
基于LSTM语言模型的文本生成
基于LSTM语言模型的文本生成
1. 文本生成
1.1 基于语言模型的文本生成
基于马尔科夫的语言模型且在数据驱动下的自然语言生成。利用数据和文字间的对齐语料,使用N-gram语言模型生成文本。在语言模型上加入句法分析(关系抽取、实体识别、依存句法、短语结构等)还可以显著改善生成效果。因为这些都建立在句子理解的基础上,文本生成的过程需要考虑历史信息,处理长距离的依赖关系情况,如语义连贯性。

标准定义:对于语言序列\(w_1,w_2,…… w_n\), 语言模型就是计算该序列出现的概率,即
也即是语言模型描述了这些单词组成这个语言序列(句子)的分率分布。
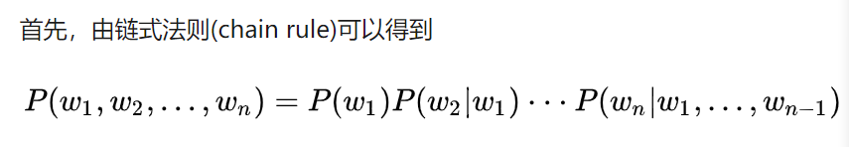
马尔可夫假设,当前词只依赖前面n-1个词。

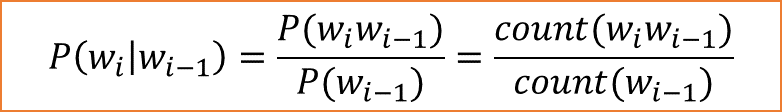
应用:
-
候选句打分。常应用在文本纠错、语音识别等场景中。比如
\[𝑃(𝐼\quad 𝑎𝑚\quad ℎ𝑎𝑝𝑝𝑦)>𝑃(𝐼\quad 𝑎𝑚\quad ℎ𝑎𝑝𝑝𝑒𝑛) \] -
文本生成。比如广告文案、机器人写作、机器翻译。
1.2 使用深度学习方法的文本生成
按照输入数据的区别,文本生成任务可以分成三类:文本到文本的生成,结构化数据生成文本,图像到文本的生成。
基于深度学习的文本生成,常用的是Seq2Seq模型(encoder-decoder)。利用Attention机制的Seq2Seq模型可以加强单词和特征之间的对齐,在生成文字的时候,模拟人看东西时关注点逐渐转移的过程,以生成更符合人习惯的文本。
1.3 Sampling问题
基于Seq2Seq模型的文本生成有各种不同的decoding strategy。文本生成中的decoding strategy主要可以分为两大类:
- Argmax Decoding: 主要包括beam search, class-factored softmax等
- Stochastic Decoding: 主要包括temperature sampling, top-k sampling等。
在Seq2Seq模型中,RNN Encoder对输入句子进行编码,生成一个大小固定的hidden state ;基于输入句子的hidden state \(h_c\) 和先前生成的第1到t-1个词\(x_{1:t-1}\),RNN Decoder会生成当前第t个词的hidden state \(h_t\) ,最后通过softmax函数得到第t个词 \(x_t\) 的vocabulary probability distribution \(P(x|x_{1:t-1})\)。
两类decoding strategy的主要区别就在于,如何从vocabulary probability distribution \(P(x|x_{1:t-1})\)中选取一个词 \(x_t\) :
- Argmax Decoding的做法是选择词表中probability最大的词,即\(x_t=argmax\quad P(x|x_{1:t-1})\) ;
- Stochastic Decoding则是基于概率分布\(P(x|x_{1:t-1})\) 随机sample一个词 $x_t $,即 \(x_t \sim P(x|x_{1:t-1})\) 。
