计算文本相似度
相似度计算方法
1. 文本距离
1.1 编辑距离(Edit Distance)
编辑距离,英文叫做 Edit Distance,又称 Levenshtein 距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。如果两个字符串的编辑距离越大,说明它们越是不同。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。
1.2 最长公共子串、最长公共子序列(Long Common Subsequence,LCS)
最长公共子序列问题:给定两个字符串,\(S\)(长度\(n\))和\(T\)(长度\(m\)),求解它们的最长公共子序列。其中公共子序列是指:按从左到右顺序在\(S\)、\(T\)中均出现的字符序列,子序列中字符在\(S\)、\(T\)中无需连续。
例:\(S\) = ABAZDC、\(T\) = BACBAD,\(S\)和\(T\)的最长公共子序列为:ABAD。
最长公共子串问题:给定两个字符串,\(S\)(长度\(n\))和\(T\)(长度\(m\)),求解它们的最长公共子串。其中公共子串是指:按从左到右顺序在\(S\)、\(T\)中均出现的字符串,子串中字符在\(S\)、\(T\)中需要连续。
例:\(S\) = ABAZDC、\(T\) = BACBAD,\(S\)和\(T\)的最长公共子串为:BA。
1.3 句向量表示(Word Averaging Model,WAM)
获取 Sentence Vector :我们首先对句子进行分词,然后对分好的每一个词获取其对应的 Vector,然后将所有 Vector 相加并求平均,这样就可得到 Sentence Vector。

1.4 WMD
WMD(Word Mover's Distance)中文称作词移距离。通过寻找两个文本之间所有词之间最小距离之和的配对来度量文本的语义相似度。是EMD(Earth Mover's Distance)在NLP领域的延伸。
两个文本中每一个词都需要进行一一对应,计算一下相似度,并且是有侧重地计算相似度。
\(c(i,j)\)表示单词\(i, j\)之间的相似度计算,而\(T_{ij}\)表示对于这种相似度的权重。由于两个文本之间的单词两两之间都要进行相似度计算,可知T是一个矩阵。 \(d_i\)是归一化词频(normalized BOW),单词的重要程度与词的出现频率相关(并且归一化)。如果一个词\(i\)在文本中出现的次数为\(c_i\),它的归一化词频为:\(d_i=\frac{c_i}{\sum_{j=1}^{n}c_j}\).
计算两个文档之间的WMD就要求解一个大型的线性规划问题。
1.5 BM25
BM25 是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法:有一个\(query\)和一批文档Ds,现在要计算\(query\)和每篇文档D之间的相关性,先对\(query\)进行切分,得到单词\(q_i\),然后单词的分数由3部分组成:
- 每个单词的权重\(W_i\),可以由IDF表示,\(IDF(q_i)=log(\frac{N-n(q_i)+0.5}{n(q_i)+0.5})\)
- 相关性分数R:单词和D之间的相关性,单词和query之间的相关性
- \(dl\)是文档\(d\)的长度,\(avgdl\)是整个文档集中文档的平均长度;
- \(f_i\)是单词\(q_i\)在文档\(d\)中的词频,\(qf_i\)是单词\(q_i\)在\(query\)中的词频;
- \(k_1, b\)是参数(通常\(k_1=1.2, b=0.75\));
- 简化情况下,\(query\)比较短,查询词\(q_i\)在\(query\)中只会出现一次,即\(qf_i=1\),因此可以简化\(R(q_i,d)\)中\(\frac{qf_i\cdot (k_2+1)}{qf_i+k_2}=1\).
