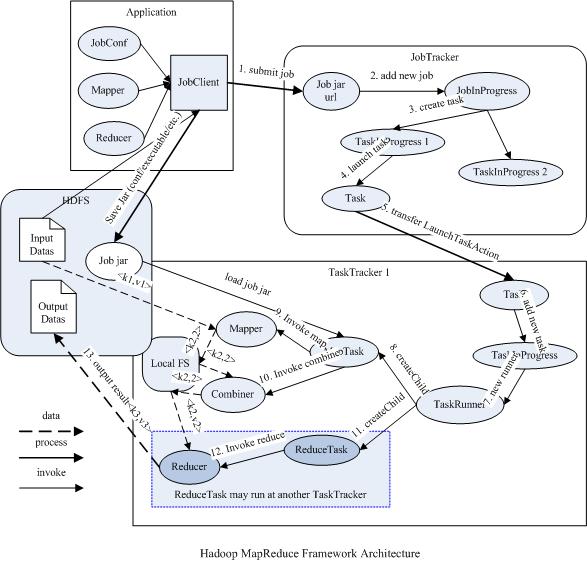
MapReduce过程的框架结构
总体结构
Mapper和Reducer
运行于Hadoop的MapReduce应用程序最基本的组成部分包括一个Mapper和一个Reducer类,以及一个创建JobConf的执行程序,在一些应用中还可以包括一个Combiner类,它实际也是Reducer的实现。
JobTracker和TaskTracker
它们都是由一个master服务JobTracker和多个运行于多个节点的slaver服务TaskTracker两个类提供的服务调度的。master负责调度job的每一个子任务task运行于slave上,并监控它们,如果发现有失败的task就重新运行它,slave则负责直接执行每一个task。TaskTracker都需要运行在HDFS的DataNode上,而JobTracker则不需要,一般情况应该把JobTracker部署在单独的机器上。
JobClient
每一个job都会在用户端通过JobClient类将应用程序以及配置参数Configuration打包成jar文件存储在HDFS,并把路径提交到JobTracker的master服务,然后由master创建每一个Task(即MapTask和ReduceTask)将它们分发到各个TaskTracker服务中去执行。(这各过程中有一个本地到HDFS的上传过程。在此处,路径为jar文件(程序文件)、用于计算的数据文件在HDFS中的路径。)
JobInProgress
JobClient提交job后(job提交到了master),JobTracker(master上的JobTrack)会创建一个JobInProgress来跟踪和调度这个job,并把它添加到job队列里。JobInProgress会根据提交的job jar中定义的输入数据集(已分解成FileSplit)创建对应的一批TaskInProgress用于监控和调度MapTask,同时在创建指定数目的TaskInProgress用于监控和调度ReduceTask,缺省为1个ReduceTask。(其中JobInProgress和TaskInProgress都运行在master上,其中JobInProgres监控master上的TaskInProgress。master上的TaskInProgress监控Task,这些Task会被分发到各个slave中,这个分发过程是通过TaskInProgess序列化的写入TaskTrack实现的。)
TaskInProgress
JobTracker启动任务时通过每一个TaskInProgress(master上的TaskInProgress)来launchTask,这时会把Task对象(即MapTask和ReduceTask)序列化写入相应的TaskTracker服务中,TaskTracker收到后会创建对应的TaskInProgress(此TaskInProgress实现非JobTracker中使用的TaskInProgress,作用类似)用于监控和调度该Task。启动具体的Task进程是通过TaskInProgress管理的TaskRunner对象来运行的。TaskRunner会自动装载job jar,并设置好环境变量后启动一个独立的java child进程来执行Task,即MapTask或者ReduceTask,但它们不一定运行在同一个TaskTracker中。(此处的TaskInProgress是有slave中的TaskTrack创建,作用是监视Task中正真运行的Task(即TaskRunner,以及因此产生的MapperTask和ReducerTask))
MapTask和ReduceTask
一个完整的job会自动依次执行Mapper、Combiner(在JobConf指定了Combiner时执行)和Reducer,其中Mapper和Combiner是由MapTask调用执行,Reducer则由ReduceTask调用,Combiner实际也是Reducer接口类的实现。Mapper会根据job jar中定义的输入数据集按<key1,value1>对读入,处理完成生成临时的<key2,value2>对,如果定义了Combiner,MapTask会在Mapper完成调用该Combiner将相同key的值做合并处理,以减少输出结果集。MapTask的任务全完成即交给ReduceTask进程调用Reducer处理,生成最终结果<key3,value3>对。这个过程在下一部分再详细介绍。
下图描述了Map/Reduce框架中主要组成和它们之间的关系: