
hadoop中联结不同来源数据
有时可能需要对来自不同源的数据进行综合分析:
如下例子:
有Customers文件,每个记录3个域:Custom ID, Name, Phone Number
Customers Orders
1,Stephanie Leung,555-555-5555 3,A,12.95,02-Jun-2008
2,Edward Kim,123-456-7890 1,B,88.25,20-May-2008
3,Jose Madriz,281-330-8004 2,C,32.00,30-Nov-2007
4,David Stork,408-555-0000 3,D,25.02,22-Jan-2009
1.Reduce侧的联结
Hadoop中名为datajoin得contrib软件包,用作数据联结的通用框架。处理多被放在reducer侧,故称为Reduce侧的联结。
术语:数据源——即表,Customers,和 Orders
标签(tag)——标记数据源
组键(group key)——即两个表得链接键,本例子中为custom ID
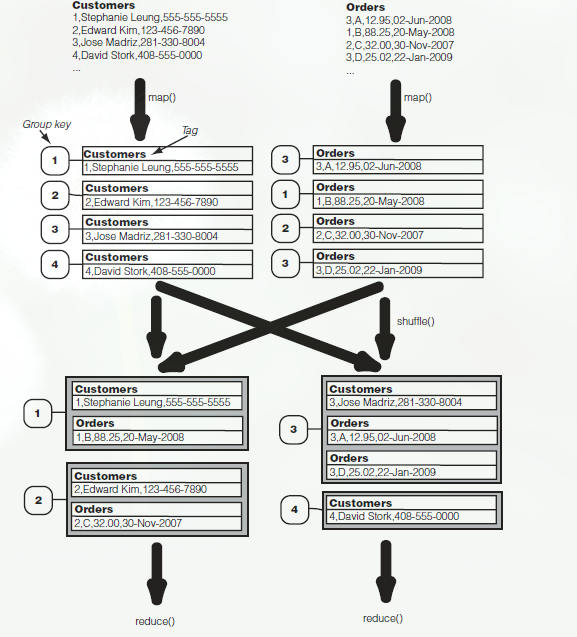
分析该流程图可以看到,每个map处理不同的源,并且map()阶段的工作就是对每条记录进行打包——即设置其tag,Group key 和内容;
对于数据的联结,map()输出一个记录包,采用组键作为联结键。值为原始记录,并且值由文件名tag标记;
map()封装了输入后,就进行MapReduce标准的分区、洗牌和排序操作。最终相同联结键的记录会被送到同一个reducer上;
reducer接受上面的输入数据后,进行完全交叉乘积,reduce生成所有值的合并结果。规定一个合并中每个值最多标记一次(即只有一个标签)。如组健1,2,4所示,组健3如下:
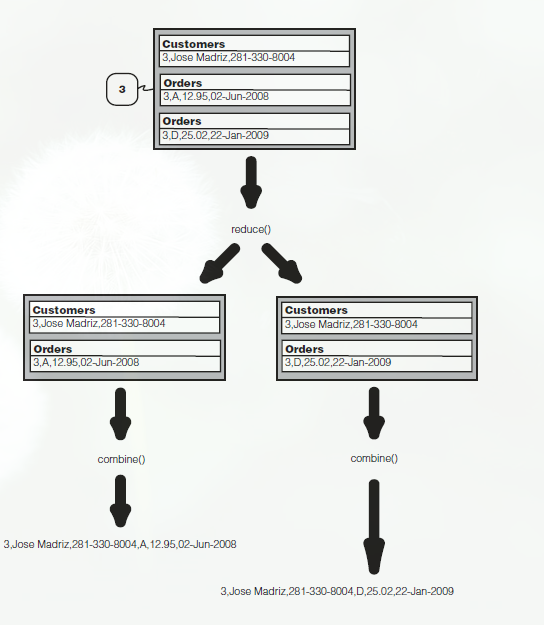
交叉乘积结果送入combine()中(这里的combine()与前面的Combiner不同),combine决定了操作时内联结、外联结、还是其他方式的联结。
内联结丢弃未含全部tag的结果(如4)。然后合并剩余记录。
整个过程结束,这就是 重分区排序-合并联结。
- 使用DATAJOIN软件包联结
Hadoop的datajoin软件包提供了3个供继承的抽象类:DataJoinMapperBase,DataJoinReducerBase和TaggedMapOut类
所以MapperClass实现DataJoinMapperBase类;Reducer实现DataJoinReducerBase类。map()和reduce()方法已经由datajoin软件包提供了,我们的子类只需实现几种配置详细信息的方法
datajoin指定键为Text型,而值为新的抽象数据类型TaggedMapOutput。
TaggedMapOutput是一种用Text标签封装记录的数据类型。实现了getTag()和setTag(Text tag)方法。
我们要自己实现抽象方法getData(),有时还需实现setData()方法,将记录传入,也可以从构造函数中传入。
另外,作为值,TaggedMapOutput须为Writable型,所以要实现readFields() write()方法。
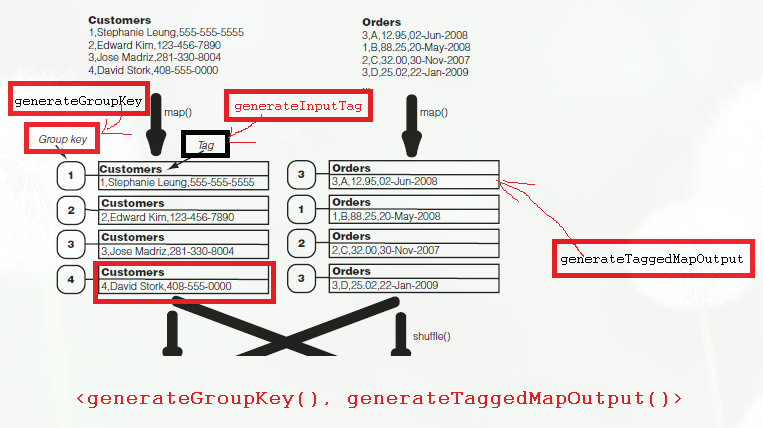
对于data join的mapper需要继承自DataJoinMapperBase,并且该mapper需要实现三个方法:
以下为《hadoop in action》示例,注意在eclipse下使用datajoin须添加hadoop-datajoin-0.20.203.0.jar包到工程的Library中
jar包位于/hadoop/contrib/datajoin/下,添加到 工程/propertites/java build path/Library/add extra jar.
