Teacher forcing是什么?
Teacher forcing是什么?
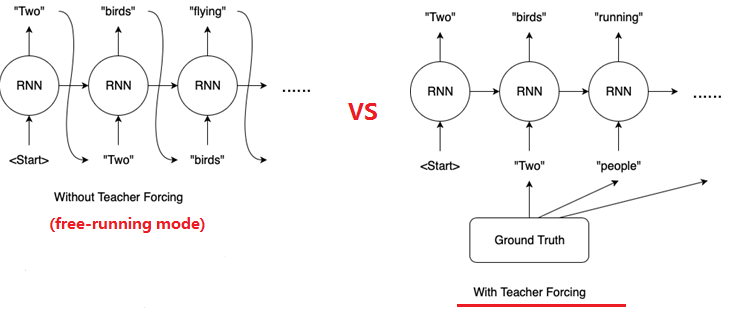
RNN 存在两种训练模式(mode):
- free-running mode: 上一个state的输出作为下一个state的输入。
- teacher-forcing mode: 使用来自先验时间步长的输出作为输入。
teacher forcing要解决什么问题?
常见的训练RNN网络的方式是free-running mode,即将上一个时间步的输出作为下一个时间步的输入。可能导致的问题:
- Slow convergence.
- Model instability.
- Poor skill.
训练迭代过程早期的RNN预测能力非常弱,几乎不能给出好的生成结果。如果某一个unit产生了垃圾结果,必然会影响后面一片unit的学习。错误结果会导致后续的学习都受到不好的影响,导致学习速度变慢,难以收敛。teacher forcing最初的motivation就是解决这个问题的。
使用teacher-forcing,在训练过程中,模型会有较好的效果,但是在测试的时候因为不能得到ground truth的支持,存在训练测试偏差,模型会变得脆弱。
什么是teacher forcing?
teacher-forcing 在训练网络过程中,每次不使用上一个state的输出作为下一个state的输入,而是直接使用训练数据的标准答案(ground truth)的对应上一项作为下一个state的输入。
Teacher Forcing工作原理: 在训练过程的\(t\)时刻,使用训练数据集的期望输出或实际输出: \(y(t)\), 作为下一时间步骤的输入: \(x(t+1)\),而不是使用模型生成的输出\(h(t)\)。
一个例子:训练这样一个模型,在给定序列中前一个单词的情况下生成序列中的下一个单词。
给定如下输入序列:
Mary had a little lamb whose fleece was white as snow
首先,我们得给这个序列的首尾加上起止符号:
[START] Mary had a little lamb whose fleece was white as snow [END]
对比两个训练过程:
| No. | Free-running: X | Free-running: \(\hat{y}\) | teacher-forcing: X | teacher-forcing: \(\hat{y}\) | teacher-forcing: Ground truth |
|---|---|---|---|---|---|
| 1 | "[START]" | "a" | "[START]" | "a" | "Marry" |
| 2 | "[START]", "a" | ? | "[START]", "Marry" | ? | "had" |
| 3 | ... | ... | "[START]", "Marry", "had" | ? | "a" |
| 4 | "[START]", "Marry", "had", "a" | ? | "little" | ||
| 5 | ... | ... | ... | ||
free-running 下如果一开始生成"a",之后作为输入来生成下一个单词,模型就偏离正轨。因为生成的错误结果,会导致后续的学习都受到不好的影响,导致学习速度变慢,模型也变得不稳定。
而使用teacher-forcing,模型生成一个"a",可以在计算了error之后,丢弃这个输出,把"Marry"作为后续的输入。该模型将更正模型训练过程中的统计属性,更快地学会生成正确的序列。
teacher-forcing 有什么缺点?
teacher-forcing过于依赖ground truth数据,在训练过程中,模型会有较好的效果,但是在测试的时候因为不能得到ground truth的支持,所以如果目前生成的序列在训练过程中有很大不同,模型就会变得脆弱。
换言之,这种模型的cross-domain能力会更差,即如果测试数据集与训练数据集来自不同的领域,模型的performance就会变差。
那有没有解决这个限制的办法呢?
teacher-forcing缺点的解决方法
beam search
在预测单词这种离散值的输出时,一种常用方法是:对词表中每一个单词的预测概率执行搜索,生成多个候选的输出序列。
这个方法常用于机器翻译(MT)等问题,以优化翻译的输出序列。
beam search是完成此任务应用最广的方法,通过这种启发式搜索(heuristic search),可减小模型学习阶段performance与测试阶段performance的差异。
curriculum learning
Curriculum Learning是Teacher Forcing的一个变种:一开始老师带着学,后面慢慢放手让学生自主学。
Curriculum Learning即有计划地学习:
- 使用一个概率\(p\)去选择使用ground truth的输出\(y(t)\)还是前一个时间步骤模型生成的输出\(h(t)\)作为当前时间步骤的输入\(x(t+1)\)。
- 这个概率\(p\)会随着时间的推移而改变,称为计划抽样(scheduled sampling)。
- 训练过程会从force learning开始,慢慢地降低在训练阶段输入ground truth的频率。
Further Reading
Papers
- A Learning Algorithm for Continually Running Fully Recurrent Neural Networks, 1989.
- Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks, 2015.
- Professor Forcing: A New Algorithm for Training Recurrent Networks, 2016.
Book
- Section 10.2.1, Teacher Forcing and Networks with Output Recurrence, Deep Learning, Ian Goodfellow, Yoshua Bengio, Aaron Courville, 2016.
问:在训练中,将teacher forcing替换为使用解码器在上一时间步的输出作为解码器在当前时间步的输入,结果有什么变化吗?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号