初识NER
Named Entity Recognition
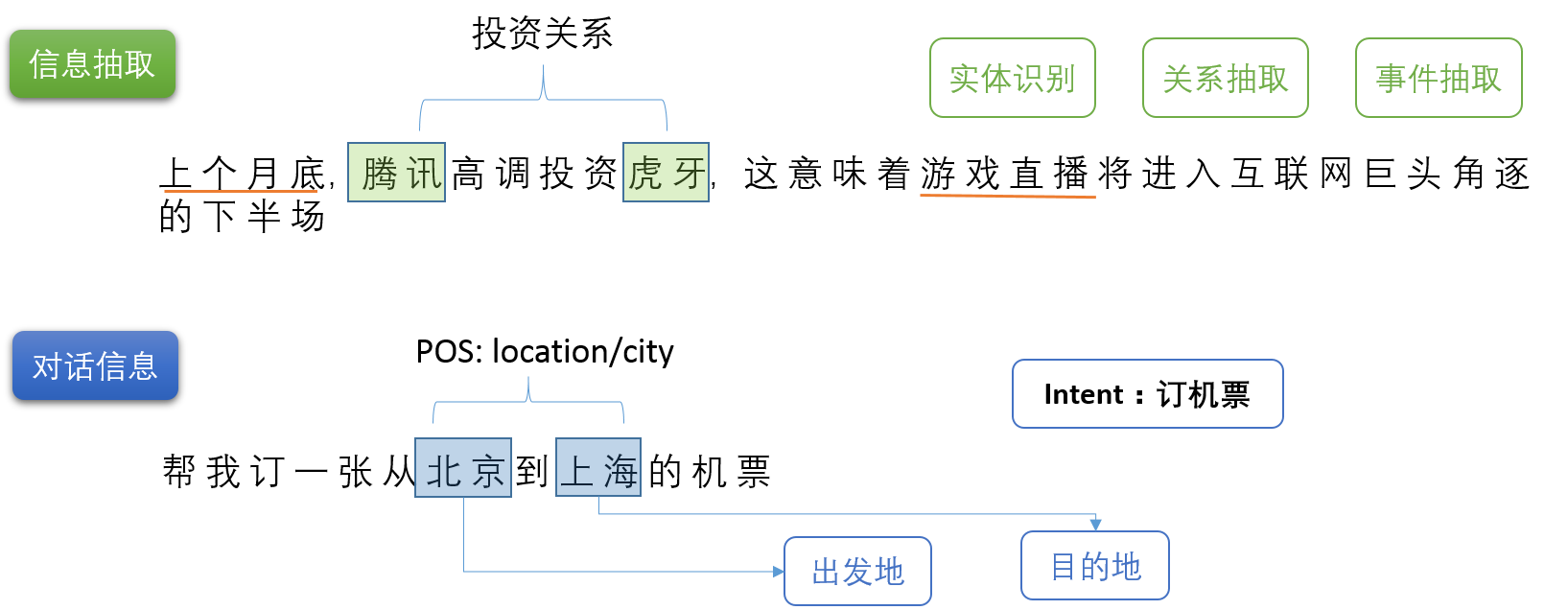
1. NER
1.1 NER定义
命名实体识别(NER):
也称为实体识别、实体分块和实体提取,是信息提取的一个子任务,旨在将文本中的命名实体定位并分类为预先定义的类别,如人员、组织、位置、时间表达式、数量、货币值、百分比等。
1.2 数据格式
NER是一种序列标注问题,因此他们的数据标注方式也遵照序列标注问题的方式,主要是BIO和BIOES两种。
1.2.1 BIO
1.2.2 BIOES

1.3 开源库
常用的NER工具推荐:
- LTP:适合中文分词、NER
- Spacy:多适用于英文
- StanfordNER
| 开源库 | 介绍 | 安装 | 官网 |
|---|---|---|---|
| Stanford NER | 斯坦福大学开发的基于条件随机场的命名实体识别系统,该系统参数是基于CoNLL、MUC-6、MUC-7和ACE命名实体语料训练出来的。 | pip install stanfordcorenlp | 官网 | Github |
| SpaCy | 工业级的自然语言处理工具,遗憾的是不支持中文。 | pip install spaCy | 官网| Github |
| NLTK | NLTK是一个高效的Python构建的平台,用来处理人类自然语言数据。 | pip install nltk | 官网 | Github |
| Hanlp | HanLP是一系列模型与算法组成的NLP工具包,由大快搜索主导并完全开源,目标是普及自然语言处理在生产环境中的应用。支持命名实体识别。 | pip install pyhanlp | 官网 | Github |
