为什么Zookeeper集群节点是奇数
脑裂
在探索为什么zookeeper集群节点是奇数个的原因之前,需要先了解一下脑裂的概念。
当两台高可用服务器在指定的时间内,无法互相检测到对方心跳而各自启动故障转移功能,取得了资源以及服务的所有权,而此时的两台高可用服务器都还活着并作正常运行,这样就会导致同一个服务在两端同时启动而发生冲突的严重问题,最严重的就是两台主机同时占用一个IP地址(类似双端导入概念),当用户写入数据的时候可能会分别写入到两端,这样可能会导致服务器两端的数据不一致或造成数据的丢失,这种情况就称为裂脑,也有的人称之为分区集群或者大脑垂直分隔。
通俗来讲就是一个黑帮中出现了两个老大,所谓一山不容二虎,就造成了领导混乱。
我们用zookeeper集群来讲一下脑裂是如何产生的。首先,我们有一个集群,集群里只有一个leader。
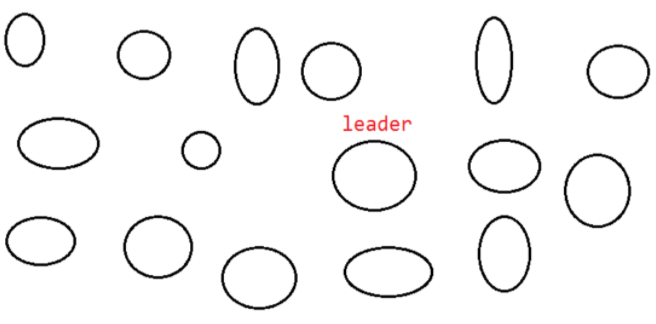
但是此时由于网络波动,使得一部分服务器脱离了集群,形成了一个小的集群,此时群龙无首,他们就会选举出一个新的leader。
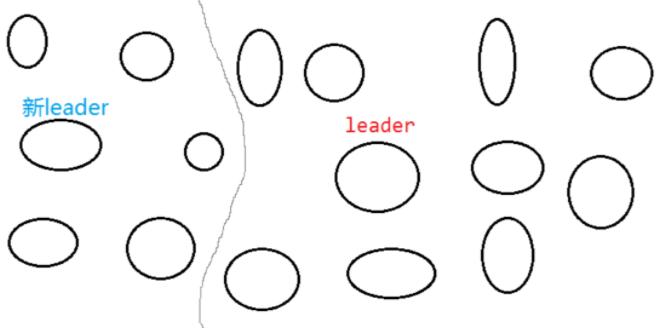
Zookeeper集群节点数量为什么要是奇数
首先需要明确zookeeper选举的规则:leader选举,要求过半原则,即可用节点数量 > 总节点数量/2 。注意是 > , 不是 ≥。
为什么要求过半原则
在集群出现脑裂的时候,可能会出现多个子集群同时服务的情况(即子集群各组选举出自己的leader),这样对整个zookeeper集群来说是紊乱的。
此时,如果遵循过半原则,即使出现脑裂情况,集群中也只会有一个子集群能够满足过半原则,只有满足过半原则的子集群才可以提供服务,这就能避免上述集群出现紊乱的情况。
采用奇数个主要出于两方面考虑:
- 防止由脑裂造成的集群不可用
- 假如zookeeper集群有5个节点,发生了脑裂,脑裂成了A、B两个小集群:
(a) A : 1个节点 ,B :4个节点 , 或 A、B互换
(b) A : 2个节点, B :3个节点 , 或 A、B互换
可以看出,上面这两种情况下,A、B中总会有一个小集群满足 可用节点数量 > 总节点数量/2 。所以zookeeper集群仍然能够选举出leader,仍然能对外提供服务,只不过是有一部分节点失效了而已。
- 假如zookeeper集群有4个节点,同样发生脑裂,脑裂成了A、B两个小集群:
(a) A : 1个节点 ,B :3个节点 , 或 A、B互换
(b) A : 2个节点, B :2个节点 , 或 A、B互换
可以看出,情况(a) 是满足选举条件的,与(1)中的例子相同。 但是情况(b) 就不同了,因为A和B都是2个节点,都不满足 可用节点数量 > 总节点数量/2 的选举条件, 所以此时zookeeper就彻底不能提供服务了。
综合上面两个例子可以看出: 在节点数量是奇数个的情况下, zookeeper集群总能对外提供服务(即使损失了一部分节点);如果节点数量是偶数个,会存在zookeeper集群不能用的可能性(脑裂成两个均等的子集群的时候)。
- 在容错能力相同的情况下,奇数台更节省资源
leader选举,要求 可用节点数量 > 总节点数量/2 。注意 是 > , 不是 ≥。
- 假如zookeeper集群1 ,有3个节点,3/2=1.5 , 即zookeeper想要正常对外提供服务(即leader选举成功),至少需要2个节点是正常的。换句话说,3个节点的zookeeper集群,允许有一个节点宕机。
- 假如zookeeper集群2,有4个节点,4/2=2 , 即zookeeper想要正常对外提供服务(即leader选举成功),至少需要3个节点是正常的。换句话说,4个节点的zookeeper集群,也允许有一个节点宕机。
那么问题就来了,集群1与集群2都允许1个节点宕机的容错能力,但是集群2比集群1多了1个节点。在相同容错能力的情况下,本着节约资源的原则,zookeeper集群的节点数维持奇数个更好一些。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号