NLP数据增强
NLP数据增强
1. UDA (Unsupervised Data Augmentation)【推荐】
一个半监督的学习方法,减少对标注数据的需求,增加对未标注数据的利用。

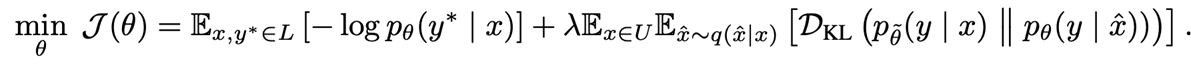
UDA使用的语言增强技术——Back-translation:回译能够在保存语义不变的情况下,生成多样的句式。
UDA关键解决的是如何根据少量的标注数据来增加未标注数据的使用?
对给定的标注数据,可以根据监督学习方法学习到一个模型\(M=p_{\theta}(y|x)\)。对未标注数据,进行半监督学习:参考标注数据分布,对未标注数据添加噪声后学习到的模型\(p_{\theta}(y|\hat{x})\)。为了保证一致性的训练(consistency training),需要尽量减少标注数据和未标注数据的分布差异,即最小化两个分布的KL散度:\(min \quad D_{KL} (p_{\theta}(y|x)||p_{\theta}(y|\hat{x}))\)。而\(\hat{x}=q(x,\epsilon)\)是对未标注数据添加噪声后得到的增强数据。那么如何添加噪声\(\epsilon\),来得到增强的数据集\(\hat{x}\)?
- valid noise: 可以保证原始未标注数据和扩展的未标注数据的预测具有一致性。
- diverse noise: 在不更改标签的情况下对输入进行大量修改,增加样本多样性,而不是仅用高斯噪声进行局部更改。
- targeted inductive biases: 不同的任务需要不同的归纳偏差。
UDA论文中对图像分类、文本分类任务做了实验,分别用到不同的数据增强策略:
- Image Classification: RandAugment
- Text Classification: Back-translation回译,保持语义,利用机器翻译系统进行多语言互译,增加句子多样性。
- Text Classification: Word replacing with TF-IDF ,回译可以保证全局语义不变,但无法控制某个词的保留。对于主题分类任务,某些关键词在确定主题时具有更重要的信息。新的增强方法:用较低的TF-IDF分数替换无信息的单词,同时保留较高的TF-IDF值的单词。
2. EDA (Easy Data Augmentation)
EDA 的4个数据增强操作:
- 同义词替换(Synonym Replacement, SR):从句子中随机选取n个不属于停用词集的单词,并随机选择其同义词替换它们;
- 随机插入(Random Insertion, RI):随机的找出句中某个不属于停用词集的词,并求出其随机的同义词,将该同义词插入句子的一个随机位置。重复n次;
- 随机交换(Random Swap, RS):随机的选择句中两个单词并交换它们的位置。重复n次;
- 随机删除(Random Deletion, RD):以 p的概率,随机的移除句中的每个单词;
使用EDA需要注意:控制样本数量,少量学习,不能扩充太多,因为EDA操作太过频繁可能会改变语义,从而降低模型性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号