
【Python】【爬虫】+爬取新闻
参考文章:https://www.cnblogs.com/lizm166/p/9634306.html
破解参数(as ,cp,_cp_signature):https://blog.csdn.net/weixin_39416561/article/details/82111455
一、爬取今日头条的新闻
step1:获取新闻列表 找出要查找的新闻的ID
- url=https://www.toutiao.com/api/pc/feed/?category=news_hot&utm_source=toutiao&widen=1&max_behot_time=0&max_behot_time_tmp=0&tadrequire=true&as=A1552DAB860A86B&cp=5DB60AA876CB0E1&_signature=e9pbGAAAJm-CIbMXRdNvUHvaWw
- 动态参数:“_signature” (估计应该是按天的 每天请求都要用不同的值)
- 请求方式:GET
- 请求头:user-agent:加上自己对应的值即可(只需要添加这一个请求头即可)
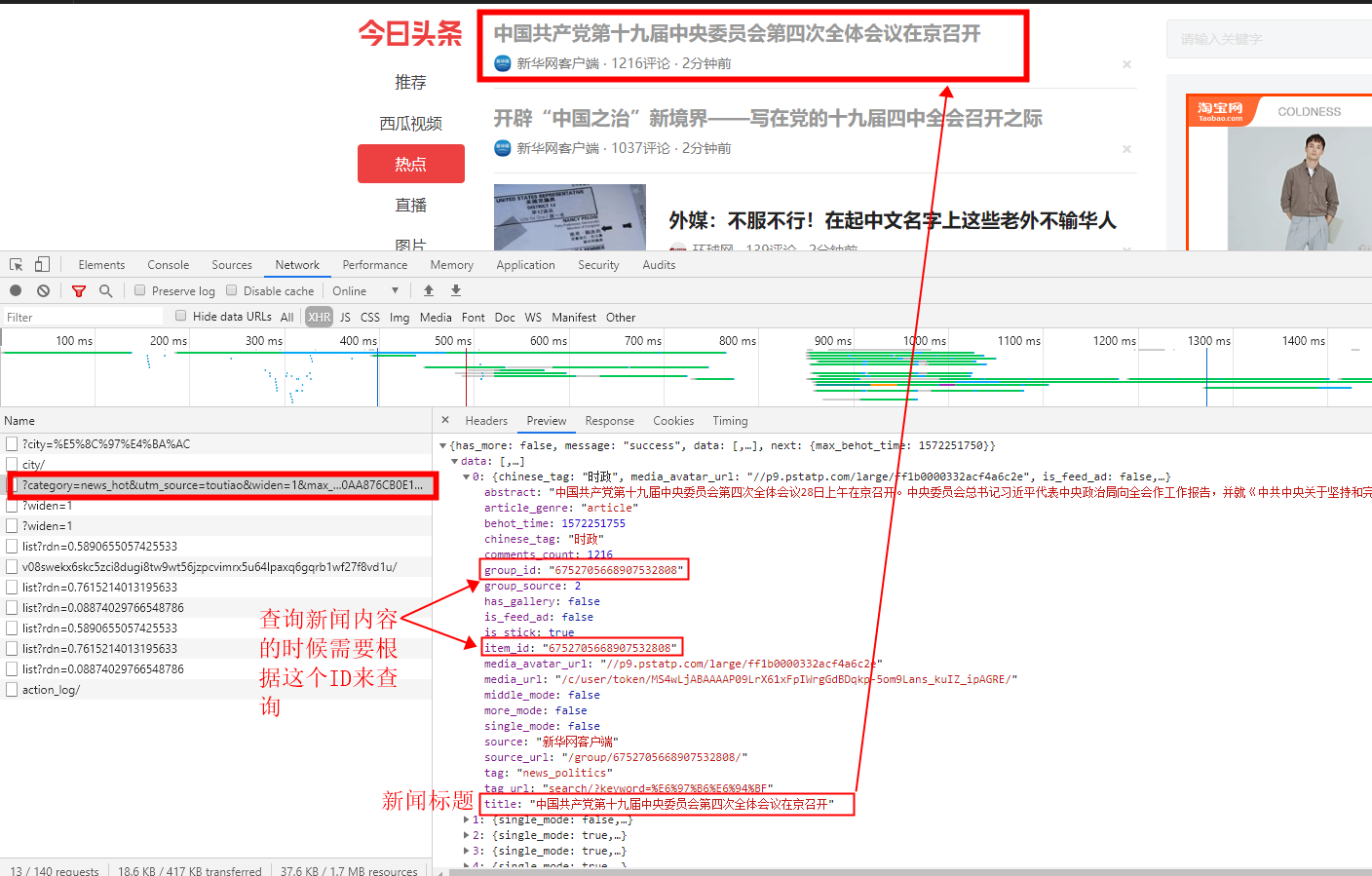
step2:根据新闻ID获取此新闻的详细数据
- 注意:ID前有个“a”、获取到的数据为HTML格式的
- url=https://www.toutiao.com/a6752705668907532808/
- 请求方式:GET
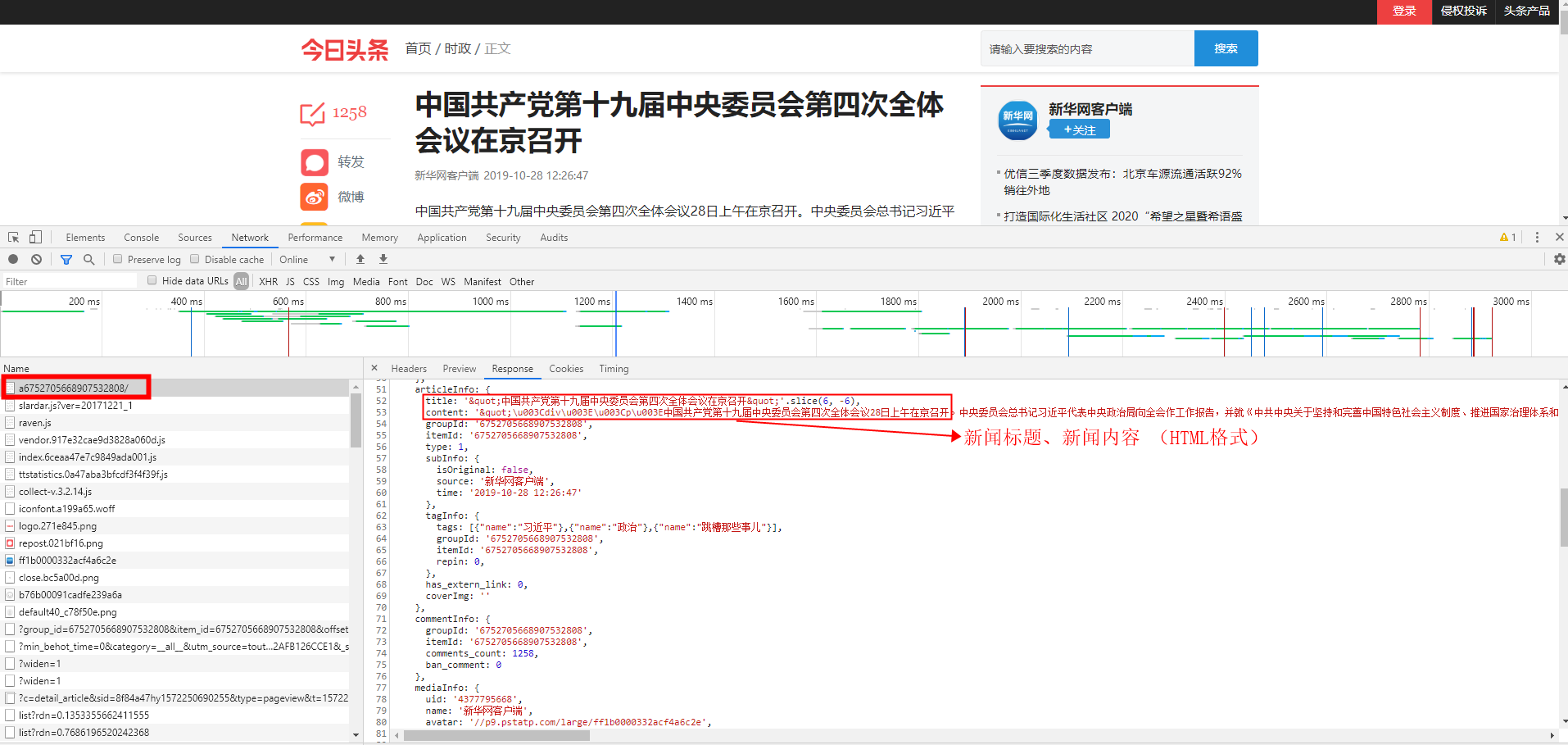
step3:解析HTML数据
把获取到的HTML信息中的数据解析
- 此新闻的链接(共需要查看时用)
- 此新闻的标题
- 此新闻的内容
如果忍耐算是坚强 我选择抵抗 如果妥协算是努力 我选择争取


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义