
VAN:视觉注意力网络--大核注意力机制
VAN:Visual Attention Network
项目地址:https://github.com/Visual-Attention-Network
论文地址:https://arxiv.org/pdf/2202.09741.pdf
一、摘要
虽然最初 self-attention是为自然语言处理(NLP)任务而设计的,但是最近已经风靡了计算机视觉的各个领域。然而,图像的2D特性给在计算机视觉中应用自我注意带来了三个挑战。
- 将图像视为一维序列忽略了其二维结构。
- 二次复杂度对于高分辨率图像来说太昂贵了。
- 它只捕捉空间适应性,而忽略了通道适应性。
在本文中,我们提出了一种新的大核注意力模块(LKA),在避免上述问题的同时,实现了self-attention中的自适应和长依赖相关性。我们进一步介绍了一种基于LKA的新型神经网络,即视觉注意网络(VAN)。虽然非常简单高效,但在大量实验中,VAN的表现优于最先进的视觉transformers和卷积神经网络,包括图像分类、对象检测、语义分割、实例分割等。
二、介绍
在计算机视觉领域。卷积神经网络(CNN)[41,40,39]由于其显著的特征提取性能,在过去十年中是不可或缺的主角。AlexNet[39]重新开启深度学习十年后,通过使用更深的网络[68,29]、更高效的架构[31,90102]、更强的多尺度能力[35,71,19]和注意力机制[34,17],在获得更强大的视觉支柱方面取得了一些突破。由于平移不变性和共享滑动窗口策略[67],CNN对于具有任意大小输入的各种视觉任务具有固有的效率。更先进的视觉主干网络通常会在各种任务中带来显著的性能提升,包括图像分类[29,17,52]、目标检测[14]、语义分割[89]和姿势估计[80]。
研究人员认为人类视觉系统只处理部分可能的刺激细节,而其余几乎未经处理。选择性注意力是处理视觉中复杂搜索组合方面的重要机制[77]。注意机制可以看作是一个基于输入特征的自适应选择过程。自从完全注意网络(fully attention)[78]被提出以来,self-attention(又称Transformer)迅速成为自然语言处理(NLP)中占主导地位的结构[16,5]。最近,Dosovitskiy等人[17]提出了视觉transformer(ViT),它将transformer主干引入计算机视觉,在图像分类任务上优于著名的CNN。得益于其强大的建模能力,基于transformer的视觉主干迅速占据了各种任务的排行榜,包括目标检测[52]、语义分割[89]等。
