hdfs内幕解析
1.hdfs的架构以及block块和副本机制
hdfs分布式文件系统也是一个主从架构,主节点是我们的namenode,负责整个集群以及维护集群的元数据信息。从节点是datanode,主要负责文件数据存储。
hdfs将所有的文件全部抽象为block块来进行存储,不管文件大小,全部一视同仁都是以block块的形式进行存储,方便我们的分布式文件系统对文件的管理。
在hadoop1文件的block块默认的大小是64M,而在hadoop2中文件的block块大小默认是128M。block块大小可以通过hdfs-site.xml当中的配置进行指定。
<property>
<name>dfs.block.size</name>
<value>块大小 以字节为单位</value>//只写数值就可以
</property>
1)抽象成数据块的好处
a)一个文件有可能大于集群中任意一个磁盘,大文件可以拆成多个block块完成存储
b)使用块抽象而不是文件可以简化存储子系统
c)块非常适合用于数据备份进而提供数据容错能力个可用性
2)块缓存
通常datanode从磁盘中读取块,但对于访问频繁的文件,其对应的块可能被显示的缓存在datanode的内存中,以堆外块缓存的形式存在。默认情况下,一个块仅缓存在一个datanode的内存中,当然可以针对每个文件配置datanode的数量。作业调度器通过在缓存块的datanode上运行任务,可以利用块缓存的优势提高读操作的性能
3)hdfs文件权限验证
hdfs的文件权限机制与linux系统的文件权限机制类似
r:read、w:write、x:execute 权限x对于文件表示忽略,对于文件夹表示是否有权访问其内容
如果linux系统用户a使用hadoop命令创建一个文件,name这个文件在hdfs当中的owner就是a
hdfs文件权限的目的是防止好人做错事,而不是阻止坏人做坏事。hdfs相信你告诉我你是谁你就是谁
4)hdfs的副本因子
为了保证block块的安全性,也就是数据的安全性,在hadoop2当中,文件默认保存三个副本,我们可以修改副本数以提高数据的安全性
在hdfs-site.xml 当中修改一下配置属性,即可更改文件的副本数,需要重新启动
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
命令修改
hdfs dfs -setrep num file:指定文件修改副本数、及时生效
2.hdfs的读写流程
1)hdfs的写入流程
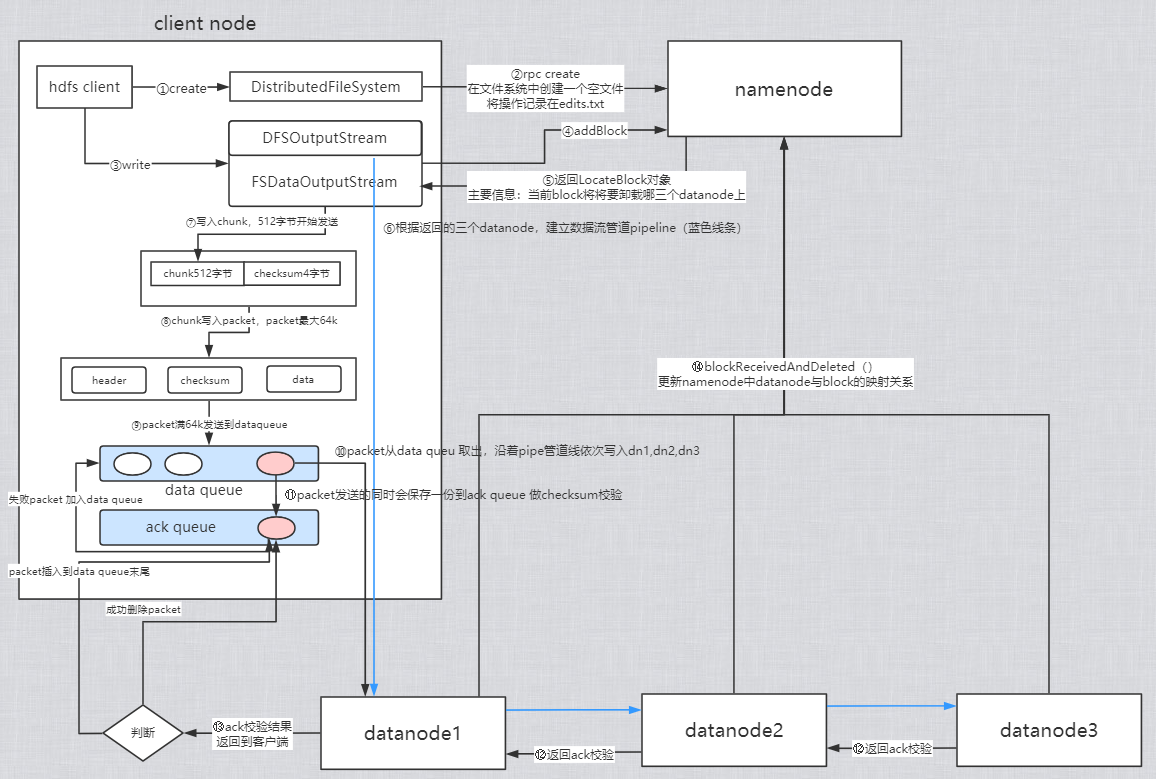
创建文件
①HDFS clinet 调用DistributedFileSystem.create()
②RPC远程调用namenode的create(),会在hdfs的目录树中指定的路径添加新文件,并返回给client FSDataOutPutStream,他是DFSOutPutStream的子类
(每次写入一个block,所有以下流程重复执行,直到文件所有的block都写入成功)
