mapReduce中的Shuffle
简单介绍:
Shuffle发生在map输出到reduce输入的过程,Shuffle翻译过来是“洗牌”,顾名思义该过程涉及数据的重新分配,主要分为map任务输出数组分区,排序,规约写入本地磁盘,reduce任务拉取文件排序。
Map端:
map端输出时,先将数据写入内存中的环形缓冲区,默认大小为100M,可以通过mapreduce.task.io.sort.mb修改。过程如下:
①当缓冲区的内容大小达到阈值(默认0.8,即缓冲区大小的80%,mapreduce.map.sort.spill.percent修改),便有一个后台线程会将写入缓冲区的内容溢写到磁盘。溢写的过程中map仍可以写入缓冲区,当缓冲区满map阻塞,等待溢写结束;
②后台线程写磁盘之前会计算输出的key的分区(一个分区对应一个reduce任务),同一个分区的key分在一组并按照key排序。最后写到本地磁盘。如果设置combiner函数,会在写磁盘前调用combiner函数(数据聚合减少网络传输与IO,使用combiner必须保证对结果没有影响);
③每一次溢写都会产生一个溢出文件,map输出结束后悔产生多个溢出文件。最终会被合并成一个分区有序的文件。mapreduce.task.io.sort.factor设置一次可以合并的文件个数,默认为10;
④输出到磁盘的过程可以设置压缩,默认不压缩。mapreduce.map.output.compress为true开启压缩;
Reduce端
reduce主要是复制与排序两个过程。reduce拉取map输出数据的过程是复制阶段。一个reduce任务需要从多个map端复制输出文件。复制是多线程并发执行。mapreduce.reduce.shuffle.parallelcopies 设置并发线程数,默认为5。过程如下
①map任务完成后通过心跳通知application master,reduce定期去查询application master,以获取完成的map任务位置,去复制数据;
②reduce复制数据到JVM内存,mapreduce.reduce.shuffle.input.buffer.percent设置可用内存比例;
③复制数据大小达到内存阈值(mapreduce.reduce.shuffle.merge.percent设置)或者文件数达到阈值(mapreduce.reduce.merge.inmem.threshold设置)则将内存的数据合并溢写到磁盘;
④复制结束后合并内存数据与溢写文件数据,将数据输入到reduce任务
Shuffle压缩:
节约磁盘空间,加速数据在网络和磁盘上的传输速度,hadoop checknative 查看支持的压缩方式
hadoop支持压缩算法如下:
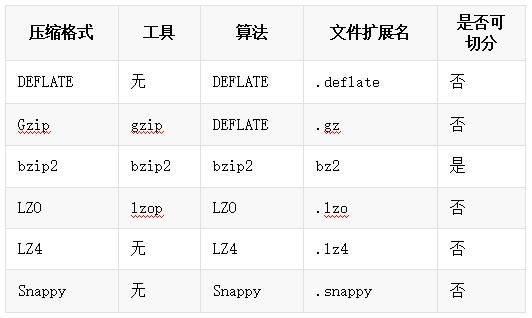
算法对应java类
|
压缩格式 |
对应使用的java类 |
|
DEFLATE |
org.apache.hadoop.io.compress.DeFaultCodec |
|
gzip |
org.apache.hadoop.io.compress.GZipCodec |
|
bzip2 |
org.apache.hadoop.io.compress.BZip2Codec |
|
LZO |
com.hadoop.compression.lzo.LzopCodec |
|
LZ4 |
org.apache.hadoop.io.compress.Lz4Codec |
|
Snappy |
org.apache.hadoop.io.compress.SnappyCodec |
压缩速率比较:

两种方式设置压缩:
代码设置:
//设置我们的map阶段的压缩 Configuration configuration = new Configuration(); configuration.set("mapreduce.map.output.compress","true"); configuration.set("mapreduce.map.output.compress.codec","org.apache.hadoop.io.compress.SnappyCodec"); //设置我们的reduce阶段的压缩 configuration.set("mapreduce.output.fileoutputformat.compress","true"); configuration.set("mapreduce.output.fileoutputformat.compress.type","RECORD"); configuration.set("mapreduce.output.fileoutputformat.compress.codec","org.apache.hadoop.io.compress.SnappyCodec");
修改mapred-site.xml设置:(修改配置文件需要重新启动集群)
<!--map输出数据进行压缩/> <property> <name>mapreduce.map.output.compress</name> <value>true</value> </property> <property> <name>mapreduce.map.output.compress.codec</name> <value>org.apache.hadoop.io.compress.SnappyCodec</value> </property> <!--reduce输出数据进行压缩> <property> <name>mapreduce.output.fileoutputformat.compress</name> <value>true</value> </property> <property> <name>mapreduce.output.fileoutputformat.compress.type</name> <value>RECORD</value> </property> <property> <name>mapreduce.output.fileoutputformat.compress.codec</name> <value>org.apache.hadoop.io.compress.SnappyCodec</value> </property>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号