
MySQL MHA高可用方案
http://www.cnblogs.com/chenmh/p/5796115.html
介绍
MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。它由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。
原理

(1)从宕机崩溃的master保存二进制日志事件(binlog events);
(2)识别含有最新更新的slave;
(3)应用差异的中继日志(relay log)到其他的slave;
(4)应用从master保存的二进制日志事件(binlog events);
(5)提升一个slave为新的master;
(6)使其他的slave连接新的master进行复制;
MHA软件由两部分组成,Manager工具包和Node工具包
Manager工具包主要包括以下几个工具:

masterha_check_ssh 检查MHA的SSH配置状况 masterha_check_repl 检查MySQL复制状况 masterha_manger 启动MHA masterha_check_status 检测当前MHA运行状态 masterha_master_monitor 检测master是否宕机 masterha_master_switch 控制故障转移(自动或者手动) masterha_conf_host 添加或删除配置的server信息
Node工具包(这些工具通常由MHA Manager的脚本触发,无需人为操作)主要包括以下几个工具:
save_binary_logs 保存和复制master的二进制日志 apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的slave filter_mysqlbinlog 去除不必要的ROLLBACK事件(MHA已不再使用这个工具) purge_relay_logs 清除中继日志(不会阻塞SQL线程)
一、安装MHA
1.创建安装目录
Node服务器安装
mkdir -p /usr/local/mha
manage服务器安装
mkdir -p /usr/local/mha/ha1/fail_script
mkdir -p /usr/local/mha/ha1/workdir
/usr/local/mha:程序安装目录
/usr/local/mha/ha1:用于区别每一个mha方案,当前方案ha1
/usr/local/mha/ha1/fail_script:方案ha1的failover脚本保存路径
/usr/local/mha/ha1/workdir:方案ha1的的日志和failover产生的binlog保存路径
2.安装epel插件
使用yum方式安装,需要安装epel源
epel源
wget http://mirrors.ustc.edu.cn/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm
所有服务器都安装(mananage需要安装以下所有插件,node节点只需要安装perl-DBD-MySQL,cpan)
yum install -y perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes cpan
也可以使用perl方式安装
#!/bin/bash
wget http://xrl.us/cpanm --no-check-certificate
mv cpanm /usr/bin
chmod 755 /usr/bin/cpanm
cat > /root/list << EOF
install DBD::mysql
install Config::Tiny
install Log::Dispatch
install Parallel::ForkManager
install Time::HiRes
install CPAN
install Digest::SHA
EOF
for package in `cat /root/list`
do
cpanm $package
done
3.安装MHA Node软件包,所有服务器都要安装
tar -xvf mha4mysql-node-0.54.tar.gz cd mha4mysql-node-0.54 perl Makefile.PL INSTALL_BASE=/usr/local/mha make && make install
4.安装MHA Manager软件包,只在Manager主机上安装
tar -xvf mha4mysql-manager-0.55.tar.gz cd mha4mysql-manager-0.55 perl Makefile.PL INSTALL_BASE=/usr/local/mha make && make install
cp samples/scripts/* /usr/local/mha/bin/
master_ip_failover:自动切换时vip管理的脚本
master_ip_online_change:手动切换使用的脚本
power_manager:故障发生后关闭主机的脚本
send_report:发送报警的脚本。
5.修改环境变量
将MHA Manager主机的/usr/local/mha/bin加入环境变量
6.添加软链接
为了不麻烦所有服务器都执行吧,其实最后两个mysql,mysqlbinlog的软链接只有Node服务器需要添加,其它的所有服务器都需要添加。
mkdir -p /usr/local/bin mkdir -p /usr/local/share/man/man1 mkdir -p /usr/local/share/perl5/MHA ln -s /usr/local/mha/bin/* /usr/local/bin; ln -s /usr/local/mha/man/man1/* /usr/local/share/man/man1; ln -s /usr/local/mha/lib/perl5/MHA /usr/local/share/perl5/MHA; ln -s /usr/local/mysql/bin/mysqlbinlog /usr/local/bin/mysqlbinlog; ln -s /usr/local/mysql/bin/mysql /usr/local/bin/mysql;
二、配置MHA
1.配置SSH无密码登入
(1)在manage配置到所有Node节点的无密码登入
ssh-keygen -t rsa 一直enter,会在/root/.ssh/下面生成id_rsa.pub ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.10 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.20 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.30
(2)在Node 10配置到Node 20,30的无密码登入
ssh-keygen -t rsa ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.20 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.30
(3)在Node 20配置到Node 10,30的无密码登入
ssh-keygen -t rsa ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.10 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.30
(4)在Node 30配置到Node 10,20的无密码登入
ssh-keygen -t rsa ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.10 ssh-copy-id -i /root/.ssh/id_rsa.pub root@192.168.137.20
2. 搭建复制环境
复制环境之前已经搭建好,可以参考我前面写过的文章,复制用户和密码都是repl;每个Node上都必须创建这个repl账号,除非Node不作为故障专业的master
1.在所有Node上创建Manage监控用户
grant all privileges on *.* to 'root'@'192.168.137.%' identified by 'root';
三、配置Manage
1.配置启动文件
vim /usr/local/mha/ha1/ha1.cnf
[server default] manager_workdir=/usr/local/mha/ha1/workdir ##项目的主目录 manager_log=/usr/local/mha/ha1/workdir/manager.log ###mha记录日志 master_binlog_dir=/mysql/log ####node服务器的binlog存放路径,如果每个node的binlog路径不一致的话就在下面的每个server下面单独配置 master_ip_failover_script=/usr/local/mha/ha1/fail_script/master_ip_failover ####mha在线自动failover时处理VIP的配置文件 master_ip_online_change_script=/usr/local/mha/ha1/fail_script/master_ip_online_change ####在线手动执行master切换时VIP的处理文件 secondary_check_script=/usr/local/mha/bin/masterha_secondary_check -s backup -s master --user=root --master_host=master --master_ip=192.168.137.10 --master_port=3306 ##一旦MHA到master之间的网络出现问题,manager会尝试从backup登入到masger #report_script=/usr/local/mha/ha1/fail_script/send_report ###发生切换后执行的报警脚本 shutdown_script="" ####故障后关闭master主机的脚本(主要是使用keepalive做VIP时会出现脑裂导致VIP频繁切换所以会将故障的master关闭) ping_interval=1 ###监控mater,ping的频率 remote_workdir=/tmp ###node服务器在发生master切换时,binlog保持的路径,每个node都会在该目录下保存一份差异的binlog,除非没有差异。 repl_password=repl ##复制使用的用户名,每个node服务器都需要存在 repl_user=repl ##复制使用的密码 user=root ##mnager监控用的mysql root用户 password=root ##root用户密码 ssh_user=root ##ssh登入用户名 [server1] hostname=192.168.137.10 port=3306 candidate_master=1 check_repl_delay=0 [server2] hostname=192.168.137.20 port=3306 #master_binlog_dir=/mysql/log candidate_master=1 ##设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave check_repl_delay=0 ##默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master [server3] hostname=192.168.137.30 port=3306 ignore_fail=1 ####如果不加上该参数,当该slave主机故障了,mha将无法启动,加上该参数会忽略该主机是否正常,在mha启动的时候加上参数--ignore_fail_on_start no_master=1 ###不将该主机转换为master
注意:对于上面的配置一定要确保server1和server2之间是最新的binlog,一般会配置二者为双主的半同步复制,这样就保证了它们之间的binlog是最新的,否则应用差异的binlog将花费非常长的时间(如果它们和master延时非常大的情况下)
2.master_ip_failover
VIP的配置可以使用keepalived也可以写脚本,keepalived对网络的要求很高否则容易脑裂,在我前面搭建双主环境讲过keepalived的搭建方法,我这里使用脚本的方式。