在做seq predcition时,需要根据假设模型每个时刻softmax的输出概率来sample单词,合适的sample方法可能会获得更有效的结果。
1.3.1 贪婪采样
-
Greedy Search
核心思想:每一步取当前最大可能性的结果,作为最终结果。
具体方法:获得新生成的词是vocab中各个词的概率,取argmax作为需要生成的词向量索引,继而生成后一个词。
-
Beam Search
核心思想: beam search尝试在广度优先基础上进行进行搜索空间的优化(类似于剪枝)达到减少内存消耗的目的。
具体方法:在decoding的每个步骤,我们都保留着 top K 个可能的候选单词,然后到了下一个步骤的时候,我们对这 K 个单词都做下一步 decoding,分别选出 top K,然后对这 K^2 个候选句子再挑选出 top K 个句子。以此类推一直到 decoding 结束为止。当然 Beam Search 本质上也是一个 greedy decoding 的方法,所以我们无法保证自己一定可以得到最好的 decoding 结果。
Greedy Search和Beam Search存在的问题:
- 容易出现重复的、可预测的词;
- 句子/语言的连贯性差。
1.3.2 随机采样
核心思想: 根据单词的概率分布随机采样。
-
Temperature Sampling:
具体方法:在softmax中引入一个temperature来改变vocabulary probability distribution,使其更偏向high probability words:
\[P(x|x_{1:t-1})=\frac{exp(u_t/temperature)}{\sum_{t'}exp(u_{t'}/temperature)},temperature\in[0,1) \]另一种表示:假设\(p(x)\)为模型输出的原始分布,给定一个 temperature 值,将按照下列方法对原始概率分布(即模型的 softmax 输出) 进行重新加权,计算得到一个新的概率分布。
\[\pi(x_{k})=\frac{e^{log(p(x_k))/temperature}} {\sum_{i=1}^{n}e^{log(p(x_i))/temperature}},temperature\in[0,1) \]当\(temperature \to 0\),就变成greedy search;当\(temperature \to \infty\),就变成均匀采样(uniform sampling)。详见论文:The Curious Case of Neural Text Degeneration
-
Top-k Sampling:
可以缓解生成罕见单词的问题。比如说,我们可以每次只在概率最高的50个单词中按照概率分布做采样。我只保留top-k个probability的单词,然后在这些单词中根据概率做sampling。
核心思想:对概率进行降序排序,然后对第k个位置之后的概率转换为0。