另外新的API已经不再使用mapper,reducer接口,而Datajoin中DataJoinMapperBase,DataJoinReducerBase都是实现前两个的接口,所以job.setMapperClass会出错。只能使用旧的jobconf.
public class DataJoin extends Configured implements Tool{
//TaggedMapOutput是一个抽象数据类型,封装了标签与记录内容
//此处作为DataJoinMapperBase的输出值类型,需要实现Writable接口,所以要实现两个序列化方法
public static class TaggedWritable extends TaggedMapOutput
{
private Writable data;
public TaggedWritable(Writable data) //构造函数
{
this.tag = new Text(); //tag可以通过setTag()方法进行设置
this.data = data;
}
@Override
public void readFields(DataInput in) throws IOException {
tag.readFields(in);
data.readFields(in);
}
@Override
public void write(DataOutput out) throws IOException {
tag.write(out);
data.write(out);
}
@Override
public Writable getData() {
return data;
}
}
//mapper的主要功能是封装一个记录,实现如下三个方法达到次目的
public static class JoinMapper extends DataJoinMapperBase
{
//这个在任务开始时调用,用于产生标签
//此处就直接以文件名作为标签
@Override
protected Text generateInputTag(String inputFile) {
return new Text(inputFile);
}
//这里我们已经确定分割符为',',更普遍的,用户应能自己指定分割符和组键。
@Override
protected Text generateGroupKey(TaggedMapOutput record) {
String line = ((Text)record.getData()).toString();
String[] tokens = line.split(",");
return new Text(tokens[0]);
}
@Override
protected TaggedMapOutput generateTaggedMapOutput(Object value) {
TaggedWritable retv = new TaggedWritable((Text) value);
retv.setTag(this.inputTag); //不要忘记设定当前键值的标签
return retv;
}
}
//DataJoinReducerBase是DataJoin软件包的核心,它执行了一个完整的外部联结。
//我们的子类只是实现combine方法用来筛选掉不需要的组合,获得所需的联结操作(内联结,左联结等)。并且
//将结果化为合适输出格式(如:字段排列,去重等)
public static class JoinReducer extends DataJoinReducerBase
{
//两个参数数组大小一定相同,并且最多等于数据源个数
@Override
protected TaggedMapOutput combine(Object[] tags, Object[] values) {
if(tags.length < 2) return null; //这一步,实现内联结
String joinedStr = "";
for(int i = 0; i < values.length; i++)
{
if(i > 0) joinedStr += ","; //以逗号作为原两个数据源记录链接的分割符
TaggedWritable tw = (TaggedWritable)values[i];
String line = ((Text)tw.getData()).toString();
String[] tokens = line.split(",", 2); //将一条记录划分两组,去掉第一组的组键名。
joinedStr += tokens[1];
}
TaggedWritable retv = new TaggedWritable(new Text(joinedStr));
retv.setTag((Text)tags[0]); //这只retv的组键,作为最终输出键。
return retv;
}
2.基于DistributedCathe的复制连结
reduce侧连结效率较低,因为map阶段重排了以后可能会丢弃的数据。如果能在map阶段执行连结速度会有较高效率,但是map阶段键不统一,不知道当前记录该与哪个记录连结。
对于特定的数据模式:一个数据源较小,另一个很大的情况,可以将小的复制到所有mapper上,实现map阶段连结。(这种数据成为“背景”数据,由hadoop分布式缓存分发)。
管理分布式缓存的类为:DistributedCathe;采取如下两个步骤使用该类:
使用静态方法DistributedCache.addCatheFile()设定传播到所有节点的文件;
使用静态方法DistributedCache.getLocalCatheFiles()获取本地副本路径;
在使用DistributedCache还会出现一种情况:背景数据在本地系统中,这时
一种方法是添加代码,在addCacheFile()前将本地文件上传到HDFS中;
另一种方法是使用GenericOptionsParser,直接通过这种命令行参数来支持,选项为-files,后面文件以','分隔
hadoop jar DataJoin.jar -files fileA.txt,fileB.txt input.txt output
此时无须自己调用addCacheFile(),在改变一下程序中参数索引即可。
3.半连接:map侧过滤reduce侧连结
要寻找特定键(如ID为415的记录)的所有记录时,可以现在customs中找出所有ID为415的顾客,组成custom415临时文件,然后连结custom415与orders即可;
如果custom415还是太大,可以先把提取出目标键(此例中为415)记录在customID415临时文件中,map阶段会丢弃所有键不再customID415中的记录,最后于orders连结;
如果还是太大,就需要使用Bloom filter数据结构。