 View Code
View Code注意:需要手动先在master服务器上面添加VIP
/sbin/ifconfig eth0:1 192.168.137.50/24
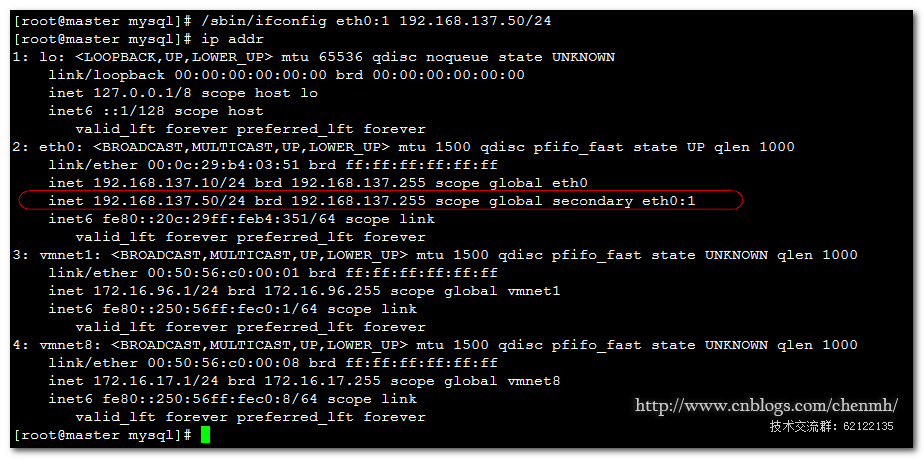
3.master_ip_online_change
perl脚本
#!/usr/bin/env perl
use strict;
use warnings FATAL =>'all';
use Getopt::Long;
my $vip = '192.168.137.50/24'; # Virtual IP
my $key = "1";
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
my $exit_code = 0;
my (
$command, $orig_master_is_new_slave, $orig_master_host,
$orig_master_ip, $orig_master_port, $orig_master_user,
$orig_master_password, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password,
);
GetOptions(
'command=s' => \$command,
'orig_master_is_new_slave' => \$orig_master_is_new_slave,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'orig_master_user=s' => \$orig_master_user,
'orig_master_password=s' => \$orig_master_password,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
);
exit &main();
sub main {
#print "\n\nIN SCRIPT TEST====$ssh_stop_vip==$ssh_start_vip===\n\n";
if ( $command eq "stop" || $command eq "stopssh" ) {
# $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = 1;
eval {
print "\n\n\n***************************************************************\n";
print "Disabling the VIP - $vip on old master: $orig_master_host\n";
print "***************************************************************\n\n\n\n";
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
# all arguments are passed.
# If you manage master ip address at global catalog database,
# activate new_master_ip here.
# You can also grant write access (create user, set read_only=0, etc) here.
my $exit_code = 10;
eval {
print "\n\n\n***************************************************************\n";
print "Enabling the VIP - $vip on new master: $new_master_host \n";
print "***************************************************************\n\n\n\n";
&start_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
`ssh $orig_master_user\@$orig_master_host \" $ssh_start_vip \"`;
exit 0;
}
else {
&usage();
exit 1;
}
}
# A simple system call that enable the VIP on the new master
sub start_vip() {
`ssh $new_master_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $orig_master_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
shell脚本
#/bin/bash
#source /root/.bash_profile
vip=`echo '192.168.137.50/24'` # Virtual IP
key=`echo '1'`
command=`echo "$1" | awk -F = '{print $2}'`
orig_master_host=`echo "$2" | awk -F = '{print $2}'`
new_master_host=`echo "$7" | awk -F = '{print $2}'`
stop_vip=`echo "ssh root@$orig_master_host /sbin/ifconfig eth0:$key down"`
start_vip=`echo "ssh root@$new_master_host /sbin/ifconfig eth0:$key $vip"`
if [ $command = 'stop' ]
then
echo -e "\n\n\n***************************************************************\n"
echo -e "Disabling the VIP - $vip on old master: $orig_master_host\n"
$stop_vip
if [ $? -eq 0 ]
then
echo "Disabled the VIP successfully"
else
echo "Disabled the VIP failed"
fi
echo -e "***************************************************************\n\n\n\n"
fi
if [ $command = 'start' -o $command = 'status' ]
then
echo -e "\n\n\n***************************************************************\n"
echo -e "Enabling the VIP - $vip on new master: $new_master_host \n"
$start_vip
if [ $? -eq 0 ]
then
echo "Enabled the VIP successfully"
else
echo "Enabled the VIP failed"
fi
echo -e "***************************************************************\n\n\n\n"
fi
4.send_report
View Code四、配置relay_log的清除方式(在每个Node上)
(1)所有Node的cnf配置文件加上
relay_log_purge=0
MHA在发生切换的过程中,从库的恢复过程中依赖于relay log的相关信息,所以这里要将relay log的自动清除设置为OFF,采用手动清除relay log的方式。
在默认情况下,从服务器上的中继日志会在SQL线程执行完毕后被自动删除。但是在MHA环境中,这些中继日志在恢复其他从服务器时可能会被用到,因此需要禁用中继日志的自动删除功能。定期清除中继日志需要考虑到复制延时的问题。在ext3的文件系统下,删除大的文件需要一定的时间,会导致严重的复制延时。为了避免复制延时,需要暂时为中继日志创建硬链接,因为在linux系统中通过硬链接删除大文件速度会很快。
提示:在mysql数据库中,删除大表时,通常也采用建立硬链接的方式
MHA节点中包含了pure_relay_logs命令工具,它可以为中继日志创建硬链接,执行SET GLOBAL relay_log_purge=1,等待几秒钟以便SQL线程切换到新的中继日志,再执行SET GLOBAL relay_log_purge=0。
pure_relay_logs脚本参数如下所示:
--user mysql 用户名 --password mysql 密码 --port 端口号 --workdir 指定创建relay log的硬链接的位置,默认是/var/tmp,由于系统不同分区创建硬链接文件会失败,故需要执行硬链接具体位置,成功执行脚本后,硬链接的中继日志文件被删除 --disable_relay_log_purge 默认情况下,如果relay_log_purge=1,脚本会什么都不清理,自动退出,通过设定这个参数,当relay_log_purge=1的情况下会将relay_log_purge设置为0。清理relay log之后,最后将参数设置为OFF。
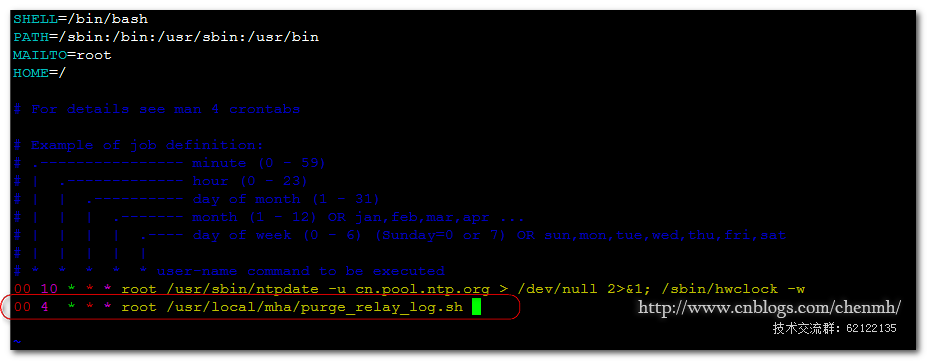
(2)在每台slave Node上创建
vim /usr/local/mha/purge_relay_log.sh
#!/bin/bash user=root passwd=root ####确保用户和密码能通过127.0.0.1登入 host='127.0.0.1' port=3306 work_dir='/mysql/data' purge='/usr/local/mha/bin/purge_relay_logs' $purge --user=$user --password=$passwd --host=$host --disable_relay_log_purge --port=$port --workdir=$work_dir >> /usr/local/mha/purge_relay_logs.log 2>&1
chmod u+x /usr/local/mha/purge_relay_log.sh
将脚本加入到os定时任务中
五、检测启动MHA
1.检查ssh配置
masterha_check_ssh --conf=/usr/local/mha/ha1/ha1.cnf
