Kaggle实战之一回归问题
0. 前言
- “尽管新技术新算法层出不穷,但是掌握好基础算法就能解决手头 90% 的机器学习问题。”
-
1.任务描述
- 预测任务:根据某时刻房价相关数据,预测区域内该时刻任一街区的平均房价,决定是否对投资该街区的房子。
- 评估函数:RMSE
评估函数:RMSE即损失函数,范数越大,越注重预测值误差大的样例
- 工具:ipython notebook
2.数据概览
整体概况
用 python 的pandas包导入样本数据,查看前五行,每一行表示一个街区,包含十项数据特征:
| 经度 | 维度 | 房龄 | 房间数 | 卧室数 | 人口数 | 家庭数 | 收入 | 房价 | 临海 |
|---|---|---|---|---|---|---|---|---|---|
| -122.23 | 37.88 | 41 | 880 | 129 | 322 | 126 | 8.3252 | 452600 | NEAR BAY |
| -122.22 | 37.86 | 21 | 7099 | 1106 | 2401 | 1138 | 8.3014 | 358500 | NEAR BAY |
| -122.24 | 37.85 | 52 | 1467 | 190 | 496 | 177 | 7.2574 | 352100 | NEAR BAY |
| -122.25 | 37.85 | 52 | 1274 | 235 | 558 | 219 | 5.6431 | 341300 | NEAR BAY |
| -122.25 | 37.85 | 52 | 1627 | 280 | 565 | 259 | 3.8462 | 342200 | NEAR BAY |
其中房价一列实际是此次任务的 label, 查看数据基本情况:
RangeIndex: 20640 entries, 0 to 20639
Data columns (total 10 columns):
longitude 20640 non-null float64
latitude 20640 non-null float64
housing_median_age 20640 non-null float64
total_rooms 20640 non-null float64
total_bedrooms 20433 non-null float64
population 20640 non-null float64
households 20640 non-null float64
median_income 20640 non-null float64
median_house_value 20640 non-null float64
ocean_proximity 20640 non-null object
dtypes: float64(9), object(1)
可以看到一共有 20640 行记录,注意到其中 total_rooms 属性有207行缺失,ocean_proximity 属性是 object 类型,查看该属性的统计情况:
<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
对9项数值型属性画直方图,感受下每个属性的分布情况:
可以看到 housing_median_age、median_house_value、median_income 有明显的翘尾情况,说明这三个属性在数据收集阶段,做过被截断处理。median_house_value 作为此次任务的预测目标值,它的截断处理在实际情况中可能是个问题,因为它意味着你模型的预测值可能无法超过这个上限。上图还可以看出有四项属性属于“长尾分布”的情况,一般来说,机器学习的模型更喜欢类似正态分布的“钟型”特征。
可视化
人脑非常擅长图像视觉的信息处理。用经度纬度确定地理位置,用圆圈大小表示人口数量,用热力图表示房价高低,再从外部导入一张经纬度吻合的地图,可以得到一张可视化的数据图:

可以看到海景房房价普遍偏高,但是北部区域是个例外,说明临海距离应该是个很好的特征。另外,人口聚集地中心区域,房价也相应偏高,是不是做聚类之后,计算到聚类中心的距离也是一个很好的特征呢?
相关性计算
相关性既包括特征与label的相关性,也包括特征之间的相关性。首先看特征与 label 之间的皮尔逊系数:
median_income 0.687160
total_rooms 0.135097
housing_median_age 0.114110
households 0.064506
total_bedrooms 0.047689
population -0.026920
longitude -0.047432
latitude -0.142724
观察房价与收入的二维图:
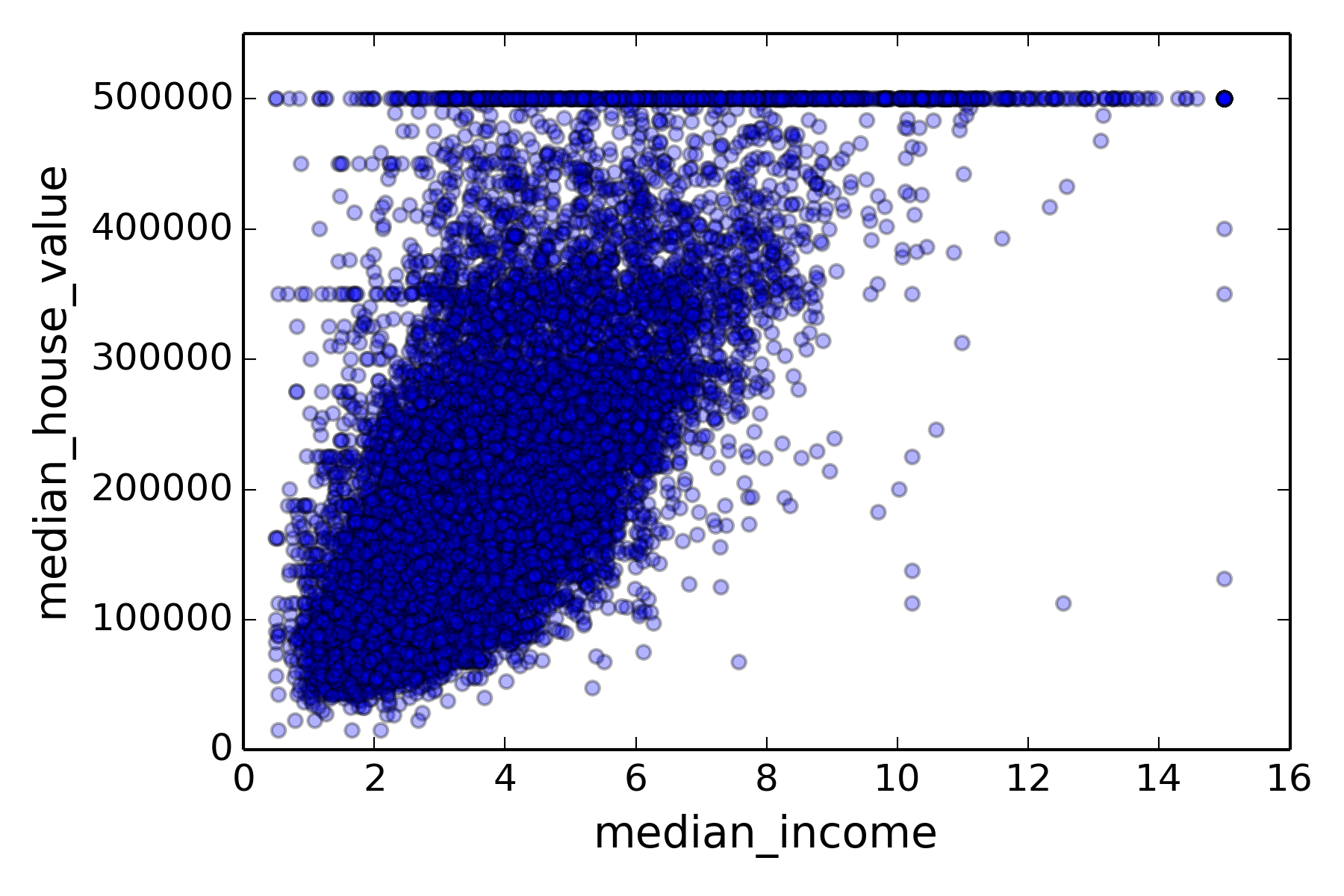
总体上,房价与收入具有很强的相关性,收入越高,该地区的房价也越高。但是也有一些收入较高,但是房价很低,或者收入较低,房价奇高的点,可能是异常点,需要从训练数据中去除。
3. 数据准备
随机采样
测试集从数据集中分离而来,大小一般设置为全部数据的20%。分离的办法可以随机取,有点是采样均匀,缺点是每次取出的测试集可能不一样。要克服这个缺点,在随机取的时候,可以固定随机数种子。其他的方法还有根据某列属性的尾号或者 md5 来划分,优点是每次运行的测试集是固定的,确定是要确保尾号或者 md5 数值是均匀分布的,并且与 label 不存在相关性。在工业界,上线算法ab分桶时,常常也用类似的方法,比如按照用户id尾号分流、按照用户id的md5分流等,特别要注意未登录用户的分桶情况,因为未登录用户与点击率是有相关性的。
分组按比例随机采样
随机产生测试集,可能有的一个弊端是,重要属性的部分区间可能丢失。举个极端的例子,在所有分类模型中,label是最重要的属性,假设100个样本中只有2个正样本,则有很大概率训练样本全部是负样本。这个任务中,median_income 属性是决定房价的一个重要特征,在直方图中,可以看到收入大于7.5的样本已经比较稀疏了。如果完全按照随机采样方法产生训练样本和测试样本,有可能训练样本中完全不包含收入大于7.5的样本,这对于模型训练是很不利的。
解决的方法很简单,将 median_income 进行分组,每组里面按照0.2的比例抽取测试样本。分组的时候,注意每组里面样本数量不能太少,可以参考如下处理方法:
group = ceil(min(median\_income,7.5) / 1.5)
将 median_income 分为5组,每组按比例采样,这样处理的结果是,测试样本在 median_income 的分布,比当做整体(一组)完全随机采样的方法,更符合整体分布。
数据预处理
- 空值处理:数据清洗包括,total_rooms 用中位数代替,ocean_proximity 用one-hot-encode编码转为数值型,one-hot-encode与直接编码为 [0,1,2,3..] 相比,不会引入相似或者相近的意义。比如 2 和 3 在数值上相近,但是它们各自表示的NEAR BAY与INLAND属性项并不存在实质的相似关系(尽管有这个可能)。
- 构造特征:数据集里因为不同district里户数不同,所以 total_rooms、total_bedrooms、population 这些属性可能没有太大的意义,而每户的房间数、卧室数、人数相关性则较,所有在数据集中可以新增这些特征。
- 归一化:数值型特征的一个特点是,不同的属性取值范围差别极大,对模型学习、正则项设置不利。有两种简单的方法可以应对这种情况:变换到0-1区间的归一化或者标准正态分布。前者对异常点非常敏感,如果存在某个值比正常值区间距离很远,这种处理会导致正常数据点分布过于集中;后者对过于集中的数据分布敏感,如果原数据集方差很小,除以近0的数值容易导致精度失真。
- 偏度处理:在大部分数值型特征中,通常分布不符合正态分布,而是类似于“长尾”。例如房价中,低价占大部分,豪宅属于小部分。应对这种数据分布,一般可以通过神奇的log化处理转化类近似正态分布。
4. 模型训练
训练集和测试集