| LTP | LTP提供了一系列中文自然语言处理工具,用户可以使用这些工具对于中文文本进行分词、词性标注、句法分析等等工作。 | pip install pyltp | 官网 | Github |
1.4 相关数据集
| 数据集 | 简要说明 | 访问地址 |
|---|---|---|
| 中文电子病历 | CCKS2017开放的中文的电子病例测评相关的数据 | CCKS2017测评1 | CCKS2017测评2 |
| 音乐领域 | CCKS2018开放的音乐领域的实体识别任务 | CCKS2018 |
| 口语理解 | NLPCC2018开放的任务型对话系统中的口语理解评测 | NLPCC |
| (CoNLL 2002)Annotated Corpus for Named Entity Recognition | 这是来自GMB语料库的摘录,用于训练分类器以预测命名实体,例如姓名,位置等。 | Kaggle |
1.5 方法

阶段 1:早期的方法,如:基于规则的方法、基于字典的方法
阶段 2:传统机器学习,如:HMM、MEMM、CRF
阶段 3:深度学习的方法,如:RNN – CRF、CNN – CRF
阶段 4:近期新出现的一些方法,如:注意力模型、迁移学习、半监督学习的方法
2. BILSTM
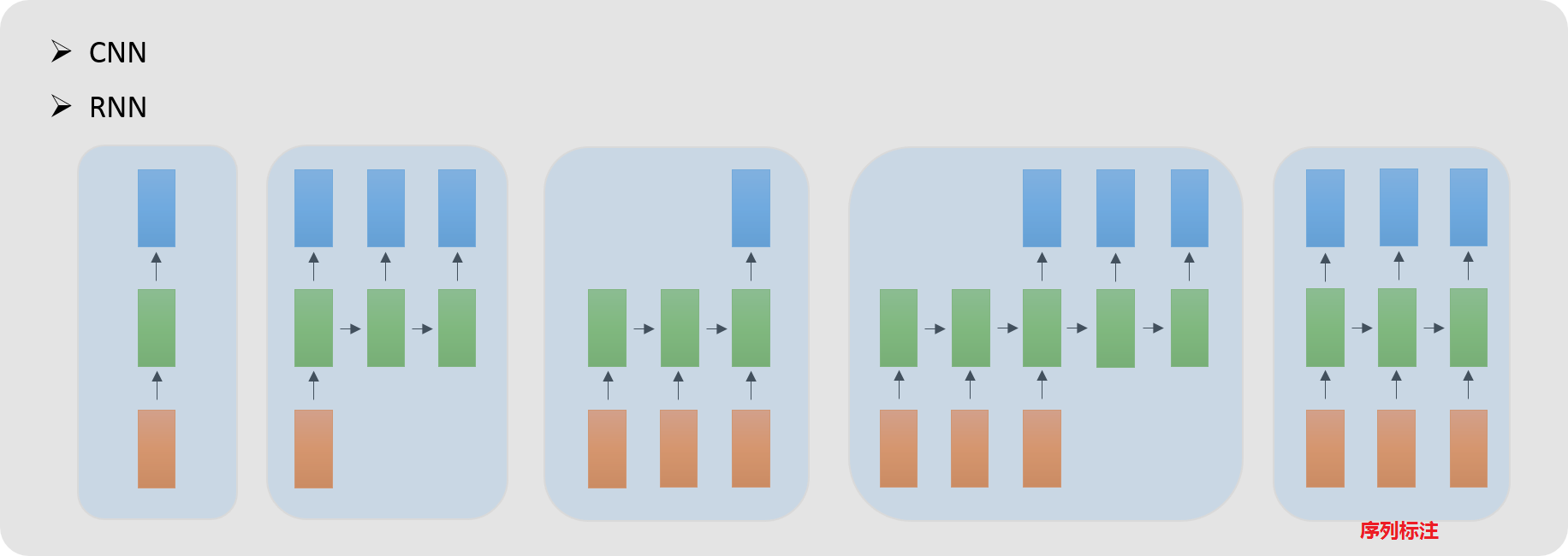
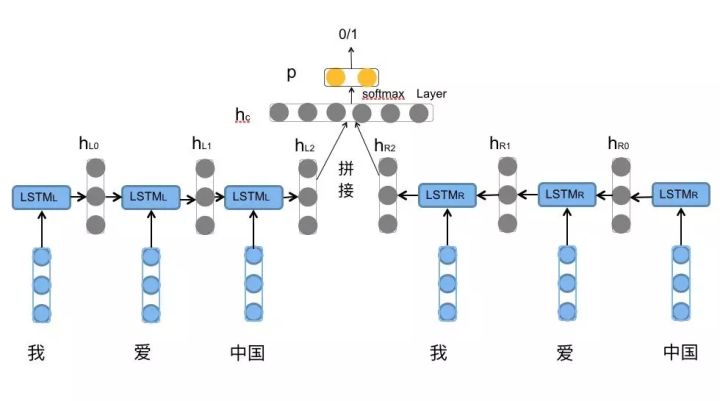
2.1 BILSTM classify