[root@monitor ha1]# masterha_check_ssh --conf=/usr/local/mha/ha1/ha1.cnf Thu Aug 25 14:53:30 2016 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Thu Aug 25 14:53:30 2016 - [info] Reading application default configurations from /usr/local/mha/ha1/ha1.cnf.. Thu Aug 25 14:53:30 2016 - [info] Reading server configurations from /usr/local/mha/ha1/ha1.cnf.. Thu Aug 25 14:53:30 2016 - [info] Starting SSH connection tests.. Thu Aug 25 14:53:35 2016 - [debug] Thu Aug 25 14:53:31 2016 - [debug] Connecting via SSH from root@192.168.137.20(192.168.137.20:22) to root@192.168.137.10(192.168.137.10:22).. Thu Aug 25 14:53:33 2016 - [debug] ok. Thu Aug 25 14:53:33 2016 - [debug] Connecting via SSH from root@192.168.137.20(192.168.137.20:22) to root@192.168.137.30(192.168.137.30:22).. Thu Aug 25 14:53:34 2016 - [debug] ok. Thu Aug 25 14:53:35 2016 - [debug] Thu Aug 25 14:53:31 2016 - [debug] Connecting via SSH from root@192.168.137.30(192.168.137.30:22) to root@192.168.137.10(192.168.137.10:22).. Thu Aug 25 14:53:33 2016 - [debug] ok. Thu Aug 25 14:53:33 2016 - [debug] Connecting via SSH from root@192.168.137.30(192.168.137.30:22) to root@192.168.137.20(192.168.137.20:22).. Thu Aug 25 14:53:34 2016 - [debug] ok. Thu Aug 25 14:53:36 2016 - [debug] Thu Aug 25 14:53:30 2016 - [debug] Connecting via SSH from root@192.168.137.10(192.168.137.10:22) to root@192.168.137.20(192.168.137.20:22).. Thu Aug 25 14:53:34 2016 - [debug] ok. Thu Aug 25 14:53:34 2016 - [debug] Connecting via SSH from root@192.168.137.10(192.168.137.10:22) to root@192.168.137.30(192.168.137.30:22).. Thu Aug 25 14:53:35 2016 - [debug] ok. Thu Aug 25 14:53:36 2016 - [info] All SSH connection tests passed successfully.
可以看到每个Node到其它的Node都是相通的。
2.检查整个复制环境
masterha_check_repl --conf=/usr/local/mha/ha1/ha1.cnf
View Code--ignore_fail_on_start: 当有slave 节点宕掉时,默认是启动不了的,加上 --ignore_fail_on_start 即使有节点宕掉也能启动MHA,加上该参数会忽略启动文件中配置ignore_fail=1的server
3.检查MHA Manager状态
masterha_check_status --conf=/usr/local/mha/ha1/ha1.cnf

由于mha还没有启动,所以这里检测是stopped
4.启动MHA
nohup masterha_manager --conf=/usr/local/mha/ha1/ha1.cnf --ignore_fail_on_start --ignore_last_failover < /dev/null > /usr/local/mha/ha1/start.log 2>&1 &
--remove_dead_master_conf:该参数代表当发生主从切换后,老的主库的ip将会从配置文件中移除。这里暂时不使用该参数,因为发生使用该参数会将ha1.cnf配置文件搞乱。
--start_log:日志。
--ignore_last_failover:发生主从切换后,MHAmanager服务会自动停掉,且在manager_workdir目录下面生成文件app1.failover.complete,若要启动MHA,必须先删除该文件,该参数代表忽略上次MHA触发切换产生的文件,这里设置为-ignore_last_failover。 在缺省情况下,如果MHA检测到连续发生宕机,且两次宕机间隔不足8小时的话,则不会进行Failover,之所以这样限制是为了避免ping-pong效应。
--ignore_fail_on_start: 当有slave 节点宕掉时,默认是启动不了的,加上 --ignore_fail_on_start 即使有节点宕掉也能启动MHA,加上该参数会忽略启动文件中配置ignore_fail=1的server。
(1)再次查看MHA状态是否正常:
[root@monitor ha1]# masterha_check_status --conf=/usr/local/mha/ha1/ha1.cnf ha1 (pid:6371) is running(0:PING_OK), master:192.168.137.10 [root@monitor ha1]#
(2)查看启动日志
cat manager.log
Thu Aug 25 17:11:50 2016 - [info] 192.168.137.10 (current master) +--192.168.137.20 +--192.168.137.30 Thu Aug 25 17:11:50 2016 - [info] Checking master_ip_failover_script status: Thu Aug 25 17:11:50 2016 - [info] /usr/local/mha/ha1/fail_script/master_ip_failover --command=status --ssh_user=root --orig_master_host=192.168.137.10 --orig_master_ip=192.168.137.10 --orig_master_port=3306 IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.137.50/24=== Checking the Status of the script.. OK Thu Aug 25 17:11:50 2016 - [info] OK. Thu Aug 25 17:11:50 2016 - [warning] shutdown_script is not defined. Thu Aug 25 17:11:50 2016 - [info] Set master ping interval 1 seconds. Thu Aug 25 17:11:50 2016 - [info] Set secondary check script: /usr/local/mha/bin/masterha_secondary_check -s backup -s master --user=root --master_host=master --master_ip=192.168.137.10 --master_port=3306 Thu Aug 25 17:11:50 2016 - [info] Starting ping health check on 192.168.137.10(192.168.137.10:3306).. Thu Aug 25 17:11:50 2016 - [info] Ping(SELECT) succeeded, waiting until MySQL doesn't respond.. [root@monitor ha1]#
(3)产生的文件
ha1.master_status.health:mha正常启动会产生该文件
manager.log:mha监控日志
start.log:mha启动时生成的日志
5.关闭MHA
masterha_stop --conf=/usr/local/mha/ha1/ha1.cnf
六、故障处理步骤
发生主从切换后,MHA服务会自动停掉
1.检查日志
检查故障处理的日志,确保故障正常转移。
cat /usr/local/mha/ha1/manager.log
2.处理故障master
处理故障的master,将其配置为从库chang到新的master,可以从manager.log找到change语句。
grep "CHANGE MASTER TO MASTER" /usr/local/mha/ha1/manager.log | tail -1
Fri Aug 26 12:04:22 2016 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.137.10', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000143', MASTER_LOG_POS=22123166, MASTER_USER='repl', MASTER_PASSWORD='xxx';
注意:这里要确保slave的SQL_THREAD和IO_TRREAD正常,如果是配置半同步复制要确保半同步复制启动正常,可以执行"show status like '%rpl_%';",具体参考前面半同步复制的搭建。
3.修改ha1.cnf配置文件
需要修改"secondary_check_script"选项中的master_host、master_ip、master_port为新的master;如果两台电脑的配置都相同的话其它地方不用修改。
4.删除fail文件(非必需)
由于启动mha的时候加上了--ignore_last_failover参数,所以不删除failower生成的文件也能启动,否则需要删除failower生成的文件“ha1.failover.complete”。
rm -f /usr/local/mha/ha1/ha1.failover.complete
5.check检查
检查SSH配置 masterha_check_ssh --conf=/usr/local/mha/ha1/ha1.cnf 检查复制 masterha_check_repl --conf=/usr/local/mha/ha1/ha1.cnf 检查状态 masterha_check_status --conf=/usr/local/mha/ha1/ha1.cnf
必需保证所有的检查都通过
6.启动MHA
nohup masterha_manager --conf=/usr/local/mha/ha1/ha1.cnf --ignore_fail_on_start --ignore_last_failover < /dev/null > /usr/local/mha/ha1/start.log 2>&1 &
七、模拟Failover
1.自动failover
我这里是异步复制,137.20是当前的master,然后在137.20上执行并发插入,同时关闭137.10和137.30的IO线程,在137.20上压测一段时间,然后先开启137.30的IO线程,过几秒钟再开启137.10的IO线程;保证137.30的binlog比候选的137.10的binlog更新。
master 137.20(22497564)
candidate slave:137.10(pos=9857376)
new replay slave:137.30(pos=22461852)
Fri Aug 26 11:57:36 2016 - [warning] Got error on MySQL select ping: 2013 (Lost connection to MySQL server during query)
Fri Aug 26 11:57:36 2016 - [info] Executing SSH check script: save_binary_logs --command=test --start_pos=4 --binlog_dir=/mysql/log --output_file=/tmp/save_binary_logs_test --manager_version=0.55 --binlog_prefix=mysql-bin
Fri Aug 26 11:57:36 2016 - [info] Executing seconary network check script: /usr/local/mha/bin/masterha_secondary_check -s backup -s master --user=root --master_host=master --master_ip=192.168.137.10 --master_port=3306 --user=root --master_host=192.168.137.20 --master_ip=192.168.137.20 --master_port=3306
Fri Aug 26 11:57:37 2016 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.137.20' (111))
Fri Aug 26 11:57:37 2016 - [warning] Connection failed 1 time(s)..