在本文中,我们提出了一种新的注意机制:大内核注意力(LKA),它是为视觉任务量身定制的。LKA吸收了卷积和self-attention的优点,包括局部结构信息、长依赖性和适应性。同时,它避免了它们在渠道维度上忽视适应性等缺点。在LKA的基础上,我们提出了一种新的视觉主干,称为视觉注意网络(VAN),它显著超过了著名的基于CNN和基于transformer的主干。本文的贡献总结如下:
- 我们设计了一种新的计算机视觉注意机制LKA,它既考虑了卷积和自注意力的优点,又避免了它们的缺点。在LKA的基础上,我们进一步介绍了一种简单的视觉主干,称为VAN。
- 在大量的实验中,包括图像分类、目标检测、语义分割、实例分割等,我们发现VANs比最先进的ViTs和CNN有很大的优势。包括swin transformer。
三、相关工作
3.1 卷积神经网络
如何有效地计算强大的特征表示是计算机视觉中最基本的问题。卷积神经网络(CNN)[41,40]利用局部上下文信息和形变不变性,极大地提高了神经网络的效率。自AlexNet[39]以来,CNN迅速成为计算机视觉领域的主流框架。为了进一步提高效率,研究人员投入大量精力使CNN更深[68,29,35,71],更轻[31,65102]。我们的工作与MobileNet[31]相似,后者将标准卷积分解为两部分,深度卷积和point卷积(也称为1×1 Conv[43])。我们的方法将卷积分解为三部分:深度卷积、深度和扩展卷积[9,93],以及点卷积。得益于这种分解,我们的方法更适合于高效分解大型核卷积。我们还将注意机制引入到我们的方法中,以获得自适应特性。
3.2 视觉注意力方法
注意机制可以被视为根据输入特征的自适应选择过程,该特征在RAM中被引入计算机视觉[56]。它在许多视觉任务中提供了优势,例如图像分类[34,86]、目标检测[14,32]和语义分割[96,20]。计算机视觉中的注意可分为四个基本类别[25],包括通道注意、空间注意、时间注意和分支注意,以及它们的组合,如通道和空间注意。每种注意力在视觉任务中都有不同的效果。
self-attention源于NLP[78,16],是一种特殊的注意机制。由于它能有效地捕捉远距离依赖性和适应性,因此在计算机视觉中扮演着越来越重要的角色[84,18,62,97,99,91]。各种深度self-attention网络(又称视觉transformers)[17,7,52,22,69,83,95,47,48,4,50,87,51,27]在不同的视觉任务上取得了比主流CNN更好的性能,显示了基于注意力模型的巨大潜力。然而,self-attention是为NLP设计的。在处理计算机视觉任务时,它有三个缺点。
- 它将图像视为一维序列,忽略了图像的二维结构
- 二次复杂度对于高分辨率图像来说太昂贵了
- 它只实现了空间适应性,而忽略了通道维度的适应性。