对于分类任务,例如情感分类,采用的句子表示是\([h_{L_2},h_{R_2}]\),其包含了前向与后向的所有信息。BILSTM对前向和后向的LSTM的最后一个state的隐藏信息进行拼接。
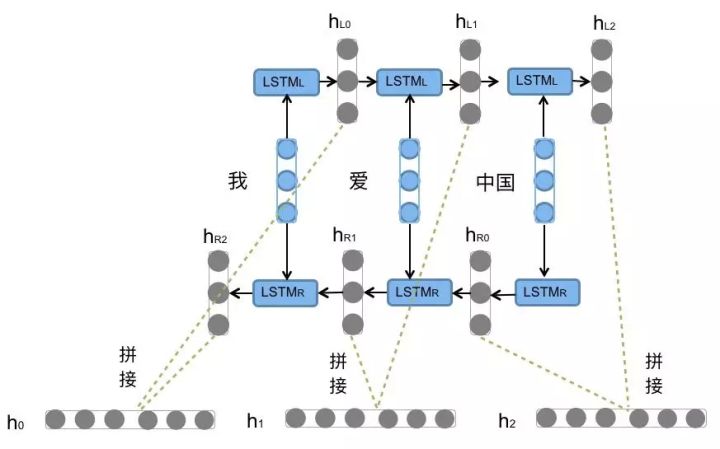
2.2 BILSTM seq encode
序列编码任务,对“我爱中国”句子进行编码,模型如下所示。BILSTM的每个state的前向和后向隐藏信息进行拼接。

3. NER应用:NER-BILSTM-CNN
论文: Named Entity Recognition with Bidirectional LSTM-CNNs
论文复现(Github):https://github.com/kamalkraj/Named-Entity-Recognition-with-Bidirectional-LSTM-CNNs
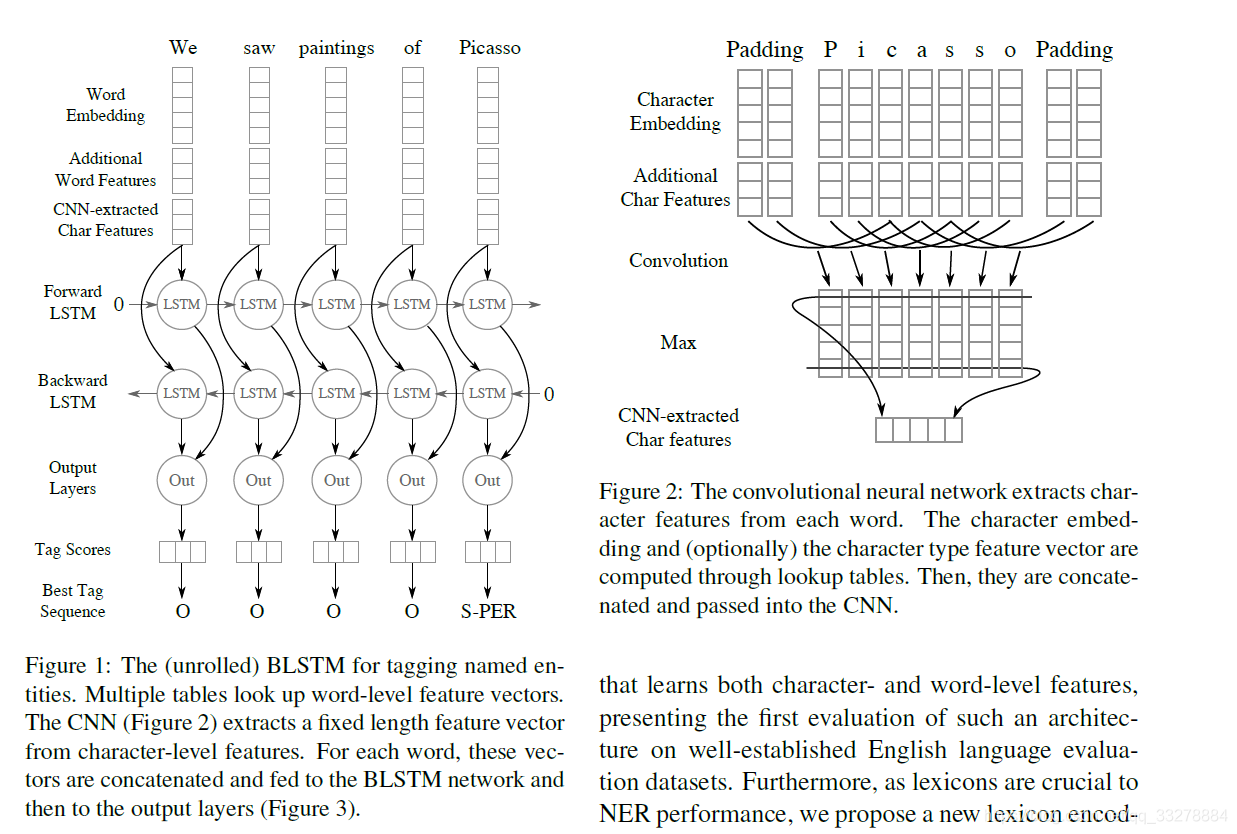
论文处理的是英文,是在CONLL2003 的数据集上针对NER任务提出的一项新模型。主要是将字符级别的特征经过CNN和词级别的特征进行concat之后经过双向LSTM进行NER预测。
这样能够更好的利用到前缀后缀之类的字符级特征。而且可以减少人工构造特征的工作。
论文的一个重点工作是特征融合工作,核心的特征包括Word Embedding,Character Embedding,Additional features。而Additional features即在字符级特征和词级别特征上加一些人工特征,包括additional word features和additional character features。比如将词可以分为6类,包括全是大写字母,全是小写字母,全是数字,部分数字等等。
