gensim中常用的Word2Vec,Phrases,Phraser,KeyedVectors
gensim中常用的Word2Vec,Phrases,Phraser,KeyedVectors
1. Phrases 和Phraser
gensim.models.phrases.Phrases 和gensim.models.phrases.Phraser的用处是从句子中自动检测常用的短语表达,N-gram多元词组。Phrases模型可以构建和实现bigram,trigram,quadgram等,提取文档中经常出现的2个词,3个词,4个词。
具体可以查看官网gensim.models.phrases.Phrases API, tutorial
两者不同:
-
Phrases基于共现频率提取bigram词组。基于共现的统计:受min_count与threshold的影响,参数设置越大,单词组合成二元词组的难度越大。
class
gensim.models.phrases.Phrases(sentences=None, min_count=5, threshold=10.0, max_vocab_size=40000000, delimiter=b'_', progress_per=10000, scoring='default', common_terms=frozenset({})) -
Phraser的目的是通过丢弃一些Phasers模型(phrases_model)状态,减少短语的内存消耗。如果后面不需要用新文档更新bigram统计信息,就可以使用Phraser代替Phrases。
一次性初始化后,Phraser会比使用Phrases模型占用内存小且速度更快。
class
gensim.models.phrases.Phraser(phrases_model)-
Parameters
phrases_model (
Phrases) – Trained phrases instance.
-
Example:
>>> from gensim.test.utils import datapath
>>> from gensim.models.word2vec import Text8Corpus
>>> from gensim.models.phrases import Phrases, Phraser
>>>
>>> # Load training data.
>>> sentences = Text8Corpus(datapath('testcorpus.txt'))
>>> # The training corpus must be a sequence (stream, generator) of sentences,
>>> # with each sentence a list of tokens:
>>> print(list(sentences)[0][:10])
['computer', 'human', 'interface', 'computer', 'response', 'survey', 'system', 'time', 'user', 'interface']
>>>
>>> # Train a toy bigram model.
>>> phrases = Phrases(sentences, min_count=1, threshold=1)
>>> # Apply the trained phrases model to a new, unseen sentence.
>>> phrases[['trees', 'graph', 'minors']]
['trees_graph', 'minors']
>>> # The toy model considered "trees graph" a single phrase => joined the two
>>> # tokens into a single token, `trees_graph`.
>>>
>>> # Update the model with two new sentences on the fly.
>>> phrases.add_vocab([["hello", "world"], ["meow"]])
>>>
>>> # Export the trained model = use less RAM, faster processing. Model updates no longer possible.
>>> bigram = Phraser(phrases)
>>> bigram[['trees', 'graph', 'minors']] # apply the exported model to a sentence
['trees_graph', 'minors']
>>>
>>> # Apply the exported model to each sentence of a corpus:
>>> for sent in bigram[sentences]:
... pass
>>>
>>> # Save / load an exported collocation model.
>>> bigram.save("/tmp/my_bigram_model.pkl")
>>> bigram_reloaded = Phraser.load("/tmp/my_bigram_model.pkl")
>>> bigram_reloaded[['trees', 'graph', 'minors']] # apply the exported model to a sentence
['trees_graph', 'minors']
2. Word2Vec
涵盖常用的word2vec算法skip-gram和CBOW,使用hierarchical softmax和负采样。
注意:官网里Word2Vec函数的vector_size参数应该已经换成了size,在使用时用size.