建立数据流管道pipeline:
③client调用FSDataOutPutStream.write()写数据(每次写一个块)
④DFSOutPutStream通过RPC调用namenode的addblock(),向namenode申请一个空数据块
⑤addBlock返回locatedBlock对象,此对象包含了当前的block要存储在哪三个datanode
⑥客户端根据位置信息建立流管道(蓝色线)
向数据流管道写当前的块数据
⑦写数据时,现将数据写入一个检验块chunk中,写满512字节后,对此chunk计算校验值
⑧将chunk与对应的校验值一起写入packet中,一个packet是64k
⑨源源不断地带着校验的chunk写入packet,packet写满后,将packet写入data queue
⑩packet从data queue中取出,沿着pipeline发送到dn1,再从dn1发送到dn2,再从dn2发送到dn3
⑪同时packet也会保存一份到 ack queue
⑫packet到达dn3后做校验,将校验结果逆着pipeline返回到dn2,dn2做校验传送到dn1,dn1也做校验结果返回到client
⑬客户端根据校验结果进行操作,如果返回成功则将保存在ack queue中的packet移除,如果失败则将packet从ack移除在加到data queue队尾
⑭block一个个packet传出,当此block发送完成,即dn1,dn2,dn3都有了block的完整副本,三个datanode分别发送RPC消息调用namenode的blockReceivedAndDeleted()更新namenode中datanode与block的映射关系,关闭pipeline数据流管道。
循环执行 ③ ~ ④ ,当文件所有的block都发送成功继续执行⑮
⑮文件的所有block发送成功,调用DFSDataOutPutStream.Close()
⑯客户端调用namenode的complete(),告知namenode提交这个文件所有的块数据,也就是整个文件的写入流程
写入的问题:
如果期间有datanode挂掉,data queue通知namenode创建新的datanode,并将现在主datanode的数据复制到新的datanode,续传data
2)hdfs的读取流程
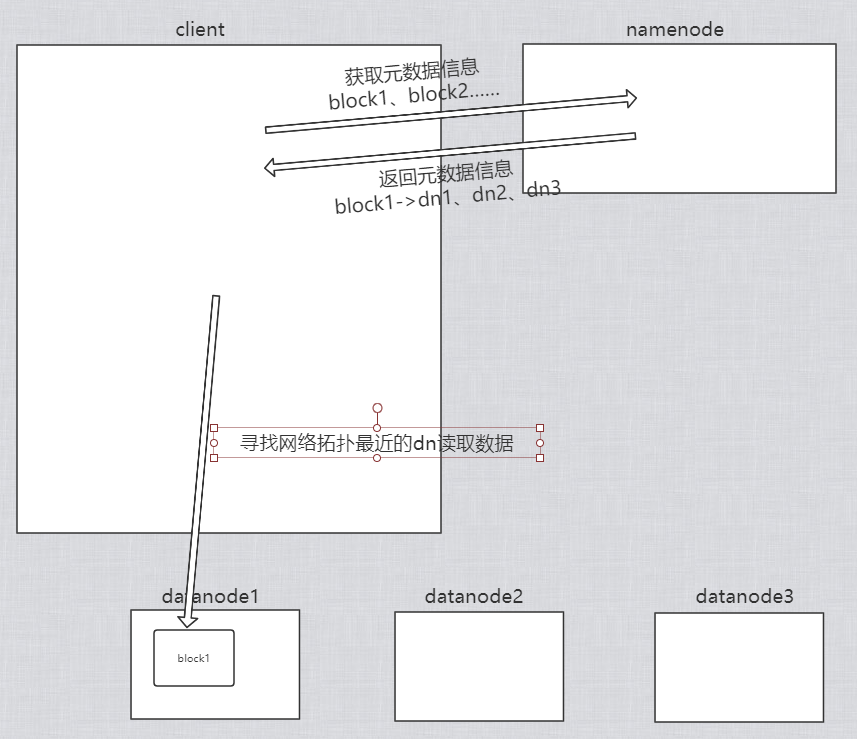
①client通过DistributedFileSystem向NameNode请求下载文件,NameNode通过查询元数据,找到文件所在的地址
②挑选一台datanode(就近原则,然后随机)服务器,请求读取数据
③datanode开始传输数据给客户端(从磁盘里读取数据输入流,以packet单位来做校验)
④客户端以packet单位接收,现在本地缓存,然后写入目标文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号