具体方法:在decoding过程中,从 \(P(x|x_{1:t-1})\) 中选取probability最高的前k个tokens,把它们的probability加总得到 \(p'=\sum P(x|x_{1:t-1})\) ,然后将 \(P(x|x_{1:t-1})\) 调整为 \(P'(x|x_{1:t-1})=P(x|x_{1:t-1})/p'\) ,其中 \(x\in V^{(k)}\)! ,最后从 \(P'(x|x_{1:t-1})\) 中sample一个token作为output token。详见论文:Hierarchical Neural Story Generation
但Top-k Sampling存在的问题是,常数k是提前给定的值,对于长短大小不一,语境不同的句子,我们可能有时需要比k更多的tokens。
-
Top-p Sampling (Nucleus Sampling ):
核心思想:通过对概率分布进行累加,然后当累加的值超过设定的阈值p,则对之后的概率进行置0。
具体方法:提出了Top-p Sampling来解决Top-k Sampling的问题,基于Top-k Sampling,它将 \(p'=\sum P(x|x_{1:t-1})\) 设为一个提前定义好的常数\(p'\in(0,1)\) ,而selected tokens根据句子history distribution的变化而有所不同。详见论文:The Curious Case of Neural Text Degeneration
本质上Top-p Sampling和Top-k Sampling都是从truncated vocabulary distribution中sample token,区别在于置信区间的选择。
随机采样存在的问题:
- 生成的句子容易不连贯,上下文比较矛盾。
- 容易生成奇怪的句子,出现罕见词。
2. RNN技术选型
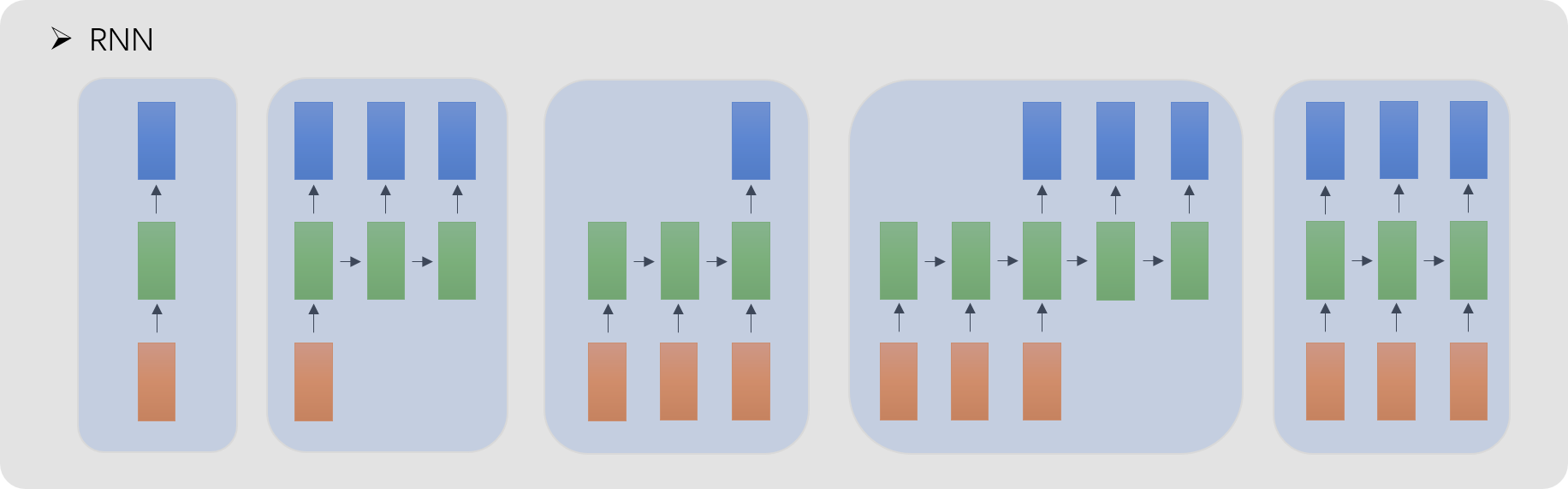
应用:
- 点对点 :特征到特征,特征变换
- 点到面:图像文本生成,图像描述(图像到文本的生成)
- 序列分类:文本分类(结构化数据生成文本),多模态文本分类
- 适用序列不对齐,长度不相等,没有一一对应关系:机器翻译(通过调节Encoder-Decoder隐含层的长度来控制输出长度不同)(文本到文本的生成)
- 适用序列里一一对应:序列标注,NER(文本到文本的生成)
3. 实战:基于字符使用LSTM生成文本
- data_utils.py:数据预处理:产生批数据、构建word2id词典。
- model.py:构建多层LSTM堆叠的模型,定义采样函数temperature sampling、top-k sampling。
- train.py:主要是训练LSTM模型,流程包括读取训练文本、加载/生成词典、生成批数据、定义模型框架和模型训练。
- inference.py:根据训练好的LSTM模型,给出一小段文本,通过反复采样下一个字符/单词,生成固定长度的文本。
3.1 如何生成序列数据
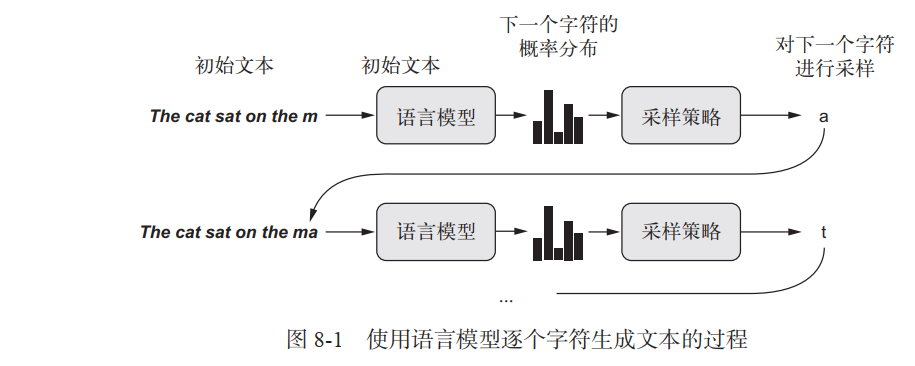
用深度学习生成序列数据的通用方法,就是使用前面的标记作为输入,训练一个网络(通常是循环神经网络或卷积神经网络)来预测序列中接下来的一个或多个标记。例如,给定输入the cat is on the ma,训练网络来预测目标 t,即下一个字符。与前面处理文本数据时一样, 标记( token)通常是单词或字符,给定前面的标记,能够对下一个标记的概率进行建模的任何网络都叫作语言模型( language model)。语言模型能够捕捉到语言的潜在空间( latent space),即语言的统计结构。
