canal-clientadapter 数据同步实验
背景
canal 1.1.1版本之后, 内置增加客户端数据同步功能, Client适配器整体介绍: ClientAdapter
RDB适配器
RDB adapter 用于适配mysql到任意关系型数据库(需支持jdbc)的数据同步及导入 测试支持的数据库列表:
- MYSQL
- ORACLE
- POSTGRESS
- SQLSERVER
- ELASTICSEARCH
- ...
clientadapter就是从mysql数据同步至上述类型数据库
安装和配置
$ wget https://github.com/alibaba/canal/releases/download/canal-1.1.4/canal.adapter-1.1.4.tar.gz
$ mkdir canal-adapter
$ tar xf canal.adapter-1.1.4.tar.gz -C canal-adapter
$ ls canal-adapter #目录和canal-deploy 一样
bin conf lib logs plugin
业务逻辑: src_mysql(192.168.20.40) <-> canal-deploy <-> client-adapter <-> dest_mysql(192.168.20.41)
canal-deploy安装配置参考之前文章
实验一:实现mysql -> mysql 指定库同步(db名相同)
同步src_mysql的text和text1库。有情提醒:dest_mysql上需要手动建库create database xxx;
$ cat conf/application.yml
canal.conf:
canalServerHost: 127.0.0.1:11111 # 对应单机模式下的canal server的ip:port
# zookeeperHosts: slave1:2181 # 对应集群模式下的zk地址, 如果配置了canalServerHost, 则以canalServerHost为准
# mqServers: slave1:6667 #or rocketmq # kafka或rocketMQ地址, 与canalServerHost不能并存
flatMessage: true # 扁平message开关, 是否以json字符串形式投递数据, 仅在kafka/rocketMQ模式下有效
batchSize: 50 # 每次获取数据的批大小, 单位为K
syncBatchSize: 1000 # 每次同步的批数量
retries: 0 # 重试次数, -1为无限重试
timeout: # 同步超时时间, 单位毫秒
mode: tcp # kafka rocketMQ # canal client的模式: tcp kafka rocketMQ
# srcDataSources: # 源数据库
# defaultDS: # 自定义名称
# url: jdbc:mysql://127.0.0.1:3306/mytest?useUnicode=true # jdbc url
# username: root # jdbc 账号
# password: 121212 # jdbc 密码
canalAdapters: # 适配器列表
- instance: example # canal 实例名或者 MQ topic 名
groups: # 分组列表,一组内配置被订阅串行执行
- groupId: g1 # 分组id, 如果是MQ模式将用到该值
outerAdapters: # 分组内适配器列表
- name: logger # 日志打印适配器
- name: rdb #指定为rdb类型同步
key: mysql1 # 指定adapter的唯一key, 与表映射配置中outerAdapterKey对应
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver #jdbc驱动名,部分jdbc的jar包需要自行放到lib目录下
jdbc.url: jdbc:mysql://192.168.20.41:3306/text?useUnicode=true #jdbc url text库
jdbc.username: root #jdbc username
jdbc.password: 123123 #jdbc password
- name: rdb
key: mysql2 #第二个库text1指定一个唯一key
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver
jdbc.url: jdbc:mysql://192.168.20.41:3306/text1?useUnicode=true #text2库
jdbc.username: root
jdbc.password: 123123
...
注意点:
- 其中 outAdapter 的配置: name统一为rdb, key为对应的数据源的唯一标识需和下面的表映射文件中的outerAdapterKey对应, properties为目标库jdb的相关参数
- adapter将会自动加载 conf/rdb 下的所有.yml结尾的表映射配置文件
rdb配置文件
$ cat conf/rdb/mytest_user.yml
#dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
#destination: example # cannal的instance或者MQ的topic
#groupId: # 对应MQ模式下的groupId, 只会同步对应groupId的数据
#outerAdapterKey: mysql1 # adapter key, 对应上面配置outAdapters中的key
#concurrent: true # 是否按主键hash并行同步, 并行同步的表必须保证主键不会更改及主键不能为其他同步表的外键!!
