Paper:Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection
Paper:Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection
论文:Generating Hierarchical Explanations on Text Classification via Feature Interaction Detection
github:https://github.com/UVa-NLP/HEDGE
1. Introduction
- Generating explanations for neural networks, help understand the decision-making of black-box models
- Existing local explanation methods: provide important features which are words or phrases--ignore interactions between words and phrases
- This work: HEDGE, build hierarchical explanations by detecting feature interactions
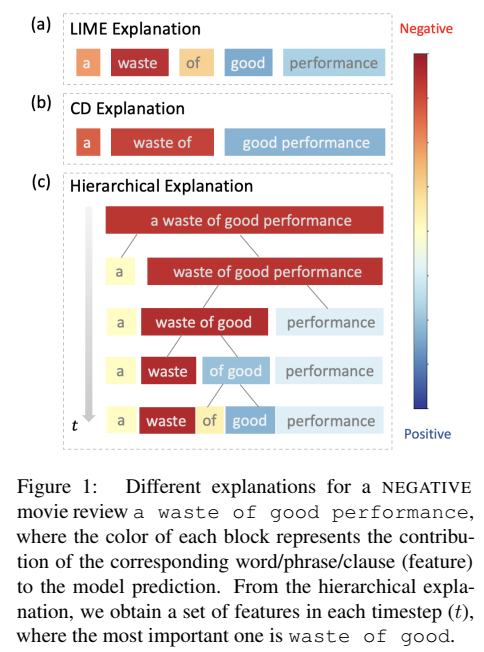
2. Contributions
- design a top-down model-agnostic method of constructing hierarchical explanations via feature interaction detection;
- propose a simple and effective scoring function to quantify feature contributions with respect to model predictions;
- compare the proposed algorithm with several competitive methods on explanation generation via both automatic and human evaluations.
3. Method
3.1 Building hierarchical explanations
-
Text classification task: let \(x = (x_1,\dots, x_n)\) denote a text with \(n\) words and \(\hat{y}\) be the prediction label from a well-trained model.
-
A partition of the word sequence with \(\cal P\) text spans
\[\cal P=\{x_{(0,s_1]},x_{(s_1,s_2]},\dots,x_{(s_{P-1},n]}\},\quad x_{(s_i,s_{i+1}]}=(x_{s_i+1},\dots,x_{s_{i+1}}) \] -
HEDGE: divide text span \(x_{(s_i,s_{i+1}]}\) into two smaller spans: \(x_{(s_i,j]}\) and \(x_{(j,s_{i+1}]}\) , \(j\) is the dividing point\((s_i<j<s_{i+1})\)

Two crucial questions need to be addressed:
- which text span the algorithm should pick to split?
- where is the dividing point?
\(\phi(x_{(s_i,j]},x_{(j,s_{i+1}]}\vert \cal P)\): interaction score
\(\psi(\cdot)\): the feature importance function. Evaluate the contributions of new spans and update the contribution set \(C\).
3.2 Detecting feature interaction
-
Consider the effects of other text spans when calculate the interaction between (the interaction between two
words/phrases is closely dependent on the context )![]()
-
Reduce computational complexity into polynomial: only consider m neighbor text spans
![]()