一旦训练好了这样一个语言模型,就可以从中采样( sample,即生成新序列)。向模型中输入一个初始文本字符串[即条件数据( conditioning data)],要求模型生成下一个字符或下一个单词(甚至可以同时生成多个标记),然后将生成的输出添加到输入数据中,并多次重复这一过程(见图 8-1)。这个循环可以生成任意长度的序列,这些序列反映了模型训练数据的结构,它们与人类书写的句子几乎相同。
在实战示例中,我们将会用到一个 LSTM 层,向其输入从文本语料中提取的 N 个字符组成的字符串,然后训练模型来生成第 N+1 个字符。模型的输出是对所有可能的字符做 softmax,得到下一个字符的概率分布。这个 LSTM 叫作字符级的神经语言模型( character-level neural language model)。
3.2 采样策略
生成文本时,如何选择下一个字符至关重要。
-
贪婪采样( greedy sampling),就是始终选择可能性最大的下一个字符。但这种方法会得到重复的、可预测的字符串,看起来不像是连贯的语言。
-
随机采样( stochastic sampling),在采样过程中引入随机性,即从下一个字符的概率分布中进行采样。这种从模型的softmax输出中进行概率采样的方法有一个问题:在采样过程中无法控制随机性的大小。假设\(p(x)\)为模型输出的原始分布,则基于softmax采样得到的新分布:
\[\pi(x_{k})=\frac{e^{log(p(x_k))}}{\sum_{i=1}^{n}e^{log(p(x_i))}} \]在这种情况下,根据模型结果,如果下一个字符是 e 的概率为0.3,那么你会有 30% 的概率选择它。注意,贪婪采样也可以被看作从一个概率分布中进行采样,即某个字符的概率为 1,其他所有字符的概率都是 0 。
为了在采样过程中控制随机性的大小,我们引入一个叫作 softmax 温度( softmax temperature)的参数,用于表示采样概率分布的熵,即表示所选择的下一个字符会有多么出人意料或多么可预测。给定一个 temperature 值,将按照下列方法对原始概率分布(即模型的 softmax 输出) 进行重新加权,计算得到一个新的概率分布。
\[ \pi(x_{k})=\frac{e^{log(p(x_k))/temperature}} {\sum_{i=1}^{n}e^{log(p(x_i))/temperature}},temperature\in[0,1) \]更高的temperature得到的是熵更大的采样分布,会生成更加出人意料、更加无结构的生成数据,而更低的temperature对应更小的随机性,以及更加可预测的生成数据。

3.3 实现字符级的LSTM文本生成
文本序列生成的程序流程:
-
准备并解析初始样本
-
读取训练样本
-
加载/生成词典
建立word2index,index2word表。
-
数据预处理:生成批次(Batch generation)
数据格式的预处理:batch_generator(data, batch_size, n_steps).