#dbMapping:
# database: text # 源数据源的database/shcema
# table: user # 源数据源表名
# targetTable: mytest.tb_user # 目标数据源的库名.表名
# targetPk: # 主键映射
# id: id # 如果是复合主键可以换行映射多个
## mapAll: true # 是否整表映射, 要求源表和目标表字段名一模一样 (如果targetColumns也配置了映射,则以targetColumns配置为准)
# targetColumns: # 字段映射, 格式: 目标表字段: 源表字段, 如果字段名一样源表字段名可不填
# id:
# name:
# role_id:
# c_time:
# test1:
# etlCondition: "where c_time>={}" #简单的过滤
# commitBatch: 3000 # 批量提交的大小
# Mirror schema synchronize config #schema
dataSourceKey: defaultDS
destination: example
groupId: g1
outerAdapterKey: mysql1
concurrent: true
dbMapping:
mirrorDb: true #镜像复制,DDL,DML
database: text #即两库的schema要一模一样
$ cp -a conf/rdb/mytest_user.yml conf/rdb/mysql2.yml
$ cat conf/rdb/mysql2.yml
dataSourceKey: defaultDS
destination: example
groupId: g1
outerAdapterKey: mysql2 #key 对应上
concurrent: true
dbMapping:
mirrorDb: true
database: text1 #text1库
启动canal-deploy
启动client-adapter
$ cd bin && ./startup.sh
# 192.168.20.40 新建表,添加数据
$ mysql -uroot -h192.168.20.40 -p
mysql > use text;
mysql > create table `labixiaoxin` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` char(30) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
mysql> insert into labixiaoxin(name) values ('小新');
查看canal-adapter日志
$ less logs/adapter/adapter.log
2020-07-29 20:00:37.650 [pool-14-thread-1] DEBUG c.a.o.c.c.adapter.rdb.service.RdbMirrorDbSyncService - DDL: {"data":null,"database":"text","destination":"example","es":1596024037000,"groupId":null,"isDdl":true,"old":null,"pkNames":null,"sql":"create table `labixiaoxin` (\n`id` int(10) unsigned NOT NULL AUTO_INCREMENT,\n`name` char(30) NOT NULL,\nPRIMARY KEY (`id`)\n) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8","table":"labixiaoxin","ts":1596024037650,"type":"CREATE"} #DDL 建表
2020-07-29 20:00:50.469 [pool-6-thread-1] DEBUG c.a.o.canal.client.adapter.rdb.service.RdbSyncService - DML: {"data":{"id":1,"name":"小新"},"database":"text","destination":"example","old":null,"table":"labixiaoxin","type":"INSERT"} #DML 插入数据
dest_mysql(192.168.20.41)查看数据是否同步
$ mysql -uroot -h192.168.20.41 -p
mysql > use text;
mysql > show tables;
+----------------------------+
| Tables_in_text |
+----------------------------+
| labixiaoxin |
+----------------------------+
mysql> select * from labixiaoxin;
+----+--------+
| id | name |
+----+--------+
| 1 | 小新 |
+----+--------+
数据已同步
实验二:实现mysql -> mysql 指定表同步(db name,table name可不相同)
$ cat conf/rdb/mytest_user.yml
...
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
- name: rdb
key: mysql1
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver
jdbc.url: jdbc:mysql://192.168.20.41:3306/?useUnicode=true #不指定数据库
jdbc.username: root
jdbc.password: 123123
$ cat conf/rdb/mytest_user.yml #实验一有参数解释,多个表即配多个yml文件
dataSourceKey: defaultDS
destination: example
groupId: g1
outerAdapterKey: mysql1
concurrent: true
dbMapping:
database: text
table: labixiaoxin
targetTable: xiaoxin.roles #库和表需要提前建好 源text.labixiaoxin -> 目标xiaoxin.roles
targetPk:
id: id
# mapAll: true
targetColumns:
id:
names: name
实验三:实现mysql -> mysql 指定数据变更后同步
无法实现,需要代码开发
实验四:实现mysql -> elasticsearch
这里简单测试单表映射索引示例:
mysql > create table `labixiaoxin` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` char(30) NOT NULL,
`age` int(3) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
mysql > insert into labixiaoxin(name,age) values ('小新',5);
配置添加elasticsearch中索引mapping
PUT /labixiaoxin #索引名
{
"mappings": {
"_doc": {
"properties": {
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"age": {
"type": "long"
}
}
}
}
}
启动canal-deploy
配置client-adapter
$ cat conf/application.yml
canal.conf:
...
srcDataSources:
defaultDS:
url: jdbc:mysql://192.168.20.40:3306/text?useUnicode=true #es一次只能指定一个库,默认同步多个库需要写多个srcDataSources
username: root
password: 123123
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: es
hosts: 192.168.20.4:9200,192.168.20.5:9200,192.168.20.6:9200 # 127.0.0.1:9200 for rest mode 集群地址, 逗号分隔
properties:
mode: rest #transport # or rest 可指定transport模式或者rest模式
# security.auth: test:123456 # only used for rest mode
cluster.name: myes #集群名称
$ cat conf/es/mytest_user.yml
dataSourceKey: defaultDS
destination: example
groupId: g1
esMapping:
_index: labixiaoxin #es 索引名
_type: _doc #es 的type名称, es7下无需配置此项
_id: _id #es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配
upsert: true
# pk: id #如果不需要_id, 则需要指定一个属性为主键属性
sql: "select a.id as _id,a.name,a.age from labixiaoxin a" #sql映射,这里 from labixiaoxin = from text.labixiaoxin
# objFields:
# _labels: array:;
# etlCondition: "where a.c_time>={}"
commitBatch: 3000
启动client-adapter
查看日志
$ less logs/adapter/adapter.log
...