additional word features包括:
- Capitalization Feature :因为Word Embedding时全部小写,所以构造了一系列特征来判断词的类别。例如:全大写,全小写,部分大写,全数字,部分数字等。
- Lexicon features :加入了词典模板匹配模块。针对数据集,使用精确匹配的词典。
additional character features包括:一个用于输出一个四维向量的查找表,四维向量表示四个类型(大写、小写、标点、其他)。
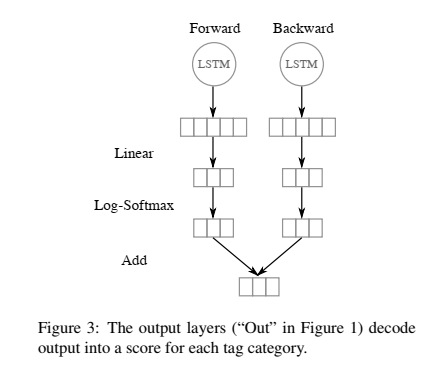
论文Figure 1中,还要将双向LSTM前向和后向经过softmax得到的分值相加来判断类别。
4. NER应用:BERT-NER
Github: https://github.com/kamalkraj/BERT-NER
Github:https://github.com/xuanzebi/BERT-CH-NER
5. 总结
-
做NER需要分词吗?
可以做分词也可以不做分词。如果分词:可能存在分词错误,模型的效果也会有受影响。不分词,即按字符进行,可以结合CNN对字符级别信息做抽取。
-
在中文电子病历的NER任务,特征工程还可以考虑的方面?
分词,对词级别信息进行RNN;不分词,对字符进行CNN;构造特征:拆分偏旁部首(例如“腹”-->“月,复”,“肺”-->“月,市”等),重新编码表示;构造特征:根据拼音来统计。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号