SVM--支持向量机
# SVM--支持向量机
SVM简介
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
最大间隔和分类
在做二分类时,我们希望找到一个超平面,将两者分开。这样的平面也许有很多,但怎么样找到那个最优的,就是我们需要考虑的问题了。一般的,我们可以认为一个点距离超平面的远近可以表示分类预测的置信度。所以,最优解应是”正中间”, 容忍性好, 鲁棒性高, 泛化能力最强.
而这个超平面方程,我们一般表示为
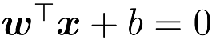
超平面距离两支撑向量之和为,也就是间隔
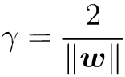
所以问题求解变成了找到w满足使得间隔最大
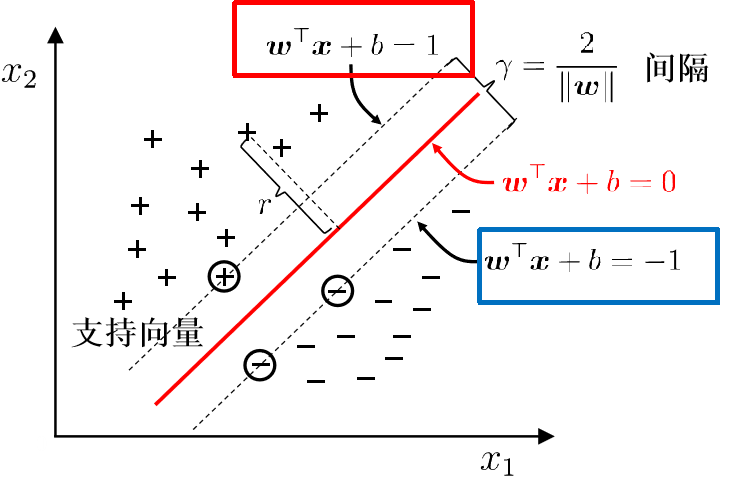
由于后续计算方便,求解最大值,也就等价于求解最小值.当训练样本较少时,可以直接通过线性规划求解。但是一旦数据量增多,这种方法就不再适用。
对偶问题
此时,问题已经变成了求解满足如下条件的w和b
其本质是一个凸二次规划问题。
这时候就可以构造拉格朗日函数
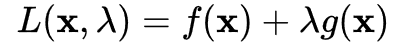
其约束范围为不等式,可以转化成KKT条件
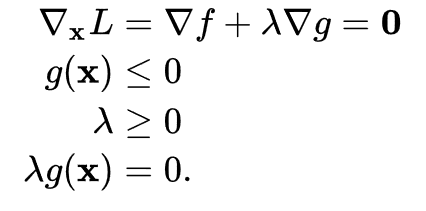
求解上诉问题,可以通过多种方式,如SMO,二次规划
拉格朗日乘子法
1.第一步:引入拉格朗日乘子 α_i≥0得到拉格朗日函数
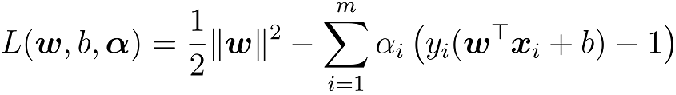
第二步:令L(w,b,α) 对w和b的偏导为零:
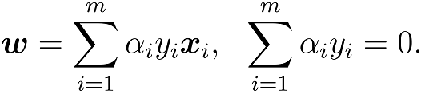
第三步:w, b回代到第一步:
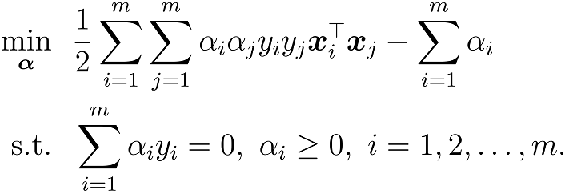
最终形式
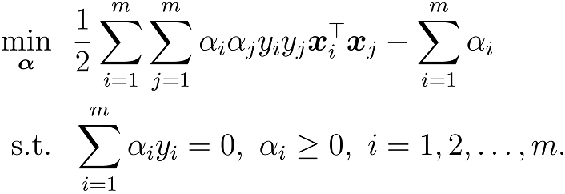
根据KKT条件得
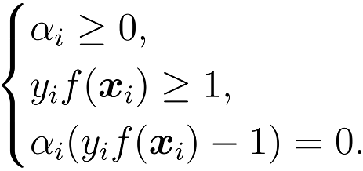
到这里我们可以看到,只有在边缘的支撑向量 αi才不会为0,而在内部的都为0。大部分的训练样本都不需保留, 最终模型仅与支持向量有关.