class gensim.models.word2vec.Word2Vec(sentences=None, corpus_file=None, size=100, alpha=0.025, window=5, min_count=5, max_vocab_size=None, sample=0.001, seed=1, workers=3, min_alpha=0.0001, sg=0, hs=0, negative=5, ns_exponent=0.75, cbow_mean=1, hashfxn=
常用的几个方式:
-
普通嵌入:Word2Vec要求输入是可迭代的有序句子列表,即是已经分词的句子列表,即某个二维数组。不过在数据集较大的情况会占用大量RAM,可以使用自定义的生成器,只在内存中保存单条语句。
from gensim.models import Word2Vec # load data raw_sentences = ["the quick brown fox jumps over the lazy dogs","yoyoyo you go home now to sleep"] # words cut sentences= [s.split() for s in raw_sentences] # initialize and train a word2vec model model = Word2Vec(sentences, size=300, window=5, min_count=1, workers=4) # save model model.save("word2vec.model")调用Word2Vec创建模型实际上会对数据执行两次迭代操作,第一轮操作会统计词频来构建内部的词典数结构,第二轮操作会进行神经网络训练,而这两个步骤是可以分步进行的,这样对于某些不可重复的流(譬如 Kafka 等流式数据中)可以手动控制:
from gensim.models import Word2Vec sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]] # initialize model model = Word2Vec(size=300, window=5, min_count=1, workers=4) # prepare the model vocabulary model.build_vocab(sentences) # train word vectors model.train(sentences, total_examples=model.corpus_count, epochs=model.epochs) -
多词嵌入:利用gensim.models.phrases模块,获取二元词组,word2vec模型可以学习短语表达,比如new_york,machine_learning。
from gensim.test.utils import common_texts from gensim.models import Phrases, Phraser # Train a bigram detector. phrases = Phrases(common_texts) bigram = Phraser(phrases) sentences = bigram[common_texts] # Apply the trained MWE detector to a corpus, using the result to train a Word2vec model. model = Word2Vec(sentences, min_count=1, size=300, window=5, iter=7) -
预训练模型:Gensim数据存储库中附带了几个已经过预训练的模型:Gensim-data repository。对于中文来说,gensim-data没有中文数据,更需要自己找语料库训练模型.
import gensim.downloader # Show all available models in gensim-data print(list(gensim.downloader.info()['models'].keys())) #>>>['fasttext-wiki-news-subwords-300', 'conceptnet-numberbatch-17-06-300', 'word2vec-ruscorpora-300', 'word2vec-google-news-300', 'glove-wiki-gigaword-50', 'glove-wiki-gigaword-100', 'glove-wiki-gigaword-200', 'glove-wiki-gigaword-300', 'glove-twitter-25', 'glove-twitter-50', 'glove-twitter-100', 'glove-twitter-200', '__testing_word2vec-matrix-synopsis'] # Download the "glove-twitter-25" embeddings glove_vectors = gensim.downloader.load('glove-twitter-25') # Use the downloaded vectors as usual: glove_vectors.most_similar('twitter')
3. KeyedVector
gensim.models.keyedvectors模块实现词向量的保存和各种相似性查询。由于训练后的词向量与训练方式无关,因此可以用一个独立结构来表示。这个结构叫做 “KeyedVectors”,本质上是键和向量之间的映射。每个向量都由它的查找键来标识。
参考API:KeyedVector
class gensim.models.keyedvectors.KeyedVectors(vector_size, count=0, dtype=<class 'numpy.float32'>, mapfile_path=None)
classmethod load(fname, mmap=None)
classmethod load_word2vec_format(fname, fvocab=None, binary=False, encoding='utf8', unicode_errors='strict', limit=None, datatype=<class 'numpy.float32'>, no_header=False)
save(args, kwargs):Save KeyedVectors to a file.
save_word2vec_format(fname, fvocab=None, binary=False, total_vec=None, write_header=True, prefix='', append=False, sort_attr='count'):Store the input-hidden weight matrix in the same format used by the original C word2vec-tool, for compatibility.
