
Hive之mapreduce原理
Mapreduce的过程整体上分为四个阶段:InputFormat 、MapTask 、ReduceTask 、OutPutFormat,当然中间还有shuffle阶段
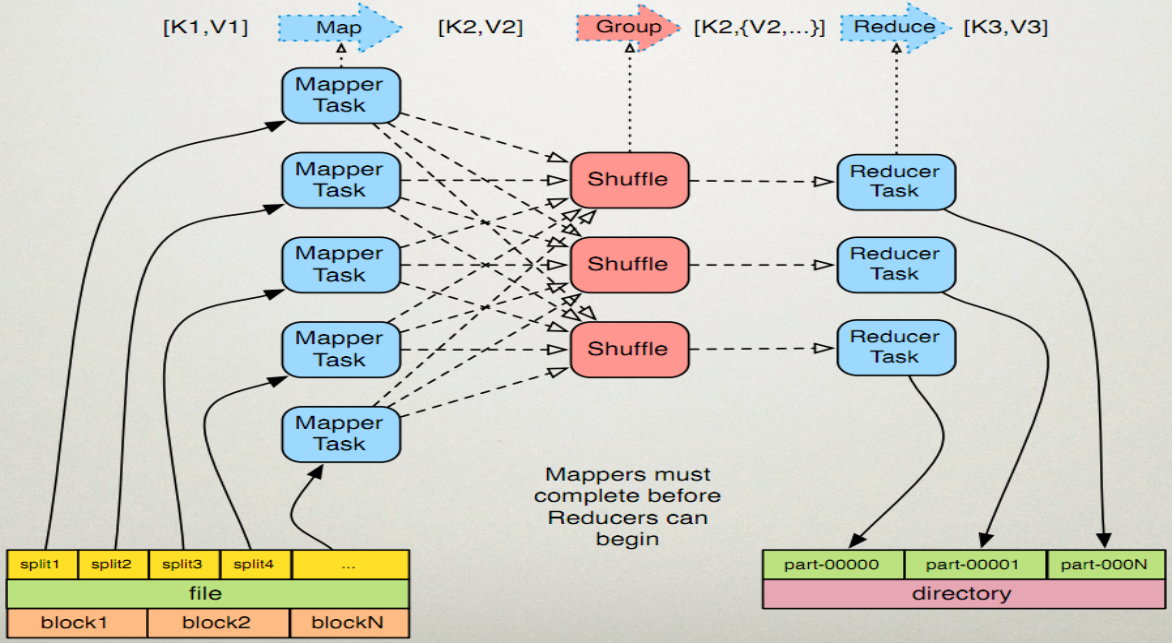
读取(InputFormat):
我们通过在runner类中用 job.setInputPaths 或者是addInputPath添加输入文件或者是目录(这两者是有区别的)
默认是FileInputFormat中的TextInputFormat类
MapTask
1.分片(split)
将输入的文件按照设置的切片大小值切分为多个输入分片,每个输入分片会对应一个Maptask任务
2.key-value对转化
LineRecordReader将一个输入分片中的每一行按\n分割成key-value ,key是偏移量 ,value是每一行的内容
3.map()方法
每一个key-value经过map()方法业务处理之后转化为新的key-value输出,shuffle阶段开始,向缓冲区写入数据
Map shuffle
1.向缓冲区写入数据前要先进行分区(partitioner)
对输出的进行分区。用户可以自定义分区(就是继承Partitioner类),然后定制到job上,如果没有进行分区,框架会使用 默认的分区(HashPartitioner)对key去hash值之后,然后在对reduceTaskNum进行取模(目的是为了平衡reduce的处理能力),然后决定由那个reduceTask来处理。
2.将分完区的结果<key,value,partition>开始序列化成字节数组,开始写入缓冲区
随着map端的结果不端的输入缓冲区,缓冲区里的数据越来越多,缓冲区的默认大小是100M,当缓冲区大小达到阀值时 默认是0.8【spill.percent】(也就是80M),开始启动溢写线程,锁定这80M的内存执行溢写过程,内存—>磁盘,此时map输出的结果继续由另一个线程往剩余的20M里写,两个线程相互独立,彼此互不干扰。
3.溢写spill线程启动后,开始对key进行排序(sort)
默认的是自然排序,也是对序列化的字节数组进行排序(先对分区号排序,然后在对key进行排序)。
4.自定义聚合Combiner
将相同的key的value相加做聚合,这样的好处就是减少溢写到磁盘的数据量
Combiner使用一定得慎重,适用于输入key/value和输出key/value类型完全一致,而且不影响最终的结果
5.合并(Merge)
每次溢写都会在磁盘上生成一个一个的小文件,所以需要将这些溢写文件归并到一起,形成一个group集合,一个MapTask端生成一个结果文件
这时候Map Shuffle就算是完成了
ReduceTask
Reduce shuffle
当MapTask完成任务数超过总数的5%后,开始调度执行ReduceTask任务
1.复制(copy)
ReduceTask默认启动5个copy线程到完成的MapTask任务节点上分别copy一份属于自己的数据(使用Http的方式)。
拷贝的数据会首先保存到内存缓冲区中,当达到一定的阀值的时候,开始启动内溢写过程,写入到磁盘
2.溢写spill线程启动后,和map端一样开始对key进行排序(sort)
3.group(分组)
将相同的key放到一个集合中
4.合并(Merge)
溢写过程运行直到map端没有数据生成,最后启动磁盘到磁盘的Merge方式生成最终的文件
reduce shuffle完成
reduced()方法进行处理,执行相应的业务逻辑
OutputFormat
reduce数据输出到HDFS上
当我们输出需要指定到不同于HDFS时,需要自定义输出类继承OutputFormat类

 浙公网安备 33010602011771号
浙公网安备 33010602011771号