多模态文本分类技术
多模态文本分类技术
1. 多模态表示学习(Representation)
1.1 联合表示(Joint Representation)
定义:将多个模态的信息一起映射到一个统一的多模态向量空间
论文:Multimodal learning with deep boltzmann machines, NIPS 2014
1.2 协同表示(Coordinated Representation)
定义:将多模态中的每个模态分别映射到各自的表示空间,但映射后的向量之间满足一定的相关性约束(例如线性相关)
论文:Unifying Visual-Semantic Embeddings with Multimodal Neural Language Models (NIPS 2014)

2. 模特转化(Translation)
定义:多模态转化也可称为映射 (Mapping),主要是将一个模态的信息转化或映射为另一个模态的信息。
应用:
- 机器翻译(Machine Translation) 、唇读(Lip Reading)和语音翻译 (Speech Translation)
- 图片描述 (Image Captioning)与视频描述(Video Captioning)
- 语音合成(Speech Synthesis)
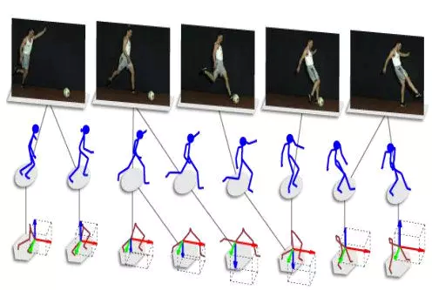
3. 模态对齐(Alignment)
定义:从来自同一个实例的两个甚至多个模态中寻找子成份之间的关系和联系。
研究方向:有显式对齐,隐式对齐两种。

相关任务:
- 给定一张图片和图片的描述,找到图中的某个区域以及这个区域在描述中对应的表述。
- 图像语义分割(Image Semantic Segmentation)

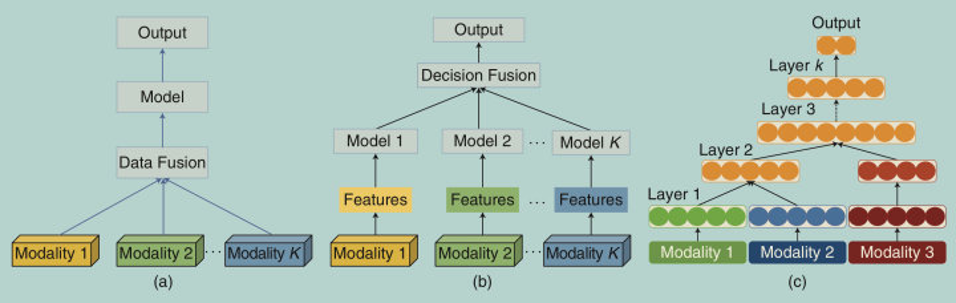
4.多模态融合(Fusion)
联合多个模态的信息,进行目标预测(分类或者回归),属于 MMML 最早的研究方向之一,也是目前应用最广的方向,它还存在其他常见的别名,例如多源信息融合(Multi-source Information Fusion)、多传感器融合(Multi-sensor Fusion)。
分类:
- Pixel level
- Feature level
- Decision level

按照融合的类型分类:
- 数据级别融合
- 判定级别融合
- 组合融合
相关任务:
-
视觉-音频识别(Visual-Audio Recognition)
![]()
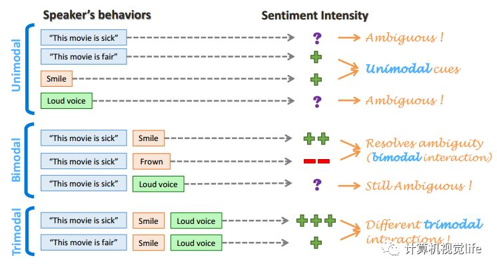
-
多模态情感分析(Multimodal sentiment analysis)
![]()
-
手机身份认证(Mobile Identity Authentication)
![]()