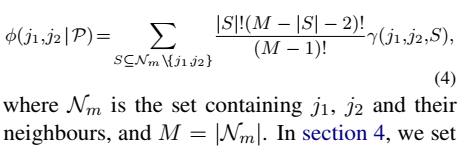
3.3 Quantifying feature importance
-
Measure the contribution of a feature \(x_{(s_i,s_{i+1}]}\) to the model prediction, define the importance score as
![]()
This importance score measures how far the prediction on a given feature is to the prediction boundary, hence the confidence of classifying \(x_{(s_i,s_{i+1}]}\) into the predicted label \(\hat{y}\).
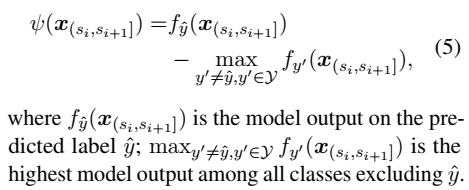
4. Experiments
4.1 Setup
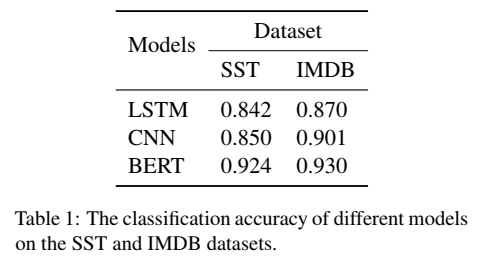
- Task: text classification
- Model: LSTM, CNN, BERT
- Benchmark: SST, IMDB
4.2 Quantitative Evaluation
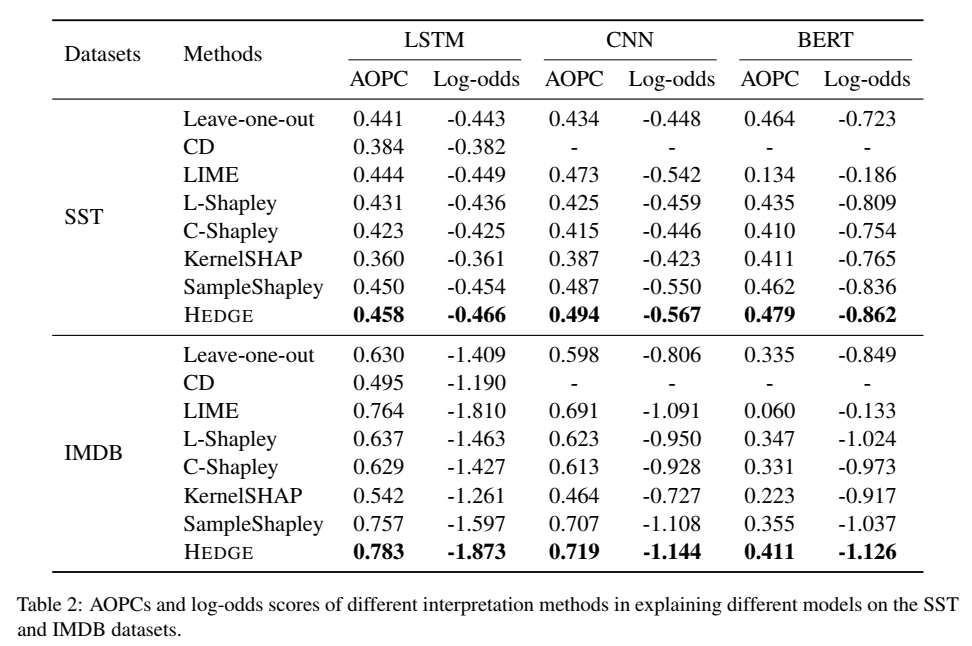
The first two metrics measure local fidelity by deleting or masking top-scored words and comparing the probability change on the predicted label.
-
AOPC (the area over the perturbation curve): By deleting top k% words, AOPC calculates the average change in the prediction probability on the predicted class over all test data.
![]()
Higher AOPCs are better, which means that the deleted words are important for model prediction.
-
Log-odds: Log-odds score is calculated by averaging the difference of negative logarithmic probabilities on the predicted class over all of the test data before and after masking the top r% features with zero paddings.
![]()
Lower log-odds scores are better.


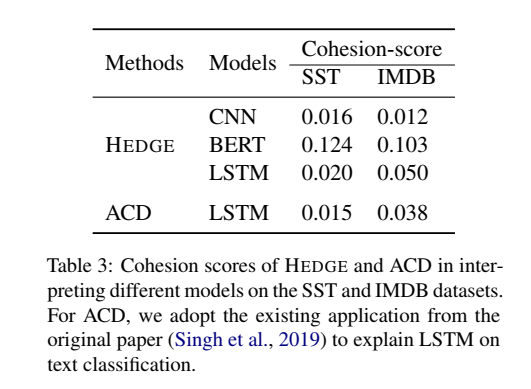
The cohesion-score measures the synergy of words within a text span to the model prediction by shuffling the words to see the probability change on the predicted label.
-
Cohesion-score: We propose cohesion-score to justify an important text span identified by HEDGE.
Given an important text span \(x_{(a,b]}\), randomly pick a position in the word sequence \((x_1,\dots,x_a,x_{b+1},\dots,x_n)\) and insert a word back, until construct a shuffled version of the original sentence \(\bar{x}\).
![]()
the words in an important text span have strong interactions, after perturbing, the output probability decreasing.
Higher cohesion-scores are better.

