linux实用故障排查(大并发,大数据)
1.排查思路
大数据集群运行在linux系统上总会遇见各种各样的问题,我们要定位问题,基本上可以从这几个方面入手排查:cpu、内存、磁盘io、网络、GC等。
2.cpu
一些概念:多核,超线程,cpu频率(2.2GHZ)
(节能模式,普通模式,超能模式:biso里设置,搭建集群要注意下这个参数尽量关闭节能模式)
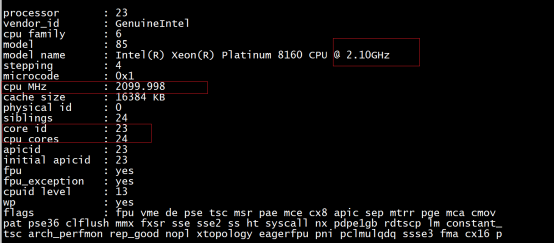
a.查看物理cpu个数:cat /proc/cpuinfo |grep "physical id"|sort |uniq|wc -l
b.查看逻辑cpu个数:cat /proc/cpuinfo |grep "processor"|wc -l
c.查看cpu多少核:cat /proc/cpuinfo
d.在生产集群中我们通常通过top来查看cpu的使用频率来判断系统的负载情况,top然后按1,可以看到cpu的使用率。

3.内存
a.常见内存大小16G-32G-64G-128G-256G,通过free -g来查看系统内存是否不足。

b.查看内存详细内容:cat /proc/meminfo

4.磁盘IO
a.磁盘种类:
sata(150M/s左右)、sas(300M/s)、ssd(最快)
一般磁盘2T~4T,服务器支持的最大存储也不同,比较常见的48T,一般服务器可以支持12~24块盘。
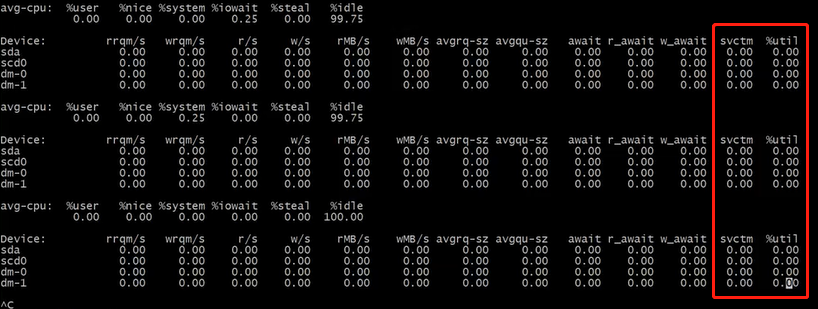
b.磁盘io的查看:iostat -mx 2
可以定位是否因为io过大导致性能下降 ,如果没有这个命令:yum install -y sysstat
util过大IO出现问题
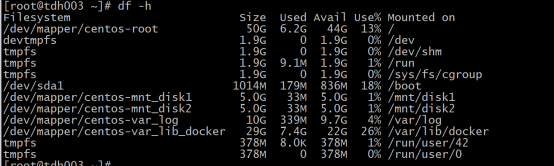
c.查看磁盘空间:df -h
根目录超过90%则有危险
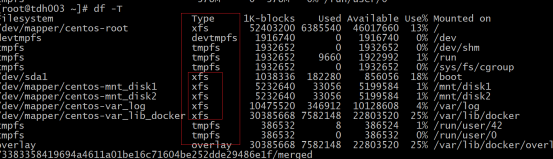
d.查看磁盘格式化的格式:df -T或cat /etc/fstab
主流一般是xfs和ext4,系统盘默认是xfs,后续添加数据盘尽量也是xfs格式,这样统一比较好,也方便写脚本批量挂在。
e.查看磁盘与未挂载磁盘和分区信息 :fdisk -l
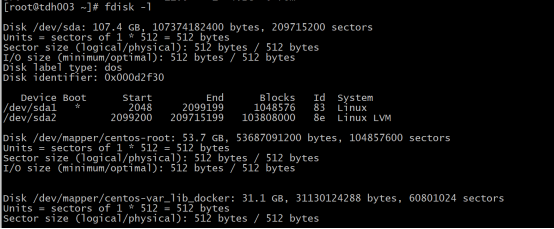
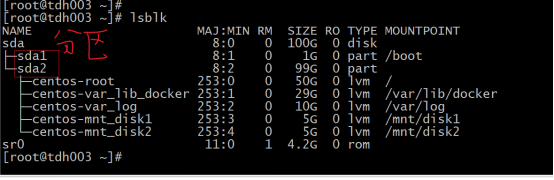
f.查看盘与分区以及ssd盘,用fdisk查看盘可能识别不到ssd:使用lsblk查看
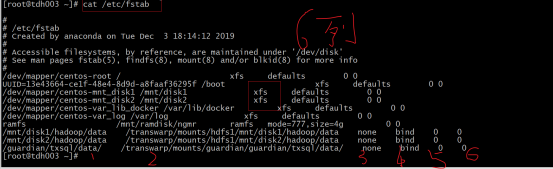
g.查看磁盘挂在信息,新加磁盘要手动永久挂载需要在下面配置文件添加以下内容,如果这个文件写错了,重启服务器正常模式下是启动不了的!
5.网络
a.查看是否ping通:ping www.baidu.com
b.查看端口是否被监听:netatat -anp|grep 端口号
ex:你起启动datanode没有启动,查看日志报错:Address in used ,翻译过来就是端口被占用,那你得查看下这个端口被哪个程序占用了,就用 netatat -anp|grep 端口号,
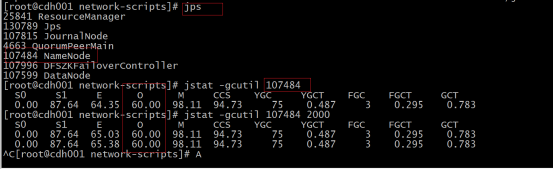
就可以知道它的进程,比如下图进程pid就是107484,就可以用kill -9 PID强制杀死

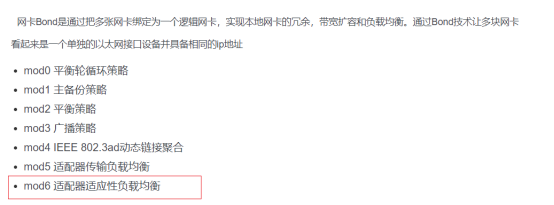
c.网卡模式配置(bound6,负载均衡):参考

6.系统负载:
linux命令:top、uptime、w、cat /proc/laodavg
7.GC问题(java)
是否full GC
jps查出要看的pid,用jstat-gcutil pid看第四列0如果100%就是fullGC
8.日志查看(hadoop)
a.首先要知道日志的位置,一种是去配置文件查看了有没有配置相关位置,一种是通过进程查看。如下
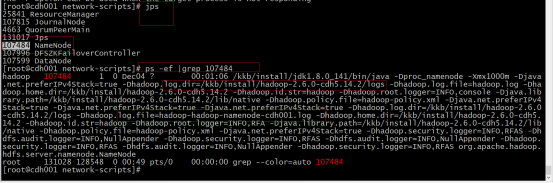
使用 ps -ef | grep pid通过pid显示出来的信息可以找到日志位置。
查看某个进程日志位置:
b.查看日志
实时查看日志文件后100行:tail -f 100 file
静态查看:vim filelog,然后可以通过关键字error/warn等查找错误

 浙公网安备 33010602011771号
浙公网安备 33010602011771号