先用线性回归模型在训练集上训练,然后用训练好的模型再次预测训练集的label,计算RMSE为6.8w刀,MAE误差为4.9w刀,模型明显underfitting。解决的方法有:用复杂模型、用更好的特征、用更弱的约束。
改用决策树模型进行训练,得到训练集的误差为0.0,在测试集中误差极大 。在回归问题里,百分百完全预测准确基本是不可能的,说明模型存在过拟合现象。解决的方法有:用简单模型、用更大的数据量、更强的约束、ensemble方法等。为了更好评估过拟合情况,可以用 K-fold 进行交叉验证。基本过程如下:把全部数据集随机分成K份,每次挑选其中K-1份训练数据,剩下一份作为测试集计算误差,总共重复K次。相比于只划分一份训练集和测试集,这种方法更加健壮。
随机森林模型是多个决策树模型ensemble后的结果,比单个决策树模型具有更强抗overfitting的能力。改用随机森林模型进行训练,发现结果好得多,但是测试集误差依旧远远大于训练集误差,说明模型还需要更强的约束。为了找到较好的约束参数,可以采用grid search方法。
grid search
模型的超参可能有多个,每个有多种选择,由此形成了参数网格grid。前面讲过用交叉验证的方法可以评估一个模型的效果,以上两种方法结合,可以让模型遍历每个网格点,用交叉验证的方法得到该网格点的模型预测误差,从而找到表现最好的模型。最终找的的较好超参是 max_features 为6,n_estimators 为 30, RMSE 49900。
5. kaggle实战
准确率top4%的 kenerl 地址链接,真实的数据集和本文以上描述有所区别
数据处理
- outliers直接用边界值去除,注意去除过程也是也风险的。
- 分析target分布,发现有偏斜,用log转化为近似正态分布
特征工程
- 空值处理。空值的处理方法要因地制宜,主要有:转换为某个固定字符串如“None”或者用0代替;以用近邻记录该特征的中位数代替;通过其他特征推断;用数据集中最常出现的值代替;部分可以移除等
- 类型转换。数值型特征可能表示category信息,统一转化为str类型。
- 编码。所有类别特征都转化为one hot encode,对于可能包含顺序关系的,额外添加label encode编码。
- 添加特征。在现有特征上,变换添加可能对预测目标有强关联的特征。
- Box-Cox变换。对偏度大于0.75的数值型特征进行Box-Cox变换(类似于log),转换为近正态分布。

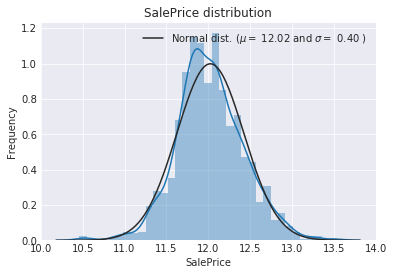
模型训练
- 先后应用LASSO Regression、Elastic Net Regression、Kernel Ridge Regression、Gradient Boosting Regression、XGBoost、LightGBM基础模型,注意部分模型对scale较敏感,应先经过RobustScaler处理。
Stacking models
- 最简单的方法,以上模型预测值取平均,可以得到比单个模型好的预测效果。
- 次简单的方法,因为不同模型精度不一样,理应取不同的权重,上面直接取平均太粗暴,改用 regression 来训练权重。所以训练集还需要划分出一部分数据,用来训练lasso regression模型。
Ensembling
- 用 ElasticNet、KernelRidge、 GradientBoostingRegressor 做底层模型,用 lasso regression 来得到每个模型的权重,Stacking models RMSE loss:0.07815
- 用 XGBRegressor 单模型得分RMSE loss:0.07851
- 用 LGBMRegressor 单模型得分RMSE loss: 0.07194
- 最后拍个权重,求平均:stacked_pred*0.70 + xgb_pred*0.15 + lgb_pred*0.15 得到最终预测RMSE loss: 0.07524



 浙公网安备 33010602011771号
浙公网安备 33010602011771号