SMO求解
SMO算法是一种启发式算法,基本思路是:如果所有变量的解都满足此最优化问题的KKT条件,那么这么最优化问题的解就得到了。
求解步骤:
1.任意选取一对需要更行的变量αi和αj
2.将剩下的α当作定值,求解当前对偶问题,更新αi和αj
不断迭代更行,得到最优解。再将α反代,
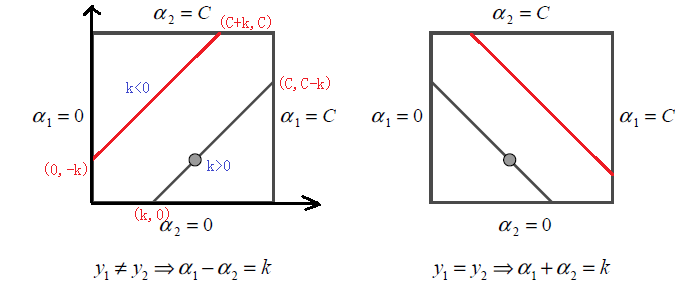
此时,我们可以将问题看成一个一元二次的优化问题。由于α1y1+α2y2==c,两个变量之间相互联系,所以可以假设成最后是α2的优化问题,最终求出α2再反代回去解出α1。
由于必须满足上图中的线段约束。假设L和H分别是上图中所在的线段的边界。那么很显然我们有:
而对于L和H,我们也有限制条件如果是上面左图中的情况,则
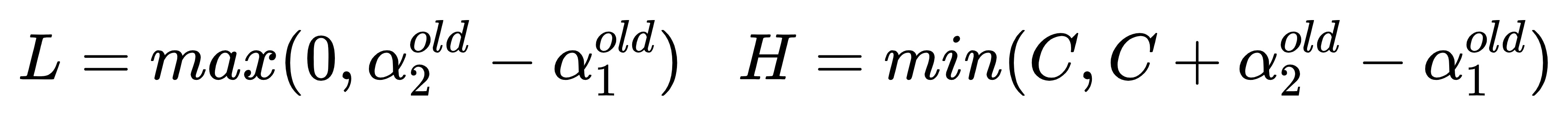
则最终的αnew2α2new应该为:
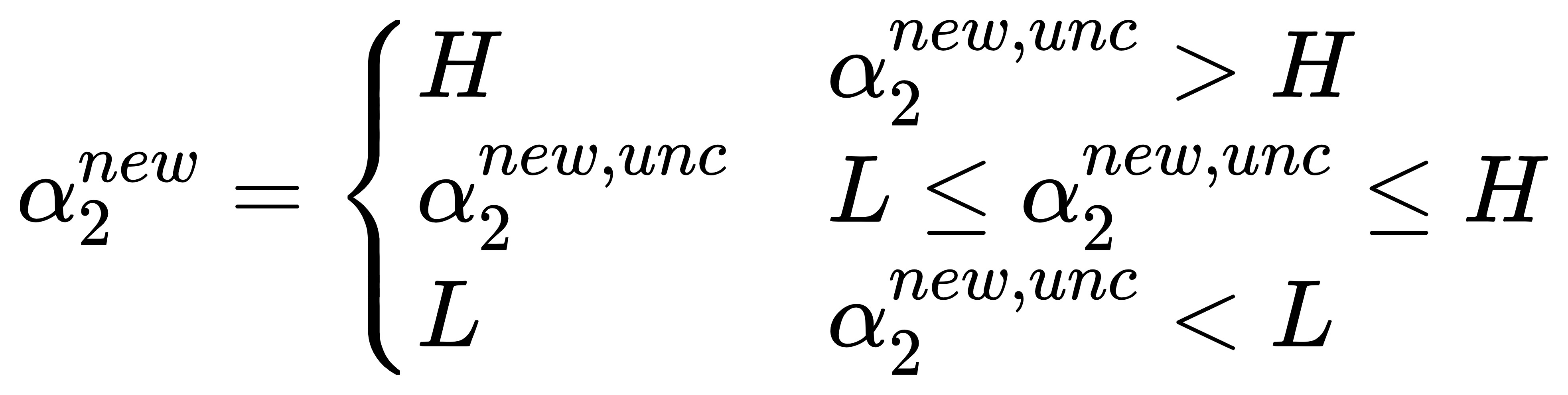
最后:
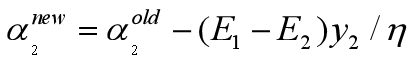
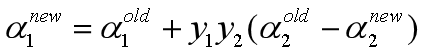
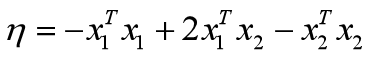
核函数
以上都是基于模型是线性可分的,那么,如果遇到线性不可分该怎么办呢?这时候核函数就应运而生。
原理:对于在低维线性不可分的数据,在映射到了高维以后,就变成线性可分的了。
核函数的关键在于设计核函数
Kernel(x,y)=<φ(x),φ(y)>=k(x,y)
常用的核函数有:

软间隔与正则化
软间隔
在现实生活中的数据往往是或本身就是非线性可分但是近似线性可分的,或是线性可分但是具有噪声的,以上两种情况都会导致在现实应用中,硬间隔线性支持向量机变得不再实用,所以软间隔,应运而生
软间隔,通俗来讲就是,使超平面既要尽可能的将数据类别分对,又要使得支持向量到超平面的间隔尽可能的大
ϵ称为松弛变量
正则化
最大化间隔的同时, 让不满足约束的样本应尽可能少.
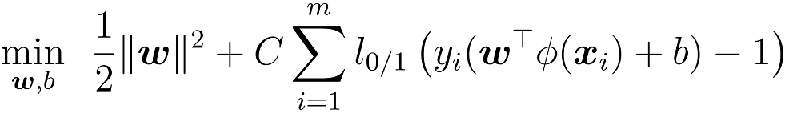
其中C>0为惩罚参数;l_0/1是”0/1损失函数”
数据集简介
乳腺癌数据集一共有569个样本,30个特征,标签为二分类
| 类型 | 个数 |
|---|---|
| 良性 benign | 357 |
| 恶性 malignant | 212 |
代码实现
from sklearn.datasets import load_breast_cancer
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
from sklearn.model_selection import train_test_split
import time
def dataset_loder():
cancers=load_breast_cancer()
data=cancers.data
label=cancers.target
label=np.array(label)
index=np.where(label==0)
label[index]=-1