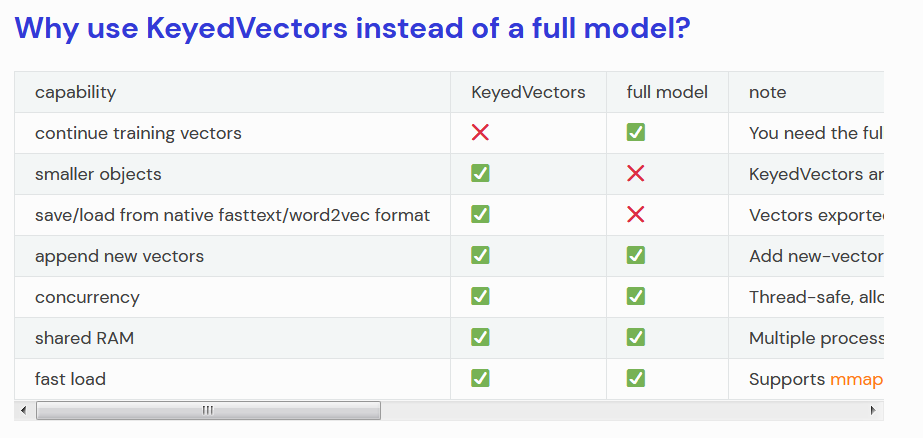
KeyedVector和完整模型的主要区别:KeyedVectors不支持进一步的训练。另一方面,通过舍弃训练所需的内部数据结构,KeyedVectors提供了更小的RAM占用空间和更简单的接口。
词向量保存的各种数据格式
一个是词向量保存的格式有好几种,大小会不同嘛,哪个速度快,选哪个呢?另外保存时使用二进制和非二进制,在读取词向量时可能带来编码问题。
训练一个完整的模型,然后访问其model.wv属性,该属性持有独立的键控向量。
词向量获取:保留在磁盘上,词向量从磁盘上现有的文件中实例化,以原始Google的word2vec C格式作为KeyedVectors实例。
model.save()不能利用文本编辑器查看,但是保存了训练的全部信息,可以在读取后追加训练;model.wv.save_word2vec_format()保存为word2vec文本格式,但是保存时丢失了词汇树等部分信息,不能追加训练。
from gensim.test.utils import common_texts
from gensim.models import Word2Vec, KeyedVectors
# initialize and train a word2vec model
model = Word2Vec(common_texts, size=300, window=5, min_count=1, workers=4)
# save model
model.save("word2vec.model")
# 1.保存为KeyedVector文件
model.wv.save('vectors_300.kv')
# 2.将词向量保存为txt格式/非二进制
model.wv.save_word2vec_format('token_vec_300.txt', binary=False)
# 3.将词向量保存为bin格式/二进制
model.wv.save_word2vec_format('token_vec_300.bin', binary=True)
# 4.将词向量保存为bin.gz格式/压缩二进制
model.wv.save_word2vec_format('token_vec_300.bin.gz', binary=True)
# 1. 加载KeyedVectors实例
keyed_vectors = KeyedVectors.load('vectors_300.kv')
# 2. 加载词向量txt格式/非二进制
wv_from_text = KeyedVectors.load_word2vec_format('token_vec_300.txt', binary=False)
# 3. 加载词向量bin格式/二进制
wv_from_bin = KeyedVectors.load_word2vec_format('token_vec_300.bin', binary=True)
# 4. 加载词向量bin.gz格式/压缩二进制
wv_from_bin_gz = KeyedVectors.load_word2vec_format('token_vec_300.bin.gz', binary=True)
| 模型保存/词向量保存格式 | 大小 |
|---|---|
| model.save("word2vec.model") | 48KB |
| model.wv.save('vectors_300.kv') | 23KB |
| model.wv.save_word2vec_format('token_vec_300.txt', binary=False) | 49KB |
| model.wv.save_word2vec_format('token_vec_300.bin', binary=True) | 15KB |
| model.wv.save_word2vec_format('token_vec_300.bin.gz', binary=True) | 13KB |
总结:词向量还是以bin或bin.gz格式保存为佳,占用空间少。
词向量用处
用训练好的向量执行各种句法/语义NLP词任务。
import gensim.downloader as api
# load pre-trained word-vectors from gensim-data
word_vectors = api.load("glove-wiki-gigaword-100")
# Check the "most similar words", using the default "cosine similarity" measure.
result = word_vectors.most_similar(positive=['woman', 'king'], negative=['man'])
most_similar_key, similarity = result[0] # look at the first match
print(f"{most_similar_key}: {similarity:.4f}")
#>>> queen: 0.7699

 浙公网安备 33010602011771号
浙公网安备 33010602011771号