Fri Aug 26 11:57:38 2016 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.137.20' (111))
Fri Aug 26 11:57:38 2016 - [warning] Connection failed 2 time(s)..
Fri Aug 26 11:57:38 2016 - [info] HealthCheck: SSH to 192.168.137.20 is reachable.
Monitoring server backup is reachable, Master is not reachable from backup. OK.
Fri Aug 26 11:57:39 2016 - [warning] Got error on MySQL connect: 2003 (Can't connect to MySQL server on '192.168.137.20' (111))
Fri Aug 26 11:57:39 2016 - [warning] Connection failed 3 time(s)..
Monitoring server master is reachable, Master is not reachable from master. OK.
Fri Aug 26 11:57:41 2016 - [info] Master is not reachable from all other monitoring servers. Failover should start.
Fri Aug 26 11:57:41 2016 - [warning] Master is not reachable from health checker!
Fri Aug 26 11:57:41 2016 - [warning] Master 192.168.137.20(192.168.137.20:3306) is not reachable!
Fri Aug 26 11:57:41 2016 - [warning] SSH is reachable.
Fri Aug 26 11:57:41 2016 - [info] Connecting to a master server failed. Reading configuration file /etc/masterha_default.cnf and /usr/local/mha/ha1/ha1.cnf again, and trying to connect to all servers to check server status..
Fri Aug 26 11:57:41 2016 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping.
Fri Aug 26 11:57:41 2016 - [info] Reading application default configurations from /usr/local/mha/ha1/ha1.cnf..
Fri Aug 26 11:57:41 2016 - [info] Reading server configurations from /usr/local/mha/ha1/ha1.cnf..
Fri Aug 26 11:57:42 2016 - [info] Dead Servers:
Fri Aug 26 11:57:42 2016 - [info] 192.168.137.20(192.168.137.20:3306)
Fri Aug 26 11:57:42 2016 - [info] Alive Servers:
Fri Aug 26 11:57:42 2016 - [info] 192.168.137.10(192.168.137.10:3306)
Fri Aug 26 11:57:42 2016 - [info] 192.168.137.30(192.168.137.30:3306)
Fri Aug 26 11:57:42 2016 - [info] Alive Slaves:
Fri Aug 26 11:57:42 2016 - [info] 192.168.137.10(192.168.137.10:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled
Fri Aug 26 11:57:42 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306)
Fri Aug 26 11:57:42 2016 - [info] Primary candidate for the new Master (candidate_master is set)
Fri Aug 26 11:57:42 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled
Fri Aug 26 11:57:42 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306)
Fri Aug 26 11:57:42 2016 - [info] Not candidate for the new Master (no_master is set)
Fri Aug 26 11:57:42 2016 - [info] Checking slave configurations..
Fri Aug 26 11:57:42 2016 - [info] read_only=1 is not set on slave 192.168.137.10(192.168.137.10:3306).
Fri Aug 26 11:57:42 2016 - [info] Checking replication filtering settings..
Fri Aug 26 11:57:42 2016 - [info] Replication filtering check ok.
Fri Aug 26 11:57:42 2016 - [info] Master is down!
Fri Aug 26 11:57:42 2016 - [info] Terminating monitoring script.
Fri Aug 26 11:57:42 2016 - [info] Got exit code 20 (Master dead).
Fri Aug 26 11:57:42 2016 - [info] MHA::MasterFailover version 0.55.
Fri Aug 26 11:57:42 2016 - [info] Starting master failover.
Fri Aug 26 11:57:42 2016 - [info]
Fri Aug 26 11:57:42 2016 - [info] * Phase 1: Configuration Check Phase..
Fri Aug 26 11:57:42 2016 - [info]
Fri Aug 26 11:57:44 2016 - [info] Dead Servers:
Fri Aug 26 11:57:44 2016 - [info] 192.168.137.20(192.168.137.20:3306)
Fri Aug 26 11:57:44 2016 - [info] Checking master reachability via mysql(double check)..
Fri Aug 26 11:57:44 2016 - [info] ok.
Fri Aug 26 11:57:44 2016 - [info] Alive Servers:
Fri Aug 26 11:57:44 2016 - [info] 192.168.137.10(192.168.137.10:3306)
Fri Aug 26 11:57:44 2016 - [info] 192.168.137.30(192.168.137.30:3306)
Fri Aug 26 11:57:44 2016 - [info] Alive Slaves:
Fri Aug 26 11:57:44 2016 - [info] 192.168.137.10(192.168.137.10:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled
Fri Aug 26 11:57:44 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306)
Fri Aug 26 11:57:44 2016 - [info] Primary candidate for the new Master (candidate_master is set)
Fri Aug 26 11:57:44 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled
Fri Aug 26 11:57:44 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306)
Fri Aug 26 11:57:44 2016 - [info] Not candidate for the new Master (no_master is set)
Fri Aug 26 11:57:44 2016 - [info] ** Phase 1: Configuration Check Phase completed.
Fri Aug 26 11:57:44 2016 - [info]
Fri Aug 26 11:57:44 2016 - [info] * Phase 2: Dead Master Shutdown Phase..
Fri Aug 26 11:57:44 2016 - [info]
Fri Aug 26 11:57:44 2016 - [info] Forcing shutdown so that applications never connect to the current master..
Fri Aug 26 11:57:44 2016 - [info] Executing master IP deactivatation script:
Fri Aug 26 11:57:44 2016 - [info] /usr/local/mha/ha1/fail_script/master_ip_failover --orig_master_host=192.168.137.20 --orig_master_ip=192.168.137.20 --orig_master_port=3306 --command=stopssh --ssh_user=root
IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.137.50/24===
Disabling the VIP on old master: 192.168.137.20
Fri Aug 26 11:57:45 2016 - [info] done.