综上,BM25算法的相关性得分公式可总结为:
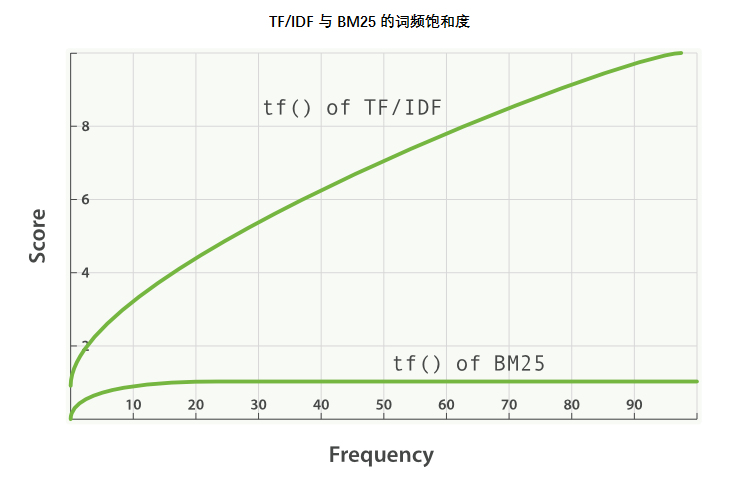
TF/IDF 和 BM25 同样使用逆向文档频率来区分普通词(不重要)和非普通词(重要),同样认为文档里的某个词出现次数越频繁,文档与这个词就越相关。实际上一个普通词在同一个文档中大量出现的作用会由于该词在 所有 文档中的大量出现而被抵消掉。
BM25 有一个上限,文档里出现 5 到 10 次的词会比那些只出现一两次的对相关度有着显著影响。但是如图 TF/IDF 与 BM25 的词频饱和度 所见,文档中出现 20 次的词几乎与那些出现上千次的词有着相同的影响。
2. 统计指标
2.1 Cosine Similarity
余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。Cosine Similarity的绝对值越大,两向量越相似,值为负,两向量负相关。
余弦相似度更多的是从方向上区分差异,而对绝对的数值不敏感,因此没法衡量每个维度上数值的差异,会导致这样一种情况:
用户对内容评分,按5分制,X和Y两个用户对两个内容的评分分别为(1,2)和(4,5),使用余弦相似度得到的结果是0.98,两者极为相似。但从评分上看X似乎不喜欢2这个 内容,而Y则比较喜欢,余弦相似度对数值的不敏感导致了结果的误差,需要修正这种不合理性就出现了调整余弦相似度,即所有维度上的数值都减去一个均值,比如X和Y的评分均值都是3,那么调整后为(-2,-1)和(1,2),再用余弦相似度计算,得到-0.8,相似度为负值并且差异不小,但显然更加符合现实。
调整余弦相似度(Adjusted Cosine Similarity):
2.2 Jaccard Similarity
杰卡德系数,英文叫做 Jaccard index, 又称为 Jaccard similarity,用于比较有限样本集之间的相似性与差异性。
Jaccard 系数值越大,样本相似度越高。
计算方法:两个样本的交集除以并集得到的数值,当两个样本完全一致时,结果为 1,当两个样本完全不同时,结果为 0。
计算结果范围:\([0,1]\)。
与杰卡德相似系数相反的概念是杰卡德距离(Jaccard Distance),可以用如下公式来表示:
杰卡德距离用两个两个集合中不同元素占所有元素的比例来衡量两个集合的区分度。
2.3 Pearson Correlation
皮尔逊相关系数(Pearson Correlation)定义为两个变量之间的协方差和标准差的商。实际上也是一种余弦相似度,不过先对向量做了中心化,两向量各自减去均值后,再计算余弦相似度。当两个向量均值都为0时,皮尔逊相对系数等于余弦相似性。
计算结果范围:\([-1,1]\),-1 表示负相关,1 比表示正相关。
计算方法:
2.4 Euclidean Distance
明氏距离(Minkowski Distance)的推广:\(p=1\)为曼哈顿距离,\(p=2\)为欧氏距离,切比雪夫距离是明氏距离取极限的形式。
如果两个点特征值不在一个数量级时,大的特征值会覆盖掉小的。如Y1(10000,1),Y2(20000,2)。
标准欧氏距离的思路:将各个维度的数据进行标准化:标准化后的值 = ( 标准化前的值 - 分量的均值 ) /分量的标准差,然后计算欧式距离。
3. 深度匹配
基于BERT等深度学习模型来计算句对之间的相似度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号