对于视觉任务,不同的通道通常代表不同的对象[11,25]。通道适应性对于视觉任务也很重要[34,86,60,81,11]。为了解决这些问题,我们提出了一种新的视觉注意方法,即LKA。它涉及自我关注的优点,如适应性和长期依赖性。此外,它还受益于卷积的优点,例如利用本地上下文信息。
3.3 视觉多层感知器
在CNN出现之前,多层感知器(MLP)[63,64]是一种流行的计算机视觉工具。然而,由于计算量大、效率低,MLPs的性能长期受到限制。一些研究成功地将标准MLP解耦为空间MLP和信道MLP[72,23,73,46]。这种分解可以显著降低计算成本和参数,从而释放出MLP惊人的性能。读者可以参考最近的调查[24,49],以获得对MLP更全面的审查。与我们最相关的MLP是gMLP[46],它不仅分解了标准MLP,还涉及注意机制。然而,gMLP有两个缺点。一方面,gMLP对输入大小敏感,只能处理固定大小的图像。另一方面,gMLP只考虑图像的全局信息,而忽略了图像的局部结构。我们的方法可以充分利用其优点,避免其缺点。
四、方法
4.1 大核注意力机制
注意机制可以看作是一个自适应选择过程,它可以根据输入特征选择有区别的特征,并自动忽略噪声响应。注意机制的关键步骤是制作注意特征图,以显示不同点的重要性。要做到这一点,我们应该了解不同点之间的关系。
有两种众所周知的方法来建立不同点之间的关系。第一种是采用自我注意机制[84,97,99,17]来捕捉长依赖。在计算机视觉中应用自我注意有三个明显的缺点,这些缺点已经在第3章中列出。第二种方法是使用大核卷积[86,79,33,58]建立相关性并生成注意特征图。这种方式仍然存在明显的缺点。大的内核卷积会带来大量的计算开销和参数。
为了克服上面列出的缺点,并利用self-attention和大核卷积的优点,我们建议分解一个大核卷积运算来捕获长程关系。如图二所示,大型内核卷积可分为三个部分:空间局部卷积(深度卷积)、空间远程卷积(深度扩展卷积)和通道卷积(1×1卷积)。明确地我们可以将一个卷积分解为一个深度方向的膨胀卷积,其中膨胀率为,一个深度卷积和卷积。通过上述分解,我们可以用少量的计算成本和参数捕捉长期关系。在获得长期关系后,我们可以估计一个点的重要性并生成注意力特征图。其中LKA模块可以写为:
是输入特征。表示注意图。注意力特征图中的值表示每个特征的重要性。意味着元素的点乘。如表1所示,我们提出的LKA结合了卷积和自注意力的优点。它考虑了局部语境信息、大的感受野和动态过程。此外,LKA不仅实现了空间维度的适应性,还实现了信道维度的适应性。值得注意的是,在深层神经网络中,不同的通道通常代表不同的对象[25,11],通道维度的适应性对于视觉任务也很重要。
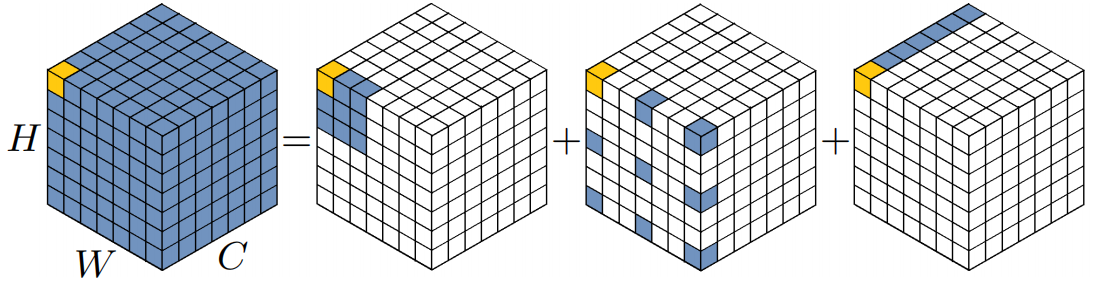
