 作用:L2 正则化参数,用于防止过拟合。
o 类型:浮点数。
o 默认值:0.0001。
• batch_size
o 作用:用于随机梯度下降的 minibatch 的大小。
o 类型:整数或 'auto'(使用样本数)。
o 默认值:'auto'。
• learning_rate
o 作用:控制学习率的更新方式。
o 可选值:
'constant':学习率保持不变。
'invscaling':随迭代次数调整。
'adaptive':当损失不再下降时,调整学习率。
o 默认值:'constant'。
• learning_rate_init
o 作用:初始学习率,用于 sgd 或 adam 优化算法。
o 类型:浮点数。
o 默认值:0.001。
• max_iter
o 作用:最大迭代次数。
o 类型:整数。
o 默认值:200。
• random_state
o 作用:控制随机数生成,用于模型初始化和数据打乱。
o 类型:整数或 None。
o 默认值:None。
• tol
o 作用:优化算法的容忍度(停止标准)。
o 类型:浮点数。
o 默认值:1e-4。
• verbose
o 作用:是否输出训练过程的信息。
o 类型:布尔值。
o 默认值:False。
________________________________________
2. train_test_split 函数
用于划分训练集和测试集。
主要参数及其说明
• test_size
o 作用:测试集占总数据集的比例。
o 类型:浮点数或整数。
o 默认值:None(使用 train_size)。
• train_size
o 作用:训练集占总数据集的比例。
o 类型:浮点数或整数。
o 默认值:None。
• stratify
o 作用:按比例分层采样,确保训练集和测试集中类别分布一致。
o 类型:数组或 None。
o 默认值:None。
• random_state
o 作用:随机种子,保证划分结果可复现。
o 类型:整数或 None。
o 默认值:None。
________________________________________
3. cross_val_score 函数
用于进行交叉验证评估。
主要参数及其说明
• estimator
o 作用:模型对象。
o 类型:任何 scikit-learn 模型。
• X 和 y
o 作用:训练数据和目标值。
• cv
o 作用:交叉验证的折数。
o 类型:整数或交叉验证生成器。
o 默认值:None(使用 5 折)。
• scoring
o 作用:指定评估指标。
o 类型:字符串或可调用对象。
o 默认值:None(使用默认评分)。
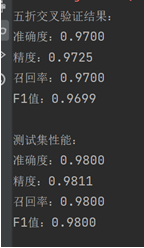
3. 训练结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
四、实验结果分析
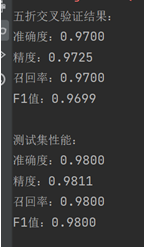
1. 测试结果截图(包括:准确率、精度(查准率)、召回率(查全率)、F1)
2. 对比分析
表现对比: 测试集上的性能指标(准确度、精度、召回率、F1 值)均比五折交叉验证结果略高,说明模型在测试集上表现更加优秀。
泛化能力: 五折交叉验证的结果已经表明模型在训练集上有较好的性能,而测试集的优异表现进一步验证了模型的泛化能力,能够处理新数据而不出现明显的过拟合。
可能的原因:
数据分布一致性:训练集和测试集具有相似的数据分布,因此测试集性能略高。
样本数量:iris 数据集样本量较小,模型可能对数据特征较好地拟合,从而在测试集上表现良好。