return data,label
def weight(data,label,alphas):
data_mat=np.mat(data)
label_mat=np.mat(label).transpose()
w_mat=np.mat(np.zeros((1,data_mat.shape[1])))
for i in range(data_mat.shape[0]):
if alphas[i]>0:
w_mat+=label_mat[i]*alphas[i]*data_mat[i,:]
return w_mat.tolist()
def randPickj(i,m):
#i是alphai的i值,整数; m是alpha个数; j不能等于i
j=i
while j==i:
j=int(np.random.uniform(0,m))
return j
def clipAlpha(aj,H,L):
if aj>H:
aj=H
if aj<L:
aj=L
return aj
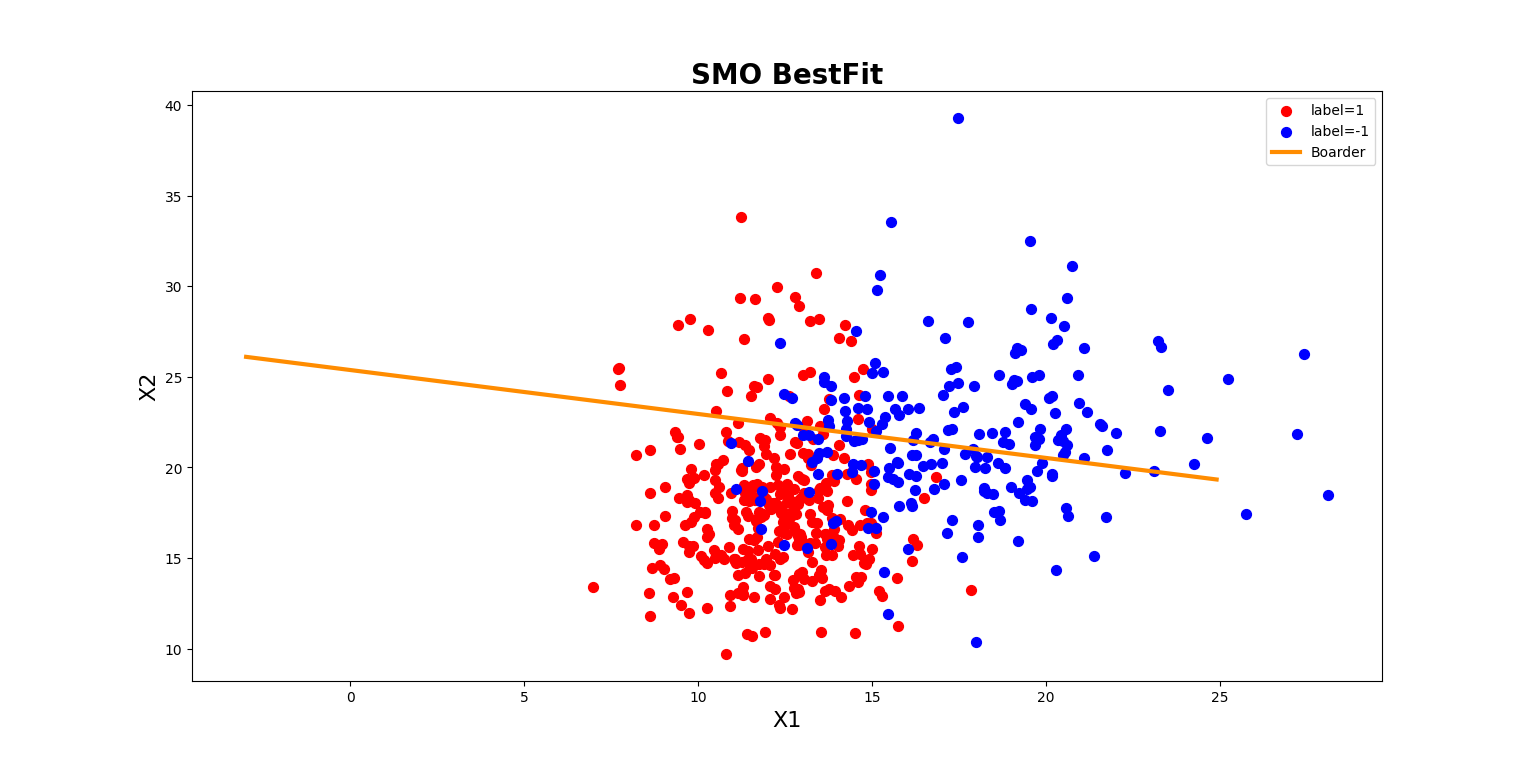
def plotBestFit(weights, b):
dataMat, labelMat = dataset_loder() # 加载样本特征、样本类别
dataArr = np.array(dataMat)
n = dataArr.shape[0] # n个样本
xcord1 = []
ycord1 = []
xcord2 = []
ycord2 = [] # 两个类别的样本的xy坐标值,x对应x1,y对应x2
# 将样本数据根据样本类别标签labelMat分别放入不同的坐标集中
for i in range(n):
if int(labelMat[i]) == 1: # 第i个样本是1类
xcord1.append(dataArr[i, 0]) # 第i个样本的x1值
ycord1.append(dataArr[i, 1]) # 第i个样本的x2值
else:
xcord2.append(dataArr[i, 0]) # 第i个样本的x1值
ycord2.append(dataArr[i, 1]) # 第i个样本的x2值
# 绘制两类样本的散点图
fig = plt.figure(figsize=(12, 8))
plt.scatter(xcord1, ycord1, c="red", s=50, label="label=1")
plt.scatter(xcord2, ycord2, c="blue", s=50, label="label=-1") # 继续在原图上作图
# 绘制决策边界
x = np.arange(-3.0, 25.0, 0.1)
y = (-b-weights[0][0] * x) / weights[0][1] # 由w1*x1+w2*x2+b=0得到x2(即y)=(-b-w1x1)/w2
x.shape = (len(x), 1)
y.shape = (len(x), 1)
plt.plot(x, y, color="darkorange", linewidth=3.0, label="Boarder") # 继续在ax图上作图
plt.xlabel("X1", fontsize=16)