2020-07-30 15:23:23.611 [pool-3-thread-1] DEBUG c.a.otter.canal.client.adapter.es.service.ESSyncService - DML: {"data":[{"id":1,"name":"小新","age":5}],"database":"text1","destination":"example","es":1596093803000,"groupId":null,"isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"labixiaoxin","ts":1596093803610,"type":"INSERT"}
查看elasticsearch 数据是插入索引
GET /labixiaoxin/_search
{
"query": {"match_all": {}}
}
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "labixiaoxin",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "小新",
"age" : 5
}
...
实验完成,更新配置信息,请参考官方文档
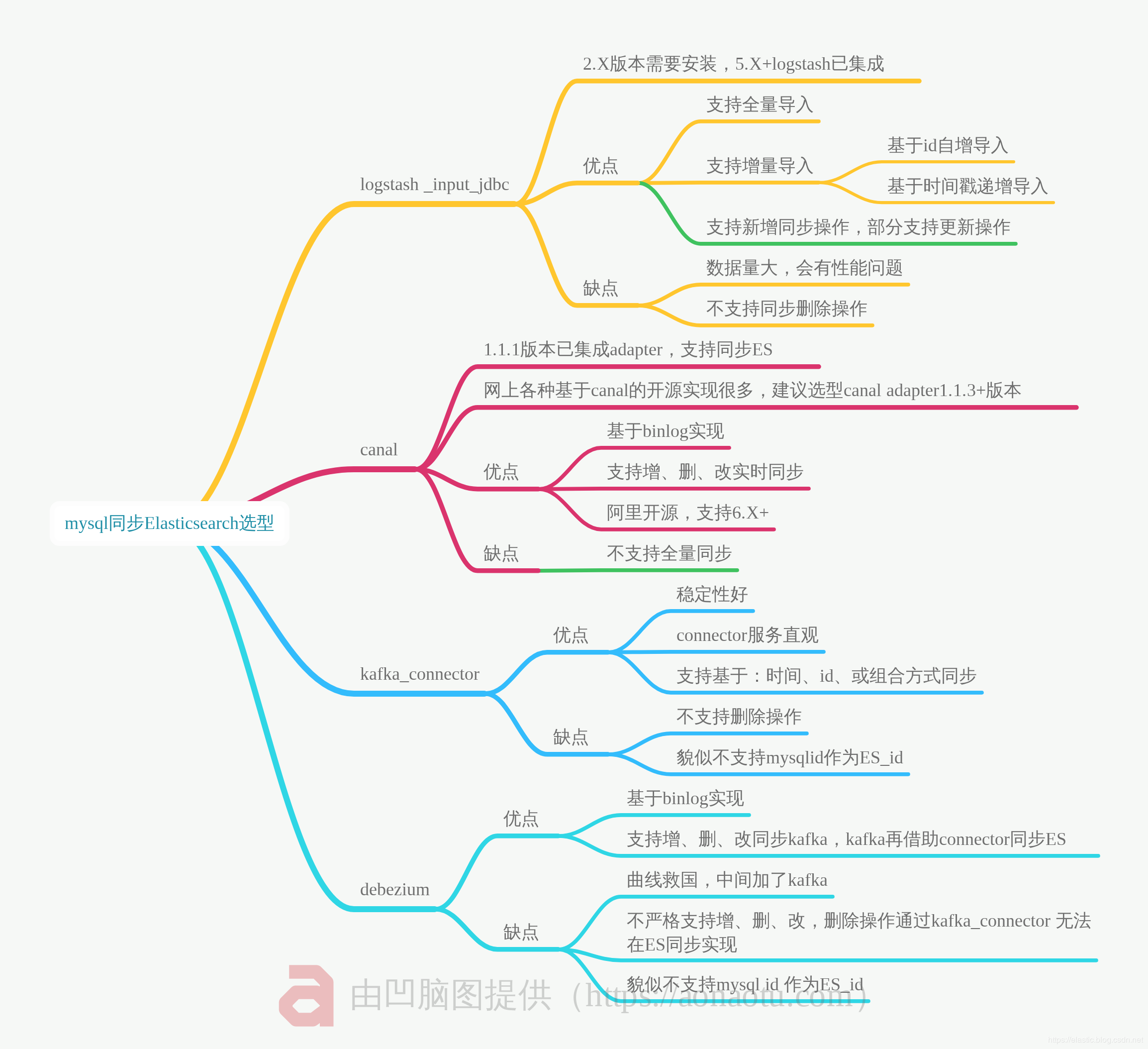
同步至es选型: 图片来源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号