Fri Aug 26 11:57:45 2016 - [warning] shutdown_script is not set. Skipping explicit shutting down of the dead master.
Fri Aug 26 11:57:45 2016 - [info] * Phase 2: Dead Master Shutdown Phase completed.
Fri Aug 26 11:57:45 2016 - [info]
Fri Aug 26 11:57:45 2016 - [info] * Phase 3: Master Recovery Phase..
Fri Aug 26 11:57:45 2016 - [info]
Fri Aug 26 11:57:45 2016 - [info] * Phase 3.1: Getting Latest Slaves Phase..
Fri Aug 26 11:57:45 2016 - [info]
Fri Aug 26 11:57:45 2016 - [info] The latest binary log file/position on all slaves is mysql-bin.000074:22461852
Fri Aug 26 11:57:45 2016 - [info] Latest slaves (Slaves that received relay log files to the latest):
Fri Aug 26 11:57:45 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled
Fri Aug 26 11:57:45 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306)
Fri Aug 26 11:57:45 2016 - [info] Not candidate for the new Master (no_master is set)
Fri Aug 26 11:57:45 2016 - [info] The oldest binary log file/position on all slaves is mysql-bin.000074:9857376
Fri Aug 26 11:57:45 2016 - [info] Oldest slaves:
Fri Aug 26 11:57:45 2016 - [info] 192.168.137.10(192.168.137.10:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled
Fri Aug 26 11:57:45 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306)
Fri Aug 26 11:57:45 2016 - [info] Primary candidate for the new Master (candidate_master is set)
Fri Aug 26 11:57:45 2016 - [info]
Fri Aug 26 11:57:45 2016 - [info] * Phase 3.2: Saving Dead Master's Binlog Phase..
Fri Aug 26 11:57:45 2016 - [info]
Fri Aug 26 11:57:46 2016 - [info] Fetching dead master's binary logs..
Fri Aug 26 11:57:46 2016 - [info] Executing command on the dead master 192.168.137.20(192.168.137.20:3306): save_binary_logs --command=save --start_file=mysql-bin.000074 --start_pos=22461852 --binlog_dir=/mysql/log --output_file=/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55
Creating /tmp if not exists.. ok.
Concat binary/relay logs from mysql-bin.000074 pos 22461852 to mysql-bin.000074 EOF into /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog ..
Dumping binlog format description event, from position 0 to 120.. ok.
Dumping effective binlog data from /mysql/log/mysql-bin.000074 position 22461852 to tail(22497564).. ok.
Concat succeeded.
Fri Aug 26 11:57:49 2016 - [info] scp from root@192.168.137.20:/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog to local:/usr/local/mha/ha1/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog succeeded.
Fri Aug 26 11:57:52 2016 - [info] HealthCheck: SSH to 192.168.137.10 is reachable.
Fri Aug 26 11:57:55 2016 - [info] HealthCheck: SSH to 192.168.137.30 is reachable.
Fri Aug 26 11:57:55 2016 - [info]
Fri Aug 26 11:57:55 2016 - [info] * Phase 3.3: Determining New Master Phase..
Fri Aug 26 11:57:55 2016 - [info]
Fri Aug 26 11:57:55 2016 - [info] Finding the latest slave that has all relay logs for recovering other slaves..
Fri Aug 26 11:57:55 2016 - [info] Checking whether 192.168.137.30 has relay logs from the oldest position..
Fri Aug 26 11:57:55 2016 - [info] Executing command: apply_diff_relay_logs --command=find --latest_mlf=mysql-bin.000074 --latest_rmlp=22461852 --target_mlf=mysql-bin.000074 --target_rmlp=9857376 --server_id=30 --workdir=/tmp --timestamp=20160826115742 --manager_version=0.55 --relay_log_info=/mysql/data/relay-log.info --relay_dir=/mysql/data/ :
Opening /mysql/data/relay-log.info ... ok.
Relay log found at /mysql/data, up to mysql-relay-bin.000003
Fast relay log position search succeeded.
Target relay log file/position found. start_file:mysql-relay-bin.000003, start_pos:9857539.
Target relay log FOUND!
Fri Aug 26 11:57:56 2016 - [info] OK. 192.168.137.30 has all relay logs.
Fri Aug 26 11:57:56 2016 - [info] Searching new master from slaves..
Fri Aug 26 11:57:56 2016 - [info] Candidate masters from the configuration file:
Fri Aug 26 11:57:56 2016 - [info] 192.168.137.10(192.168.137.10:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled
Fri Aug 26 11:57:56 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306)
Fri Aug 26 11:57:56 2016 - [info] Primary candidate for the new Master (candidate_master is set)
Fri Aug 26 11:57:56 2016 - [info] Non-candidate masters:
Fri Aug 26 11:57:56 2016 - [info] 192.168.137.30(192.168.137.30:3306) Version=5.6.15-log (oldest major version between slaves) log-bin:enabled
Fri Aug 26 11:57:56 2016 - [info] Replicating from 192.168.137.20(192.168.137.20:3306)
Fri Aug 26 11:57:56 2016 - [info] Not candidate for the new Master (no_master is set)
Fri Aug 26 11:57:56 2016 - [info] Searching from candidate_master slaves which have received the latest relay log events..
Fri Aug 26 11:57:56 2016 - [info] Not found.
Fri Aug 26 11:57:56 2016 - [info] Searching from all candidate_master slaves..
Fri Aug 26 11:57:56 2016 - [info] New master is 192.168.137.10(192.168.137.10:3306)
Fri Aug 26 11:57:56 2016 - [info] Starting master failover..
Fri Aug 26 11:57:56 2016 - [info]
From:
192.168.137.20 (current master)
+--192.168.137.10
+--192.168.137.30
To:
192.168.137.10 (new master)
+--192.168.137.30
Fri Aug 26 11:57:56 2016 - [info]
Fri Aug 26 11:57:56 2016 - [info] * Phase 3.3: New Master Diff Log Generation Phase..
Fri Aug 26 11:57:56 2016 - [info]
Fri Aug 26 11:57:56 2016 - [info] Server 192.168.137.10 received relay logs up to: mysql-bin.000074:9857376
Fri Aug 26 11:57:56 2016 - [info] Need to get diffs from the latest slave(192.168.137.30) up to: mysql-bin.000074:22461852 (using the latest slave's relay logs)
Fri Aug 26 11:57:56 2016 - [info] Connecting to the latest slave host 192.168.137.30, generating diff relay log files..
Fri Aug 26 11:57:56 2016 - [info] Executing command: apply_diff_relay_logs --command=generate_and_send --scp_user=root --scp_host=192.168.137.10 --latest_mlf=mysql-bin.000074 --latest_rmlp=22461852 --target_mlf=mysql-bin.000074 --target_rmlp=9857376 --server_id=30 --diff_file_readtolatest=/tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog --workdir=/tmp --timestamp=20160826115742 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 --relay_log_info=/mysql/data/relay-log.info --relay_dir=/mysql/data/
Fri Aug 26 11:58:02 2016 - [info]
Opening /mysql/data/relay-log.info ... ok.
Relay log found at /mysql/data, up to mysql-relay-bin.000003
Fast relay log position search succeeded.
Target relay log file/position found. start_file:mysql-relay-bin.000003, start_pos:9857539.
Concat binary/relay logs from mysql-relay-bin.000003 pos 9857539 to mysql-relay-bin.000003 EOF into /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog ..
Dumping binlog format description event, from position 0 to 283.. ok.
Dumping effective binlog data from /mysql/data/mysql-relay-bin.000003 position 9857539 to tail(22462015).. ok.