数据的连续采样,要求相邻批次的序列是连续的。需要设置一个批次/周期内的序列个数(batch_size)以及每个序列中所含字符数(n_steps),这样可以得到一个批次/周期数量。
def batch_generator(data, batch_size, n_steps): data = copy.copy(data) batch_steps = batch_size * n_steps n_batches = int(len(data) / batch_steps) data = data[:batch_size * n_batches] data = data.reshape((batch_size, -1)) while True: np.random.shuffle(data) for n in range(0, data.shape[1], n_steps): x = data[:, n:n + n_steps] y = np.zeros_like(x) y[:, :-1], y[:, -1] = x[:, 1:], x[:, 0] yield x, y
假设训练集含有30个字符,调用batch_generator(data, 2, 6).

每个batch的行数就是每个周期的句子数,列数就是 len(data) // batch_size得到的数值。
\[batch\_size=2:\begin{cases} [[\overbrace{0.,1.,2.,3.,4.,5.},\overbrace{6.,7.,8.,9.,10.,11.},12.,13.,14.],\\ [\underbrace{15.,16.,17.,18.,19.,20.},\underbrace{21.,22.,23.,24.,25.,26.},27.,28.,29.]] \end{cases} \] -
构建神经网络模型
这个网络是由多层LSTM堆叠组成,然后根据所有时刻的输出lstm_outputs,对词典中所有词的softmax得到概率。