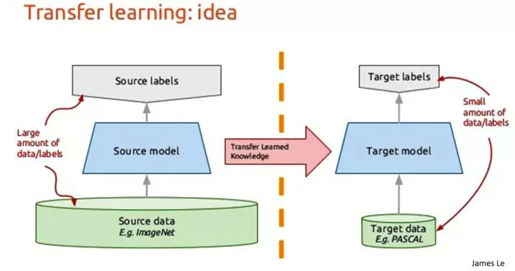
5. 协同学习(Co-learning)
通过利用资源丰富(比如数据量大)的模态的知识来辅助资源稀缺(比如较小数据)的模态建立模型。
根据数据形式划分:
- Parallel(数据并行): Co-training, Transfer learning(预训练模型)
- Non-parallel(数据不并行): Transfer learning, Concept grounding, Zero-shot learning
- Hybrid: Bridging
6. 文本分类应用
6.1 讽刺检测
-
Multi-Modal Sarcasm Detection in Twitter with Hierarchical Fusion Model. ACL 2019
-
论文来源:ACL 2019
论文链接:https://www.aclweb.org/anthology/P19-1239/
关键词:情感分析;图文;反讽刺识别

-
Towards Multimodal Sarcasm Detection (An Obviously Perfect Paper)
-
论文来源:ACL 2019
论文链接:https://arxiv.org/pdf/1906.01815v1.pdf
github地址:https://github.com/soujanyaporia/MUStARD
关键词:反讽刺识别
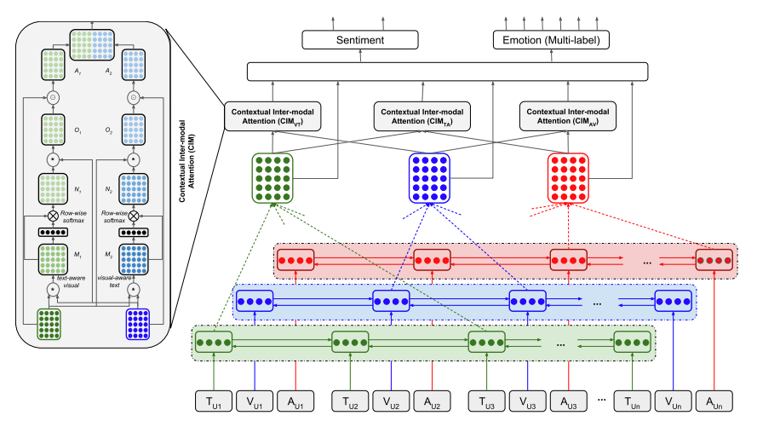
6.2 情感分类
- Contextual Inter-modal Attention for Multi-modal Sentiment Analysis. ACL 2018
- github地址:https://github.com/soujanyaporia/contextual-multimodal-fusion
链接:https://pan.baidu.com/s/1bNsgWInUlG2-M88PSXGcPQ
