
三十一、备份方案实战
某公司有一台Web服务器,里面的数据很重要,但是如果硬盘坏了,数据就会丢失,现在领导要求你把数据备份,这样Web服务器数据丢失可以进行恢复。
自己想:每天晚上00点整在Web服务器A上打包备份系统配置文件、网站程序目录及访问日志并通过rsync命令推送到服务器B上备份保留(备份思路可以是先在本地按日期打包,然后再推送到备份服务器B上)
具体要求:
1)Web服务器A和备份服务器B的备份目录必须都是backup。
2)系统配置文件包括但不限于:
a.定时任务服务的配置文件(/var/spool/cron/root)
b.开机自启动的配置文件(/etc/rc.local)
c.日常脚本目录(/server/script)
d.防火墙iptables的配置文件(/etc/sysconfig/iptables)
e.自己思考下还有什么需要备份呢?
3)Web服务器站点目录假定为(/var/html/www)
4)Web服务器A访问日志路径假定为(/app/logs)
5) Web服务器保留打包后的7天的备份数据即可,备份服务器要有6个月数据
6)备份服务器B上要按照备份数据服务器的IP为目录保存,打包的文件按照事件名字保存。
本题是工作中网站生产环境全网备份项目方案的一个小型模拟,很有意义。

bak.sh脚本:
ip=$(ifconfig eth0 |sed -n '2p'|awk -F "[ :]+" '{print $4}')
[ ! -d /backup/$ip ] && mkdir -p /backup/$ip
cd /backup/$ip &&\
tar zcf access_$(date +%F -d '-1day').tar.gz /var/www/html /app/logs/ /server/scripts/ /var/spool/cron/ /etc/
find /backup -type f -name "*.tar.gz" -mtime +7 |xargs rm -f
定时任务:
[root@djw scripts]# cat /var/spool/cron/root
#bak scripts
00 00 * * * /bin/sh /server/scripts/bak.sh >/dev/null 2>&1
完毕!
这里说明1点:查看备份文件都有哪些:tar tf xx.tar.gz
IDC机房备份方案实战架构图:
此为定时任务的备份:
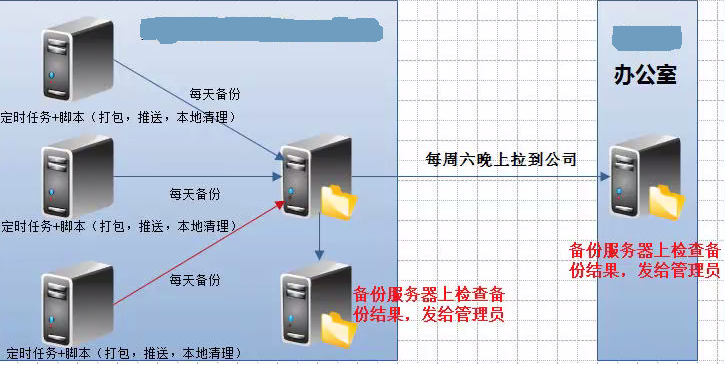
将三台服务器数据备份到备份或者存储服务器上,如果数据重要,还要备份到备份服务器上,如果发生火灾等情况是非常严重的情况,所以还要备份到办公室里面。
如果要进行实时的同步,如下图:
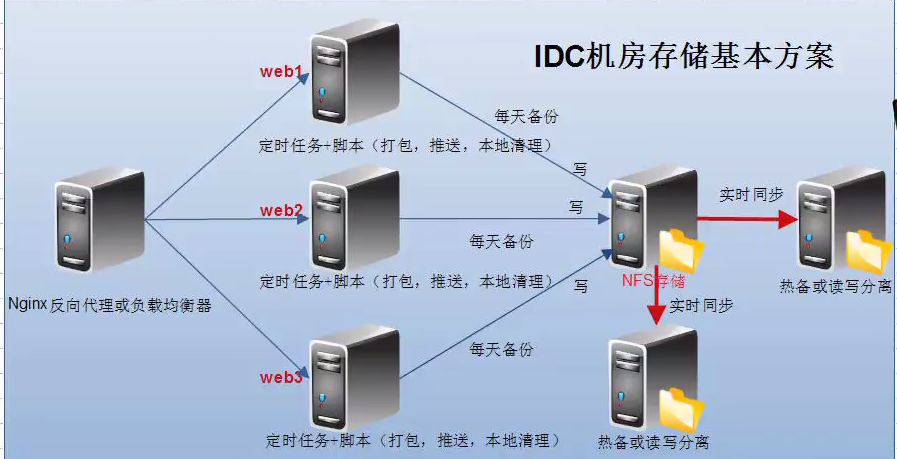
上面两个框架都是手工可以进行同步的,如上,如果NFS存储服务器挂了,那么可以进行手工同步到热备服务器上面,当然也可以通过自动化实现。
对于运维,越往上走,越是自动化;对于管理,越往上走,对于技术要求越低。未来企业对于综合人才的需求越来越重要,运维会开发,侧重运维,开发会运维,侧重开发;综合素质要高,对于技术和综合素质,比例是6:4
企业级IDC大集群备份方案:(一般的网站加速优化都是对于静态服务器而言的)

最后,还是要重新整理下:
一、文件级别同步方案:scp,nfs,http,rsync
思想:
1.文件级别的同步可以利用一些工具:如mysql,mongodb工具进行同步,将文件写入数据库,在另外一段进行文件的读出。
2.也可以两个服务器同时写数据,双写就是一个同步机制。
二、文件系统级别的同步方案:drbd(基于文件系统同步网络RAID1),几乎任何业务数据都可以同步。缺点是主节点不坏,备节点不能用。优点是快,因为是基于磁盘块block块的同步(4k),而扇区是512字节。因此mysql数据库的官方也是推荐drbd同步数据。
三、数据库同步方案:
a.自身同步机制:mysql replication(基于逻辑sql的主从复制)
oracle dataguard(物理的磁盘块,逻辑的sql语句)
b.第三方:drbd

 浙公网安备 33010602011771号
浙公网安备 33010602011771号