-
训练语言模型并采样
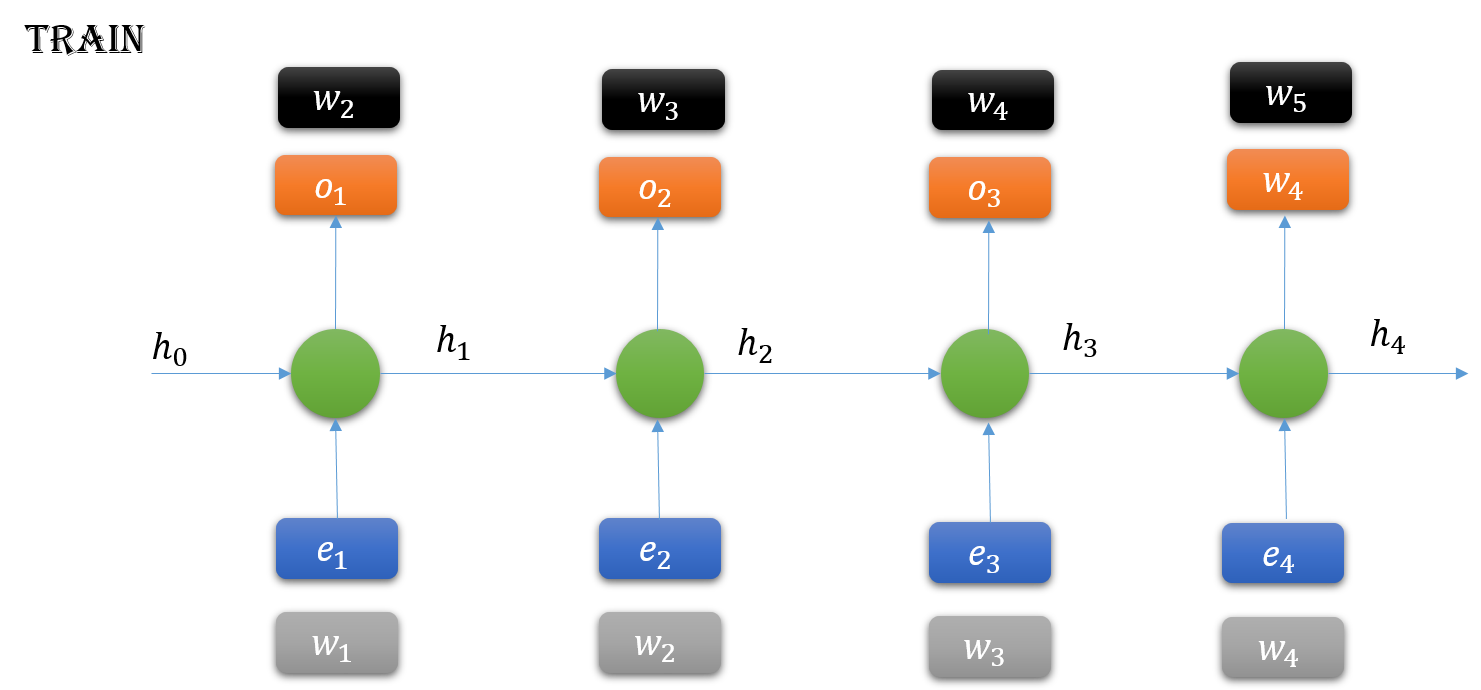
采样策略:贪婪采样,随机采样
采样函数可以选择Temperature Sampling或Top-k Sampling,分别根据模型得到的原始概率分布进行重新加权或限定top-k个概率构建新的概率分布,并从中抽取一个字符索引。
-
用模型生成文本
给定一个训练好的模型和一个种子文本片段,可以通过重复以下操作生成新的文本。
- 给定目前已生成的文本,从模型中得到下一个字符的概率。
- 根据某个温度对分布进行重新加权。
- 根据重新加权后的分布对下一个字符进行随机采样。
- 将新字符添加至文本末尾。
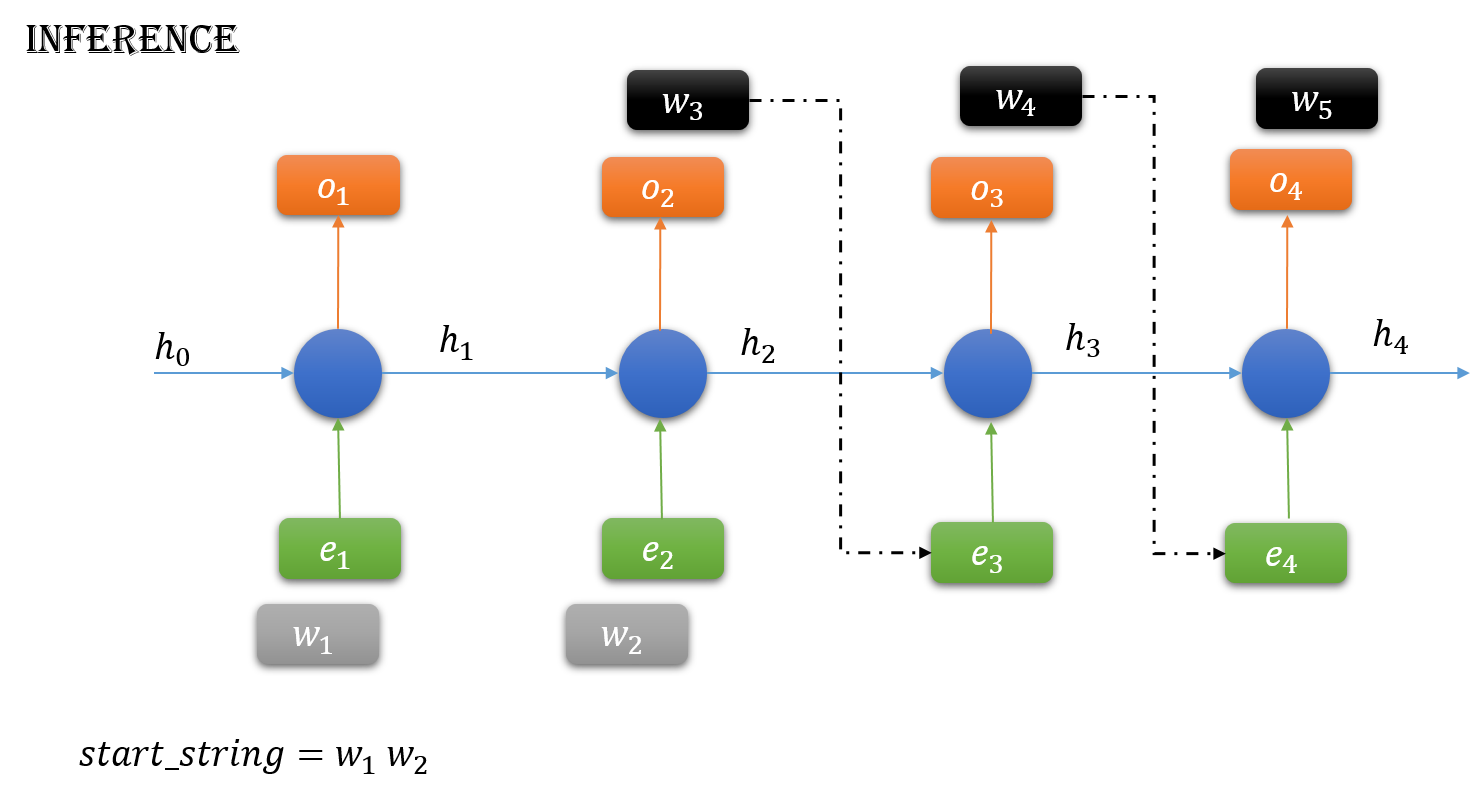
3.4 模型评价
如何对生成的文本进行评价也是文本生成研究中重要的一环。
3.4.1 文本内在评价
内在评价关注文本的正确性、流畅度和易理解性。常见的内在评价方法又可分为两类:1)采用BLEU、NIST和ROUGE等进行自动化评价,评估生成文本和参考文本间相似度来衡量生成质量。2)通过人工评价,从有用性等对文本进行打分。
-
BLEU
找出输出句子与参考句子之间的 n-gram重叠部分并对(比参考句子)更短的输出句子施以惩罚的评价方法。
论文地址:BLEU: a Method for Automatic Evaluation of Machine Translation
-
NIST
它基于 n-gram 的稀缺性对其进行加权。这就意味着对某个稀缺 n-gram的正确匹配能提高的分数,要多于对某个常见的 n-gram的正确匹配。
论文地址:Automatic Evaluation of Machine Translation QualityUsing N-gram Co-Occurrence Statistics
-
ROUGE