plt.ylabel("X2", fontsize=16)
plt.title("SMO BestFit", fontsize=20, fontweight="bold")
plt.legend() # 添加图标注解
plt.show()
def smo(data,label,c,toler,max_iter):
''''
c:软间隔的正则化的惩罚因子
toler:偏离KKT的容错率
max_iter:外层循环迭代次数
'''
'''
multiply:由于multiply是ufunc函数,
ufunc函数会对这两个数组的对应元素进行计算,因此它要求这两个数组有相同的大小(shape相同),
相同则是计算内积。如果shape不同的话,会将小规格的矩阵延展成与另一矩阵一样大小,再求两者内积。
'''
b=0
data_mat = np.mat(data)
label_mat = np.mat(label).transpose()
m,n=data_mat.shape
alphas = np.zeros((m,1))
iters = 0
while iters < max_iter:
alphaPairsChanged = 0
for i in range(m):
# 计算第i个样本点的预测值gxi和预测误差Ei
#g(x)=ai yi x xiT+b
gxi=float(np.multiply(alphas,label_mat).transpose()*(data_mat*data_mat[i,:].transpose()))+b
Ei=gxi-label_mat[i]
"""检验第i个样本点是否满足KKT条件,若满足则会跳出本次内循环(不更新这个alphai),进行下一次内循环;
若不满足,看它是否是违反KKT条件超过容错率toler的点,若不是,则跳出本次内循环(不更新这个alphai),进行下一次内循环;
若是,则继续选择alphaj,计算gx,E,eta,进而求得aj解析解,进而求得ai解析解,进而更新b值"""
if (label_mat[i]*Ei<-toler and alphas[i]<c) or (label_mat[i]*Ei>toler and alphas[i]>0):
j=randPickj(i,m)
gxj=float(np.multiply(alphas,label_mat).transpose()*(data_mat*data_mat[j,:].transpose()))+b
Ej=gxj-label_mat[j]
# 存储alpha初始值,用于后续计算
alphaIold = alphas[i].copy()
alphaJold = alphas[j].copy()
if label_mat[i]!=label_mat[j]:
L=max(0,alphas[j]-alphas[i])
H=min(c,c+alphas[j]-alphas[i])
else:
L = max(0, alphas[j] + alphas[i]-c)
H = min(c, alphas[j] + alphas[i])
if L==H:
continue
eta=data_mat[i,:]*data_mat[i,:].transpose()+data_mat[j,:]*data_mat[j,:].transpose()\