Results:
4.3 Qualitative Analysis
-
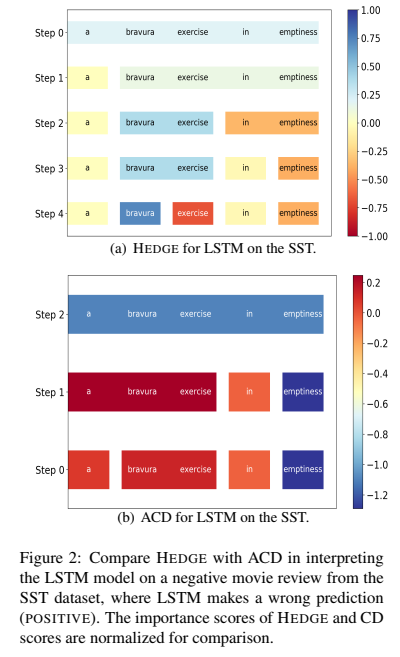
Example 1: compare HEDGE with ACD in interpreting the LSTM model
![]()
-
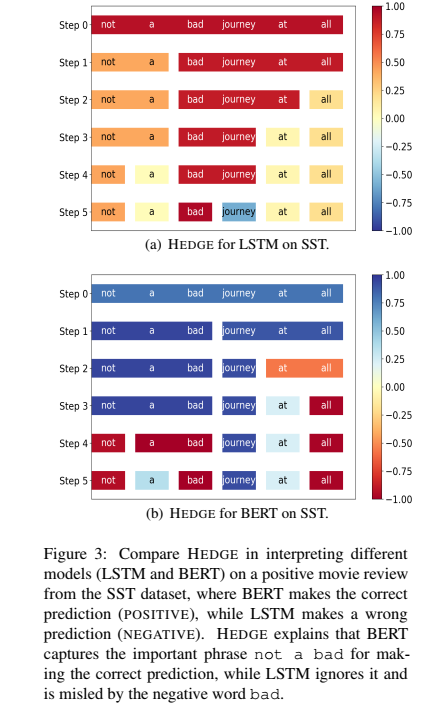
Example 2: compare HEDGE in interpreting two different models (LSTM and BERT)
![]()
4.4 Human Evaluation
We had 9 human annotators from the Amazon Mechanical Turk (AMT) for human evaluation.
- Compare HEDGE with other baselines using the predictions made by the same LSTM model.
- Compare the explanations generated by HEDGE on three different models: LSTM, CNN,
and BERT.
We measure the number of human annotations that are coherent with the actual model predictions, and define the coherence score as the ratio between the coherent annotations and the total number of examples.
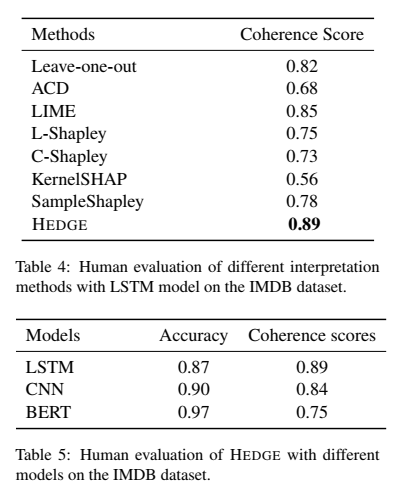
Results:
- HEDGE can capture important features which are highly consistent with human interpretations.
- BERT can achieve higher prediction accuracy than the other two models, its coherence score is lower, manifesting a potential tradeoff between accuracy and interpretability of deep models.
5. Conclusion
HEDGE is capable of explaining model prediction behaviors, which helps humans understand the decision-making

 浙公网安备 33010602011771号
浙公网安备 33010602011771号