由于BLEU只考虑了精确率而没有考虑召回率,因此,在2004年,Chin-Yew Lin提出了一种新的评估方法ROUGE,该方法主要是从召回率的角度计算生成文本与参考文本之间的相似性,比较适用于文本摘要任务,因为文本摘要我们更考察生成文本包括了多少参考文本中包含的信息。作者在论文中总共提出了4种不同的计算方式:ROUGE-N、ROUGE-L、ROUGE-W、ROUGE-S。
它对 BLEU 进行了修改,聚焦于召回率而非准确率。换句话说,该方法看重的是参考翻译句中有多少 n-gram出现在输出句中,而不是输出句中有多少 n-gram出现在参考翻译句中。
-
METROR
BLEU只考虑精确率,METEOR则同时考虑精确率和召回率,采用加权的F值来作为评估指标。
论文地址:Meteor: An Automatic Metric for MT Evaluation with High Levels of Correlation with Human Judgments
3.4.2 外在评价
外在评价则关注生成文本在实际应用中的可用性。
3.4.3 其他
困惑度(perplexity):是交叉熵的指数形式。给定一个包含n个词的测试文本\(W=(w_1,w_2,...,w_n)\)和语言模型N-gram:\(P(w_1,w_2,...,w_n)=\prod_{i=1}^{n}P(w_i|w_{i-N+1},...,w_{i-1})\) 的困惑度perplexity可定义为交叉熵的指数形式:
perplexity和交叉熵一样都可以用来评价语言模型的好坏。 对于测试集其困惑度越小,准确率也就越高,语言模型也就越好。
perplexity刻画的是语言模型预测一个语言样本的能力,比如已经知道了 \(W=(w_1,w_2,...,w_n)\) 这句话会出现在语料库之中,那么通过语言模型计算得到这句话的概率越高,说明语言模型对这个语料库拟合的越好。
4. 参考
LSTM文本生成:《Python深度学习》第8章第1节:8.1 使用LSTM生成文本P228-P234。