提取码:uk6m - 论文解读https://blog.csdn.net/ningmengshuxiawo/article/details/109141253
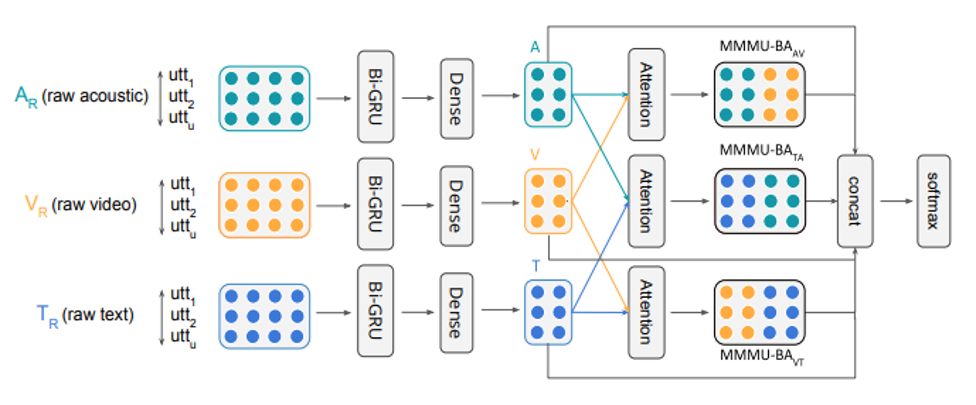
6.3 情感分析
- Multi-task Learning for Multi-modal Emotion Recognition and Sentiment Analysis. NAACL 2019
- 论文解析https://www.cnblogs.com/taaccoo/p/13662595.html
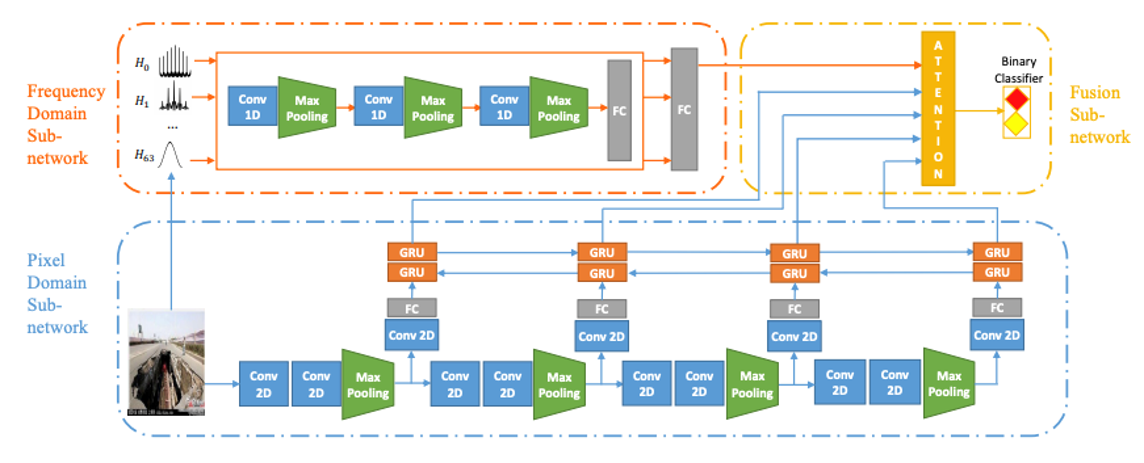
6.4 假新闻识别
-
Exploiting Multi-domain Visual Information for Fake News Detection. ICDM 2019
-
论文来源:ICDM 2019
论文链接:https://arxiv.org/abs/1908.04472
关键词:假新闻检测;图像;频域;像素域;CNN;RNN;attention
-
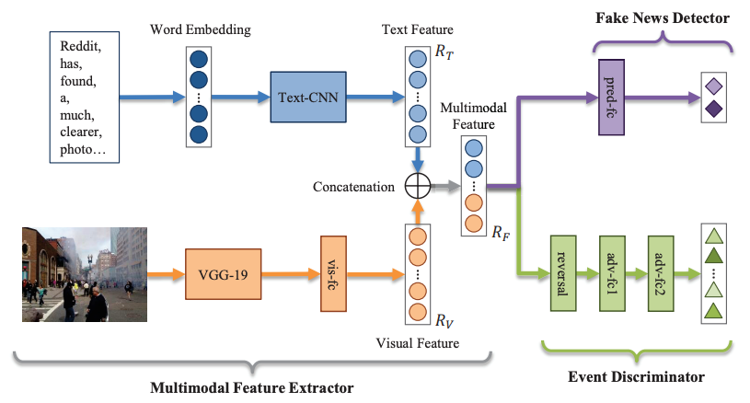
EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection. KDD 2018
-
论文来源:KDD 2018
论文链接:https://doi.org/10.1145/3219819.3219903
代码链接:https://github.com/yaqingwang/EANN-KDD18
关键词:多模态(图像+文本);对抗神经网络;假新闻检测
6.5 商品分类
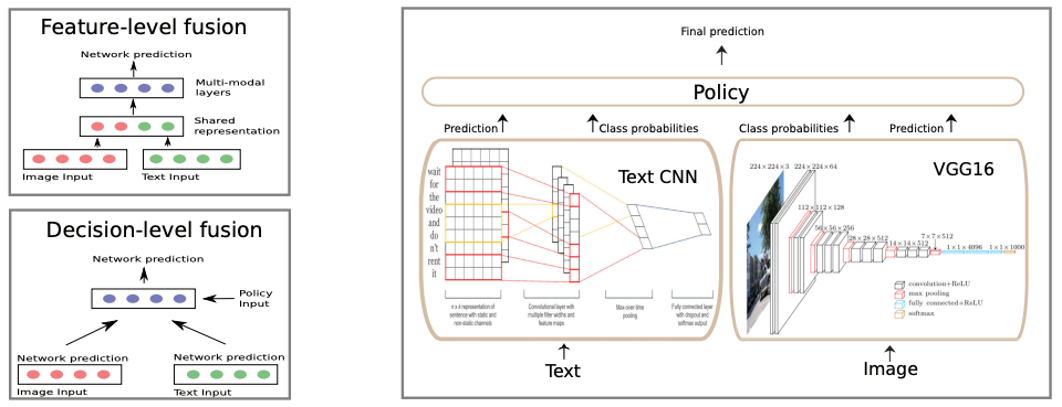
- Is a Picture Worth a Thousand Words? A Deep Multi-Modal Architecture for Product Classification in E-Commerce. AAAI 2018.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号