Concat succeeded.
Generating diff relay log succeeded. Saved at /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog .
scp slave:/tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog to root@192.168.137.10(22) succeeded.
Fri Aug 26 11:58:02 2016 - [info] Generating diff files succeeded.
Fri Aug 26 11:58:02 2016 - [info] Sending binlog..
Fri Aug 26 11:58:04 2016 - [info] scp from local:/usr/local/mha/ha1/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog to root@192.168.137.10:/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog succeeded.
Fri Aug 26 11:58:04 2016 - [info]
Fri Aug 26 11:58:04 2016 - [info] * Phase 3.4: Master Log Apply Phase..
Fri Aug 26 11:58:04 2016 - [info]
Fri Aug 26 11:58:04 2016 - [info] *NOTICE: If any error happens from this phase, manual recovery is needed.
Fri Aug 26 11:58:04 2016 - [info] Starting recovery on 192.168.137.10(192.168.137.10:3306)..
Fri Aug 26 11:58:04 2016 - [info] Generating diffs succeeded.
Fri Aug 26 11:58:04 2016 - [info] Waiting until all relay logs are applied.
Fri Aug 26 12:00:06 2016 - [info] done.
Fri Aug 26 12:00:06 2016 - [info] Getting slave status..
Fri Aug 26 12:00:06 2016 - [info] This slave(192.168.137.10)'s Exec_Master_Log_Pos equals to Read_Master_Log_Pos(mysql-bin.000074:9857376). No need to recover from Exec_Master_Log_Pos.
Fri Aug 26 12:00:06 2016 - [info] Connecting to the target slave host 192.168.137.10, running recover script..
Fri Aug 26 12:00:06 2016 - [info] Executing command: apply_diff_relay_logs --command=apply --slave_user='root' --slave_host=192.168.137.10 --slave_ip=192.168.137.10 --slave_port=3306 --apply_files=/tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog,/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog --workdir=/tmp --target_version=5.6.15-log --timestamp=20160826115742 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 --slave_pass=xxx
Fri Aug 26 12:04:22 2016 - [info]
Concat all apply files to /tmp/total_binlog_for_192.168.137.10_3306.20160826115742.binlog ..
Copying the first binlog file /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog to /tmp/total_binlog_for_192.168.137.10_3306.20160826115742.binlog.. ok.
Dumping binlog head events (rotate events), skipping format description events from /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog.. dumped up to pos 120. ok.
/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog has effective binlog events from pos 120.
Dumping effective binlog data from /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog position 120 to tail(35832).. ok.
Concat succeeded.
All apply target binary logs are concatinated at /tmp/total_binlog_for_192.168.137.10_3306.20160826115742.binlog .
MySQL client version is 5.6.15. Using --binary-mode.
Applying differential binary/relay log files /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog,/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog on 192.168.137.10:3306. This may take long time...
Applying log files succeeded.
Fri Aug 26 12:04:22 2016 - [info] All relay logs were successfully applied.
Fri Aug 26 12:04:22 2016 - [info] Getting new master's binlog name and position..
Fri Aug 26 12:04:22 2016 - [info] mysql-bin.000143:22123166
Fri Aug 26 12:04:22 2016 - [info] All other slaves should start replication from here. Statement should be: CHANGE MASTER TO MASTER_HOST='192.168.137.10', MASTER_PORT=3306, MASTER_LOG_FILE='mysql-bin.000143', MASTER_LOG_POS=22123166, MASTER_USER='repl', MASTER_PASSWORD='xxx';
Fri Aug 26 12:04:22 2016 - [info] Executing master IP activate script:
Fri Aug 26 12:04:22 2016 - [info] /usr/local/mha/ha1/fail_script/master_ip_failover --command=start --ssh_user=root --orig_master_host=192.168.137.20 --orig_master_ip=192.168.137.20 --orig_master_port=3306 --new_master_host=192.168.137.10 --new_master_ip=192.168.137.10 --new_master_port=3306 --new_master_user='root' --new_master_password='root'
IN SCRIPT TEST====/sbin/ifconfig eth0:1 down==/sbin/ifconfig eth0:1 192.168.137.50/24===
Enabling the VIP - 192.168.137.50/24 on the new master - 192.168.137.10
Fri Aug 26 12:04:25 2016 - [info] OK.
Fri Aug 26 12:04:25 2016 - [info] ** Finished master recovery successfully.
Fri Aug 26 12:04:25 2016 - [info] * Phase 3: Master Recovery Phase completed.
Fri Aug 26 12:04:25 2016 - [info]
Fri Aug 26 12:04:25 2016 - [info] * Phase 4: Slaves Recovery Phase..
Fri Aug 26 12:04:25 2016 - [info]
Fri Aug 26 12:04:25 2016 - [info] * Phase 4.1: Starting Parallel Slave Diff Log Generation Phase..
Fri Aug 26 12:04:25 2016 - [info]
Fri Aug 26 12:04:25 2016 - [info] -- Slave diff file generation on host 192.168.137.30(192.168.137.30:3306) started, pid: 5029. Check tmp log /usr/local/mha/ha1/192.168.137.30_3306_20160826115742.log if it takes time..
Fri Aug 26 12:04:26 2016 - [info]
Fri Aug 26 12:04:26 2016 - [info] Log messages from 192.168.137.30 ...
Fri Aug 26 12:04:26 2016 - [info]
Fri Aug 26 12:04:25 2016 - [info] This server has all relay logs. No need to generate diff files from the latest slave.
Fri Aug 26 12:04:26 2016 - [info] End of log messages from 192.168.137.30.
Fri Aug 26 12:04:26 2016 - [info] -- 192.168.137.30(192.168.137.30:3306) has the latest relay log events.
Fri Aug 26 12:04:26 2016 - [info] Generating relay diff files from the latest slave succeeded.
Fri Aug 26 12:04:26 2016 - [info]
Fri Aug 26 12:04:26 2016 - [info] * Phase 4.2: Starting Parallel Slave Log Apply Phase..
Fri Aug 26 12:04:26 2016 - [info]
Fri Aug 26 12:04:26 2016 - [info] -- Slave recovery on host 192.168.137.30(192.168.137.30:3306) started, pid: 5031. Check tmp log /usr/local/mha/ha1/192.168.137.30_3306_20160826115742.log if it takes time..
Fri Aug 26 12:04:32 2016 - [info]
Fri Aug 26 12:04:32 2016 - [info] Log messages from 192.168.137.30 ...
Fri Aug 26 12:04:32 2016 - [info]
Fri Aug 26 12:04:26 2016 - [info] Sending binlog..
Fri Aug 26 12:04:28 2016 - [info] scp from local:/usr/local/mha/ha1/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog to root@192.168.137.30:/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog succeeded.
Fri Aug 26 12:04:28 2016 - [info] Starting recovery on 192.168.137.30(192.168.137.30:3306)..
Fri Aug 26 12:04:28 2016 - [info] Generating diffs succeeded.
Fri Aug 26 12:04:28 2016 - [info] Waiting until all relay logs are applied.
Fri Aug 26 12:04:28 2016 - [info] done.
Fri Aug 26 12:04:28 2016 - [info] Getting slave status..
Fri Aug 26 12:04:28 2016 - [info] This slave(192.168.137.30)'s Exec_Master_Log_Pos equals to Read_Master_Log_Pos(mysql-bin.000074:22461852). No need to recover from Exec_Master_Log_Pos.
Fri Aug 26 12:04:28 2016 - [info] Connecting to the target slave host 192.168.137.30, running recover script..