从左到右依次是标准大卷积、DW卷积(depth-wise conv)、DW-D卷积(depth-wise dilation conv)、卷积;黄色点标识卷积核的中心,标准卷积是的卷积核、深度卷积是的卷积、深度空洞卷积是的空洞卷积膨胀率为3,点卷积是卷积

4.2 视觉注意力网络VAN
我们的VAN具有简单的层次结构,即一个4个stage的输出特征序列,分辨率依次为:。这里,H和W表示输入图像的高度和宽度。随着分辨率的降低,输出通道的数量也在增加。输出通道的变化显示在下表中:
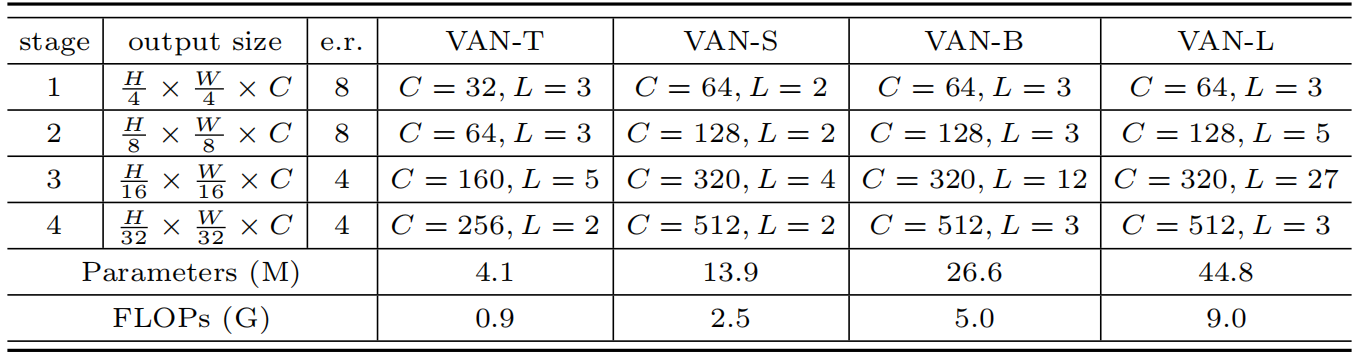
如下表所示,每一个stage,对于输入我们首先下采样,并使用步长控制下采样率。下采样后同一个stage保持所有layer输出同样大小的特征图,即分辨率和通道数都是一样的。然后,将组批量标准化[36]、GELU激活[30]、大核注意和卷积前馈网络[82]按顺序叠加以提取特征。最后,我们在每个阶段结束时应用层标准化[2]。根据参数和计算成本,我们设计了四种结构:VAN-Tiny、VAN-Small、VAN-Base和VAN-Large。整个网络的详细信息显示在上表中。
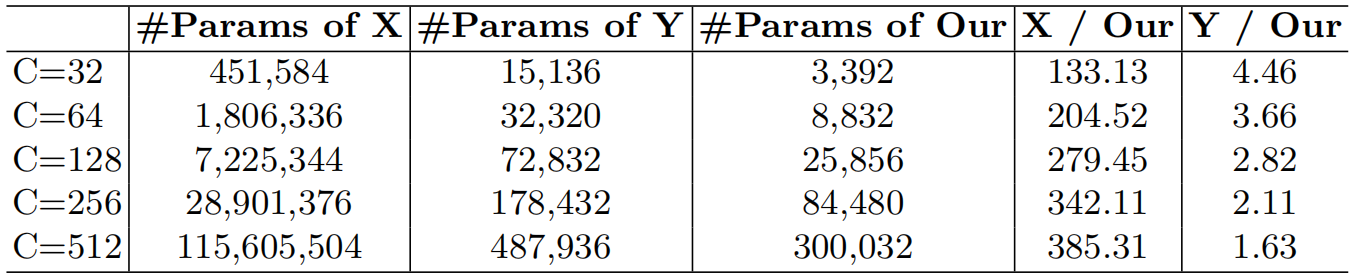
分别是标准卷积、mobilent的解耦卷积(深度卷积+点卷积)
计算复杂度分析
我们给出了分解的参数和浮点运算(FLOPs)。为了简化格式,在计算过程中省略了偏差。我们假设输入和输出特征具有相同的大小。参数和FLOPs为:
其中是卷积核的大小,是膨胀率。这里作者实验默认设置。上表展示了在这个配置下各种技术的参数量。
实施细节
首先是一个LKA结构,它包含:
- 的深度卷积
- 膨胀率为3,的深度卷积
- 的点卷积
所以,LKA近似实现了的卷积,因为带膨胀的深度卷积感受野是的区域(实际上好像是的一个区域)。在此设置下,VAN可以有效地实现局部信息和远程信息融合。我们分别使用步长为和卷积进行和下采样。
模型消融
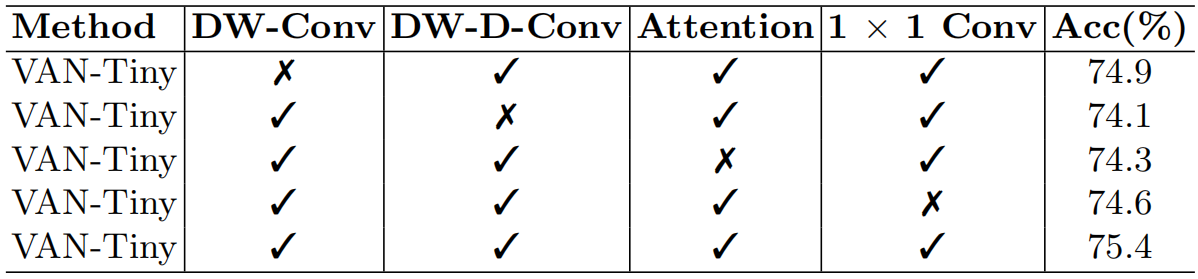
模型架构
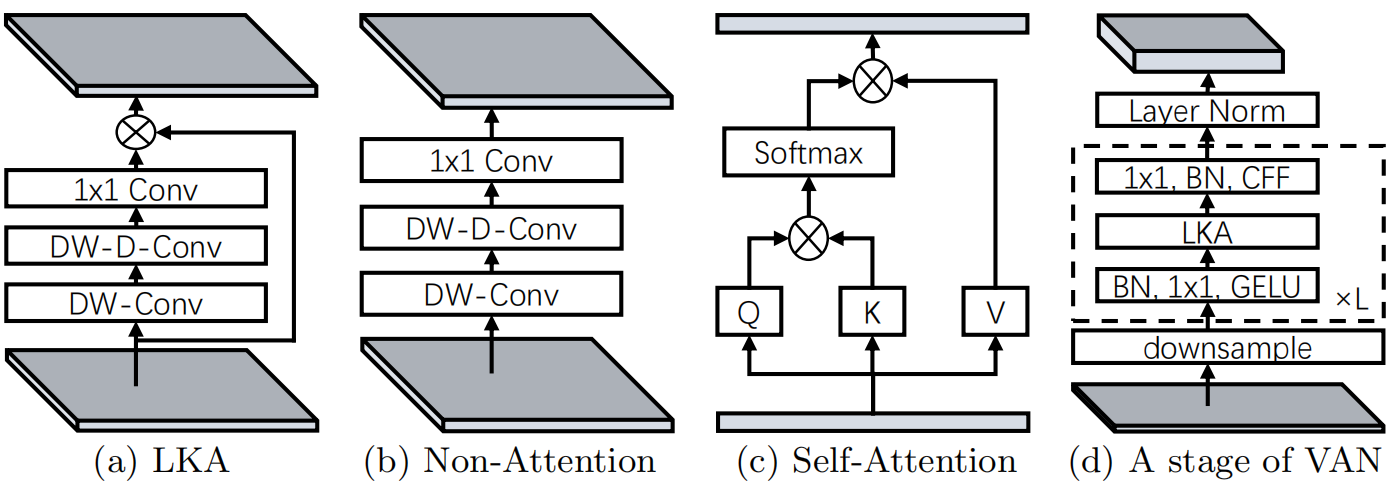
表示卷积前馈神经网络。
五、模型性能
-
图像分类
VAN-Tiny VAN-Small VAN-Base VAN-Large TOP1 ACC 75.4 81.1 82.8 83.9 参数 4.1 13.9 26.6 44.8 计算量 0.9 2.5 5.0 9.0 在参数量、计算量相当的情况下,获得了更好的收益!(INAGENET数据集)
-
目标检测
和swin transformer差不多
-
实例分割
mIOU 达到50.1
更多细节参考论文。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 上周热点回顾(3.3-3.9)
2020-02-25 命令行参数