
requests发送http请求
requests发送http请求
发送请求:(数据获取、乱码解决)
import requests
response = requests.get('http://www.baidu.com') # get post head ...
可以debug运行,可以查看response的响应内容。请求返回的值是一个对象,是对HTTP协议中服务端返回给客户端的数据封装。
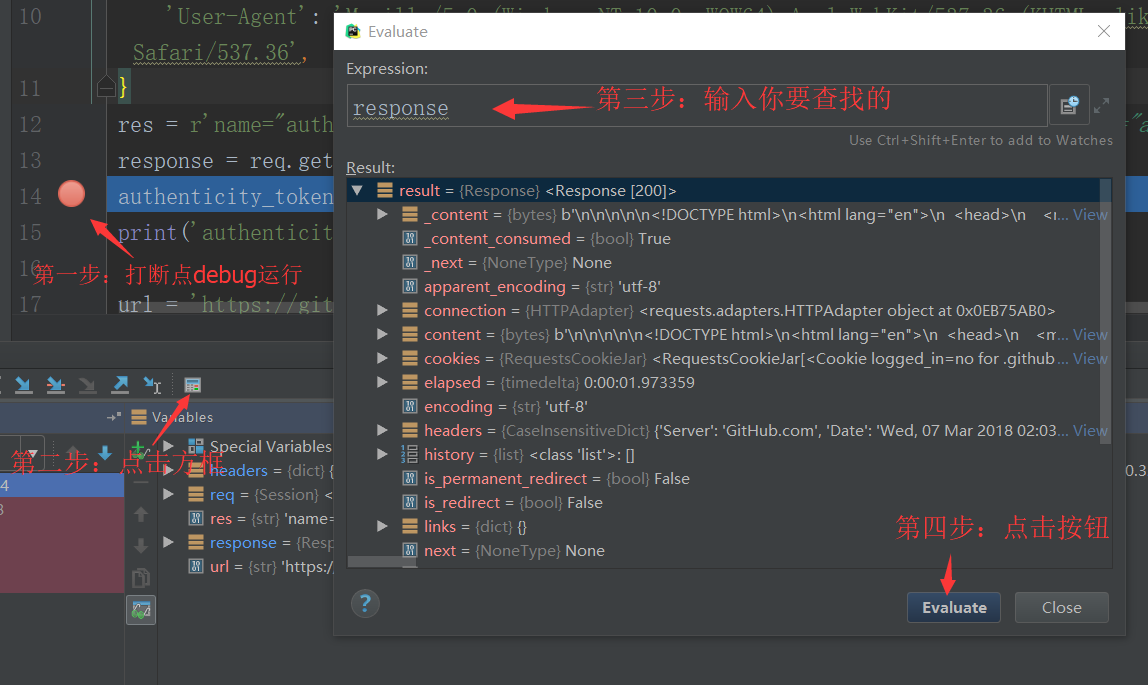
注意后边的view是可以点击预览的。
取响应对象的headers:

运行结果:(部分代码)
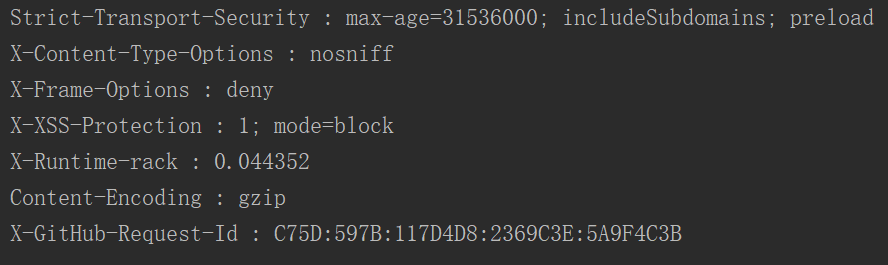
response.content返回字节串(原始数据:图片、音频、视频一般用它)
response.text 适用于文本数据,数据经过转码的
response.encoding 可能返回 ISO-8859-1 ; 这个时候要注意编码方式,代码默认获取headers里的content-type,
如果里面没有或没有charset就返回ISO-8859-1 。我们可以从文本数据里获取,也可以encode().decode()的方
式取解码。或者直接对response.content解码:response.content.decode(),文本的乱码就解决了。
get方法里的参数parms: 对url进行传参(一个拼接),适用于爬取某些网页的链接,这些链接只有当前网页的
后半段。

get、post等最后都会调用:

查询参数:
在返回的console里可以直接搜索你要查找的内容:CTRL+F
超时设置:
timeout参数:timeout = 3 一般这个参数都是需要设置的。
cookies:
cookies的问题可以传入cookies;也可以调用session()方法
cook = response.cookies, 再将cook传给参数cookies
req = requests.session()
解决HTTP的无状态:
req = requests.session() # 构建一个会话,Session()和session()大小写一样
用req去发送请求,自动将需要的参数传入。
ssl认证:
verify参数设置为False,表示步验证证书,会给出警告,不会报错!默认是 verify=None
跳转:
allow_redirects参数默认为None,设置为False,请求就不会跳转,在headers里的location我们可以
找到跳转的网址。
代理设置:
proxies = {
http': 'http://10.30. .....',
'https': 'http://10.30 ......',
}
将proxies传给参数proxies。