-2.0*data_mat[i,:]*data_mat[j,:].transpose()
if eta==0:
continue
alphas[j] = alphas[j] + label_mat[j] * (Ei - Ej) / eta
alphas[j] = clipAlpha(alphas[j], H, L)
if alphas[j]-alphaJold<0.00001:
continue
alphas[i]=alphas[i]+label_mat[i]*label_mat[j]*(alphaJold-alphas[j])
# 更新b值,根据alpha是否在0~C决定更新的b值
b1 = -Ei - label_mat[i] * (alphas[i] - alphaIold) * data_mat[i, :] * data_mat[i, :].transpose() \
- label_mat[j] * (alphas[j] - alphaJold) * data_mat[j, :] * data_mat[i, :].transpose() + b
b2 = -Ej - label_mat[i] * (alphas[i] - alphaIold) * data_mat[i, :] * data_mat[j, :].transpose() \
- label_mat[j] * (alphas[j] - alphaJold) * data_mat[j, :] * data_mat[j, :].transpose() + b
# 若ai或aj在(0,C)之间,则取b=bi或b=bj,若ai aj都不在(0,C)之间,取均值
if alphas[i] > 0 and alphas[i] < c:
b = b1
elif alphas[j] > 0 and alphas[j] < c:
b = b2
else:
b = (b1 + b2) / 2.0
alphaPairsChanged += 1 # 若进行到这里,说明ai aj经过了层层筛选(continue),已经被更新,于是内循环中alpha对更新次数+1
print("iter:{0}; i:{1}; alpha pair changed:{2};b:{3}".format(iters, i, alphaPairsChanged,b))
if alphaPairsChanged==0:
iters+=1
else:
iters=0
print ("iteration numer:%d" %iters)
return b,alphas
if __name__=="__main__":
c=0.1#惩罚因子
toler=0.001 #容错率
num_epoch=5
data,label=dataset_loder()
b,alphas=smo(data,label,c,toler,num_epoch)
print("b",b)
w=weight(data,label,alphas)
plotBestFit(w,b)
实验截图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号