
【Python】【正则】
#正则表达式相关符号说明:https://www.cnblogs.com/huxi/archive/2010/07/04/1771073.html
#正则对字符串相关操作:https://www.cnblogs.com/amengduo/p/9586732.html
1、python xpath 正则匹配
匹配当前标签(i对象)中的a标签,满足条件:以http开始并且以allure结束的href标签
说明:
1.1、namespaces={"re": "http://exslt.org/regular-expressions"} 按照这样写上即可
1.2、.//a 标签当前对象下的a标签(这里的当前对象为tr_list列表中的i对象)
1.3、“.+”表示任意多个字符,“^”表示字符串开始位置,“$”表示字符串结束位置
for i in tr_list: report_url = i.xpath( r'.//a[re:match(@href, "^http.+allure$")]', namespaces={"re": "http://exslt.org/regular-expressions"} )

2、python正则工具

#!/usr/bin/env python # -*- coding: utf-8 -*- """ @Time :2021/9/26 14:29 @Author :维斯 @File :RegularTool.py @Version :1.0 @Function: """ import re class RegularTool: @staticmethod def space(target: str, is_del_start_end: bool = True, is_print: bool = False): """ 空格过滤(多个连续空格 替换为一个空格) :param target: 目标字符串 :param is_del_start_end: 是否删除字符串首尾的空格 :param is_print: 是否打印 """ ''' 1 多个连续空格 替换为1个空格 ''' if is_print: print(f'前:{target}') # 前: dsaj 带回家 交换 机 h j pattern1 = re.compile(' +') # 匹配1个或多个空格 new_str1 = re.subn(pattern1, ' ', target)[0] # 将匹配到的1个或多个空格 替换为1个空格 if is_print: print(f'后:{new_str1}') # 后: dsaj 带回家 交换 机 h j ''' 2 删除首尾空格 ''' if is_del_start_end: # 删除以空格开始的 pattern2_s = re.compile('^ +') new_str2_s = re.subn(pattern2_s, '', new_str1)[0] # 删除以空格结束的 pattern2_e = re.compile(' +$') new_str2_e = re.subn(pattern2_e, '', new_str2_s)[0] if is_print: print(f'删:{new_str2_e}') # 删:dsaj 带回家 交换 机 h j return new_str2_e return new_str1 if __name__ == '__main__': target_str = ' dsaj 带回家 交换 机 h j ' RegularTool.space(target_str, is_print=True)
前: dsaj 带回家 交换 机 h j
后: dsaj 带回家 交换 机 h j
删:dsaj 带回家 交换 机 h j
3、匹配IP
import re if __name__ == '__main__': str_a = 'hdfj复活甲678啊aa192.168.5.10576sdf防守打法' result = re.search(r'(([01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])\.){3}([01]{0,1}\d{0,1}\d|2[0-4]\d|25[0-5])', str_a) print(result.group()) # 192.168.5.105
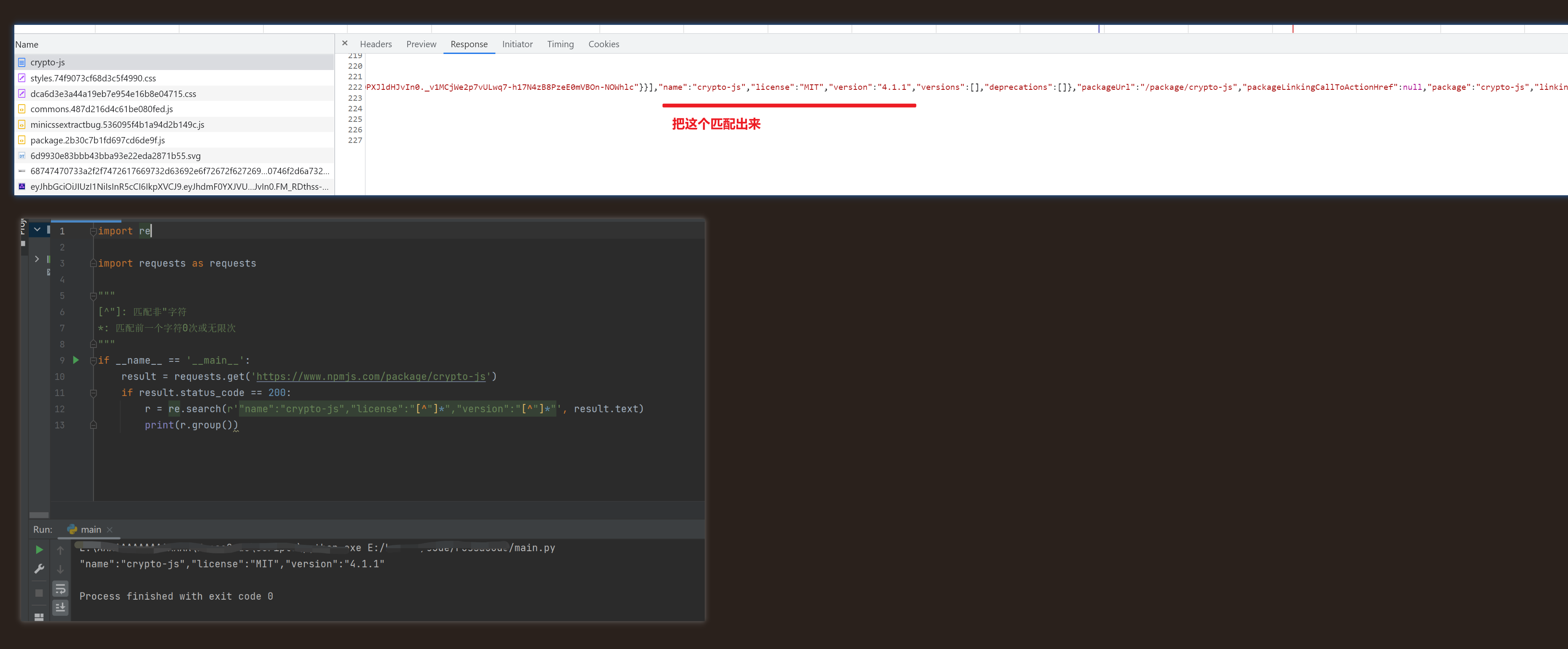
4、匹配指定数据
import re import requests as requests """ [^"]: 匹配非"字符 *: 匹配前一个字符0次或无限次 """ if __name__ == '__main__': result = requests.get('https://www.npmjs.com/package/crypto-js') if result.status_code == 200: r = re.search(r'"name":"crypto-js","license":"[^"]*","version":"[^"]*"', result.text) print(r.group())
如果忍耐算是坚强 我选择抵抗 如果妥协算是努力 我选择争取


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义