Fri Aug 26 12:04:28 2016 - [info] Executing command: apply_diff_relay_logs --command=apply --slave_user='root' --slave_host=192.168.137.30 --slave_ip=192.168.137.30 --slave_port=3306 --apply_files=/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog --workdir=/tmp --target_version=5.6.15-log --timestamp=20160826115742 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 --slave_pass=xxx
Fri Aug 26 12:04:30 2016 - [info]
MySQL client version is 5.6.15. Using --binary-mode.
Applying differential binary/relay log files /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog on 192.168.137.30:3306. This may take long time...
Applying log files succeeded.
Fri Aug 26 12:04:30 2016 - [info] All relay logs were successfully applied.
Fri Aug 26 12:04:30 2016 - [info] Resetting slave 192.168.137.30(192.168.137.30:3306) and starting replication from the new master 192.168.137.10(192.168.137.10:3306)..
Fri Aug 26 12:04:31 2016 - [info] Executed CHANGE MASTER.
Fri Aug 26 12:04:31 2016 - [info] Slave started.
Fri Aug 26 12:04:32 2016 - [info] End of log messages from 192.168.137.30.
Fri Aug 26 12:04:32 2016 - [info] -- Slave recovery on host 192.168.137.30(192.168.137.30:3306) succeeded.
Fri Aug 26 12:04:32 2016 - [info] All new slave servers recovered successfully.
Fri Aug 26 12:04:32 2016 - [info]
Fri Aug 26 12:04:32 2016 - [info] * Phase 5: New master cleanup phase..
Fri Aug 26 12:04:32 2016 - [info]
Fri Aug 26 12:04:32 2016 - [info] Resetting slave info on the new master..
Fri Aug 26 12:04:32 2016 - [info] 192.168.137.10: Resetting slave info succeeded.
Fri Aug 26 12:04:32 2016 - [info] Master failover to 192.168.137.10(192.168.137.10:3306) completed successfully.
Fri Aug 26 12:04:32 2016 - [info]
----- Failover Report -----
ha1: MySQL Master failover 192.168.137.20 to 192.168.137.10 succeeded
Master 192.168.137.20 is down!
Check MHA Manager logs at monitor:/usr/local/mha/ha1/manager.log for details.
Started automated(non-interactive) failover.
Invalidated master IP address on 192.168.137.20.
The latest slave 192.168.137.30(192.168.137.30:3306) has all relay logs for recovery.
Selected 192.168.137.10 as a new master.
192.168.137.10: OK: Applying all logs succeeded.
192.168.137.10: OK: Activated master IP address.
192.168.137.30: This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
192.168.137.30: OK: Applying all logs succeeded. Slave started, replicating from 192.168.137.10.
192.168.137.10: Resetting slave info succeeded.
Master failover to 192.168.137.10(192.168.137.10:3306) completed successfully.
说明:用红色标记了一些主要的处理过程,亮色加粗标记了每个步骤总共5个步骤
Failover步骤如下:
1.fail判断,分别判断dead master的mysql(Ping(SELECT))和ssh分别到达情况(之间会调用masterha_secondary_check脚本)→dead master处理阶段
2.配置文件检查,会检查整个集群配置文件配置(分别确定dead server,候选的master和所有的server的配置情况以及配置是否满足条件)→dead master处理阶段
3.宕机的master处理,包括虚拟ip摘除操作,主机关机操作(这里暂时没有配置关机操作)→dead master处理阶段
/usr/local/mha/ha1/fail_script/master_ip_failover --orig_master_host=192.168.137.20 --orig_master_ip=192.168.137.20 --orig_master_port=3306 --command=stopssh --ssh_user=root
4.找到含有最新relay log的slave(同时找到最旧的binlog的slave的position), 分别判断是否是候选的slave→new master还原阶段
5.保存dead master(137.20)和最新slave(137.30)相差的relay log保存在dead master的/tmp目录下(根据配置文件配置的remote_workdir),然后确定这部分差异binlog(saved_master_binlog_)是否有效,也就是dead master和最新的slave之间是否存在binlog差异,存在差异则将生成的这个差异binlog拷贝到mha的workdir(137.40)下→new master还原阶段
Fri Aug 26 11:57:46 2016 - [info] Executing command on the dead master 192.168.137.20(192.168.137.20:3306): save_binary_logs --command=save --start_file=mysql-bin.000074 --start_pos=22461852 --binlog_dir=/mysql/log --output_file=/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 Creating /tmp if not exists.. ok. Concat binary/relay logs from mysql-bin.000074 pos 22461852 to mysql-bin.000074 EOF into /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog .. Dumping binlog format description event, from position 0 to 120.. ok. Dumping effective binlog data from /mysql/log/mysql-bin.000074 position 22461852 to tail(22497564).. ok. Concat succeeded. Fri Aug 26 11:57:49 2016 - [info] scp from root@192.168.137.20:/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog to local:/usr/local/mha/ha1/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog succeeded.
7.确定新的master,并检查最新slave(30)的relay log是否可以用来还原其他的slave→new master还原阶段
8.生成最新slave(137.30)和new master(137.10)之间的差异relay log(在最新relay log的slave的/tmp下生成和其它slave差异的binlog,是二者的“Read_Master_Log_Pos”的差,取名为“relay_from_read_to_latest_后面紧接的是目标slave的ip”),然后cp到目标(new master)的slave的/tmp下,同时将mha workdir下刚才保存的"saved_master_binlog_"(如果存在)文件拷贝到new master的/tmp下→new master还原阶段
Fri Aug 26 11:57:56 2016 - [info] Connecting to the latest slave host 192.168.137.30, generating diff relay log files..
Fri Aug 26 11:57:56 2016 - [info] Executing command: apply_diff_relay_logs --command=generate_and_send --scp_user=root --scp_host=192.168.137.10 --latest_mlf=mysql-bin.000074 --latest_rmlp=22461852 --target_mlf=mysql-bin.000074 --target_rmlp=9857376 --server_id=30 --diff_file_readtolatest=/tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog --workdir=/tmp --timestamp=20160826115742 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 --relay_log_info=/mysql/data/relay-log.info --relay_dir=/mysql/data/
Fri Aug 26 11:58:02 2016 - [info]
Opening /mysql/data/relay-log.info ... ok.
Relay log found at /mysql/data, up to mysql-relay-bin.000003
Fast relay log position search succeeded.
Target relay log file/position found. start_file:mysql-relay-bin.000003, start_pos:9857539.
Concat binary/relay logs from mysql-relay-bin.000003 pos 9857539 to mysql-relay-bin.000003 EOF into /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog ..
Dumping binlog format description event, from position 0 to 283.. ok.
Dumping effective binlog data from /mysql/data/mysql-relay-bin.000003 position 9857539 to tail(22462015).. ok.
Concat succeeded.
Generating diff relay log succeeded. Saved at /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog .
scp slave:/tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog to root@192.168.137.10(22) succeeded.
9.new master应用差异的relay log(首先会判断该salve原本Read_Master_Log_Pos”和“Exec_Master_Log_Pos是否相等,由于不是半同步复制所以slave虽然读到了该pos但是但是由于复制是异步的所有还得等待master定时发送binlog到slave,如果这中间master故障了就会导致二者的不一致),如果不相等会在该slave执行save_binary_logs命令保存之间差异的relay log取名为“relay_from_exec_to_read_后面紧接的是自身的ip”;然后应用"relay_from_read_to_latest_、saved_master_binlog_、relay_from_exec_to_read_"这三个差异的relay log,同时将这三个文件的内容合并生成一个新的binlog文件“total_binlog_for_”→new master还原阶段
Fri Aug 26 12:00:06 2016 - [info] This slave(192.168.137.10)'s Exec_Master_Log_Pos equals to Read_Master_Log_Pos(mysql-bin.000074:9857376). No need to recover from Exec_Master_Log_Pos. Fri Aug 26 12:00:06 2016 - [info] Connecting to the target slave host 192.168.137.10, running recover script.. Fri Aug 26 12:00:06 2016 - [info] Executing command: apply_diff_relay_logs --command=apply --slave_user='root' --slave_host=192.168.137.10 --slave_ip=192.168.137.10 --slave_port=3306 --apply_files=/tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog,/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog --workdir=/tmp --target_version=5.6.15-log --timestamp=20160826115742 --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55 --slave_pass=xxx Fri Aug 26 12:04:22 2016 - [info] Concat all apply files to /tmp/total_binlog_for_192.168.137.10_3306.20160826115742.binlog .. Copying the first binlog file /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog to /tmp/total_binlog_for_192.168.137.10_3306.20160826115742.binlog.. ok. Dumping binlog head events (rotate events), skipping format description events from /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog.. dumped up to pos 120. ok. /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog has effective binlog events from pos 120. Dumping effective binlog data from /tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog position 120 to tail(35832).. ok. Concat succeeded. All apply target binary logs are concatinated at /tmp/total_binlog_for_192.168.137.10_3306.20160826115742.binlog . MySQL client version is 5.6.15. Using --binary-mode. Applying differential binary/relay log files /tmp/relay_from_read_to_latest_192.168.137.10_3306_20160826115742.binlog,/tmp/saved_master_binlog_from_192.168.137.20_3306_20160826115742.binlog on 192.168.137.10:3306. This may take long time... Applying log files succeeded. Fri Aug 26 12:04:22 2016 - [info] All relay logs were successfully applied.
10.生成其它slave到新master的change语句,执行master_ip_failover完成切换生成VIP→new master还原阶段
11. 其它的slave也重复new masters slave的步骤 (从第8-9步,例如这里就会从mha的workdir拷贝saved_master_binlog_到最新的slave(137.30)上应用差异的relay log) →other slave还原阶段
12. other slave change new master→other slave还原阶段
13.生成failover report
注意:这里的relay log指的是slave已经读取到的master的binglog的位置(也就是slave中的relay log文件中已经保存了最新master binlog的位置)在show slave status \G中也就是“Read_Master_Log_Pos”并不是“Exec_Master_Log_Pos”,所以最新relay log的salve并不一定就是数据最新的(但是这种情况比较少),只能说明它保存的master binlog是最新的。
mha最先修复new master(不管它是否是最新的slave,所以如果候选的slave是最新的slave那么自然是最好的候选的slave就会很快修复好),然后再去修复其它的slave。
2.不在线手动Failover
注意:前提条件是mha没有启动,且存在dead的master,MHA manager检测到没有dead的server,将报错,并结束failover。
手动failover,这种场景意味着在业务上没有启用MHA自动切换功能,当主服务器故障时,人工手动调用MHA来进行故障切换操作,具体命令如下:
语句如下:
masterha_master_switch --master_state=dead --conf=/usr/local/mha/ha1/ha1.cnf --dead_master_host=192.168.137.10 --dead_master_port=3306 --new_master_host=192.168.137.20 --new_master_port=3306 --ignore_fail_on_start --ignore_last_failover
切换的过程中会存在几次需要输入“yes”进行下一步
View Code3.在线手动Failover
在许多情况下, 需要将现有的主服务器迁移到另外一台服务器上。 比如主服务器硬件故障,RAID 控制卡需要重建,将主服务器移到性能更好的服务器上等等。维护主服务器引起性能下降, 导致停机时间至少无法写入数据。 另外, 阻塞或杀掉当前运行的会话会导致主主之间数据不一致的问题发生。 MHA 提供快速切换和优雅的阻塞写入,这个切换过程只需要 0.5-2s 的时间,这段时间内数据是无法写入的。在很多情况下,0.5-2s 的阻塞写入是可以接受的。因此切换主服务器不需要计划分配维护时间窗口。
MHA在线切换的大概过程:
1.检测复制设置和确定当前主服务器
2.确定新的主服务器
3.阻塞写入到当前主服务器
4.等待所有从服务器赶上复制
5.授予写入到新的主服务器
6.重新设置从服务器
注意,在线切换的时候应用架构需要考虑以下两个问题:
1.自动识别master和slave的问题(master的机器可能会切换),如果采用了vip的方式,基本可以解决这个问题。
2.负载均衡的问题(可以定义大概的读写比例,每台机器可承担的负载比例,当有机器离开集群时,需要考虑这个问题)
为了保证数据完全一致性,在最快的时间内完成切换,MHA的在线切换必须满足以下条件才会切换成功,否则会切换失败。
1.所有slave的IO线程都在运行
2.所有slave的SQL线程都在运行
3.所有的show slave status的输出中Seconds_Behind_Master参数小于或者等于running_updates_limit秒,如果在切换过程中不指定running_updates_limit,那么默认情况下running_updates_limit为1秒。
4.在old master端,通过show processlist输出,没有一个更新花费的时间大于running_updates_limit秒。
1.首先,停掉MHA监控:
masterha_stop --conf=/usr/local/mha/ha1/ha1.cnf
2.手动在线failover
新的master为192.168.137.10
masterha_master_switch --conf=/usr/local/mha/ha1/ha1.cnf --master_state=alive --new_master_host=192.168.137.10 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
--orig_master_is_new_slave 切换时加上此参数是将原 master 变为 slave 节点,如果不加此参数,原来的 master 将不启动
--running_updates_limit=10000,故障切换时,候选master 如果有延迟的话, mha 切换不能成功,加上此参数表示延迟在此时间范围内都可切换(单位为s),但是切换的时间长短是由recover 时relay 日志的大小决定
注意:手动在线用的failover脚本是“master_ip_online_change”
3.切换日志
View Code
切换失败:
[error][/usr/local/share/perl5/MHA/MasterRotate.pm, ln262] We should not start online master switch when one of connections are running long queries on the new master(192.168.137.10(192.168.137.10:3306)). Currently 1 thread(s) are running.
Details:
{'Time' => '1173','Command' => 'Daemon','db' => undef,'Id' => '3','Info' => undef,'User' => 'event_scheduler','State' => 'Waiting on empty queue','Host' => 'localhost'}
从错误信息已经说的非常的清除,在new master中存在一个long queries,且该线程的id=3是一个事件调度线程,由于new master我开启了“scheduler”导致了在线手动切换失败,我把“scheduler”关闭就成功了。
在MHA的环境中备选的Master不能开启“scheduler”
参考:
http://www.cnblogs.com/gomysql/p/3675429.html
http://blog.csdn.net/lichangzai/article/details/50470771
mha下载地址:
https://mysql-master-ha.googlecode.com/files/mha4mysql-manager-0.55.tar.gz
https://mysql-master-ha.googlecode.com/files/mha4mysql-node-0.54.tar.gz
之前写的复制相关文章:
主从复制:http://www.cnblogs.com/chenmh/p/5089919.html
主主复制:http://www.cnblogs.com/chenmh/p/5153184.html
MMM方案:http://www.cnblogs.com/chenmh/p/5563778.html
半同步复制与MMM:http://www.cnblogs.com/chenmh/p/5744227.html
总结
主和备主之间需要半同步复制才能保证mha的最大程度的数据不丢失,否则使用MHA也就没优势了;还有就主和备主不要开启scheduler(作业),否则手动在线failover会失败。mha最先修复new master(不管它是否是最新的slave,所以如果候选的slave是最新的slave那么自然是最好的候选的slave就会很快修复好),然后再去修复其它的slave。
注意:文章中对一些配置做了备注说明,在实际部署中需要将这些备注删掉

