
CTC论文分析
CTC::Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks(论文解析)
论文地址:https://people.idsia.ch//~santiago/papers/icml2006.pdf
1、摘要
许多实际的序列学习任务需要从有噪声的、未分段的输入数据中预测标签序列。例如,在语音识别中,声音信号被转录成单词或亚单词单位。递归神经网络(RNN)是一种强大的序列学习器,似乎非常适合此类任务。然而,由于它们需要预先分段的训练数据,以及将其输出转换为标签序列的后处理,因此它们的适用性迄今受到限制。本文提出了一种训练RNN直接标记未分段序列的新方法,从而解决了这两个问题。在TIMIT语音语料库上的实验表明,该方法优于基线隐马尔可夫模型HMM和混合隐马尔可夫模型HMM-RNN。
CTC的主要贡献:
- 不需要对输入序列预分段,解决了输入序列片段长短不一的分片问题;
- 不需要将输入序列转换为标签序列对应的长度,解决了序列预测中的对齐问题。
2、相关介绍
标记未分段的序列数据是现实世界序列学习中普遍存在的问题。它在感知任务(例如手写识别、语音识别、手势识别)中尤其常见,在感知任务中,噪声、实值输入流用离散标签(例如字母或单词)的字符串进行标注。
目前,图形模型如隐马尔可夫模型(HMMs;Rabiner,1989),条件随机场(CRF;Lafferty等人,2001)及其变体是序列标记的主要框架。虽然这些方法在解决许多问题方面取得了成功,但它们也有一些缺点:
- (1) 它们通常需要大量特定于任务的知识,例如HMMs设计为状态模型,crf为选择输入特征;
- (2) 它们需要明确的(而且常常是有问题的)依赖性假设,以使推论易于处理,例如,假设观测值对HMMs是独立的;
- (3) 对于标准HMM,训练是生成性的,即使序列标记是有区别的。
另一方面,递归神经网络(RNN)不需要数据的先验知识,只需要选择输入和输出表示。它们可以被区别地训练,它们的内部状态为时间序列建模提供了强大的通用机制。此外,它们往往对时间和空间噪声具有鲁棒性。
然而,到CTC为止,还不可能将RNN直接应用于序列标注预测。问题是,标准的神经网络目标函数分别为训练序列中的每个点定义;换句话说,RNN只能训练成一系列独立的标签分类。这意味着必须对训练数据进行预分割,并且必须对网络输出进行后处理以给出最终的标签序列。
目前,RNNs用于序列标注预测的最有效的方法是以所谓的混合方法将它们与HMM结合起来(Bourlard&Morgan,1994;班吉奥,1999年)。混合系统利用HMMs对数据的长距离序列结构进行建模,神经网络提供局部分类。HMM组件能够在训练过程中自动分割序列,并将网络分类转换为标签序列。然而,混合系统除了继承了HMMs的上述缺点外,也没有充分利用rnn的全部poten进行序列建模。(注:如果隐马尔可夫可以理解其本质含义,则这段话不难理解)
本文提出了一种用RNN标记序列数据的新方法CTC,该方法不需要预先分段的训练数据和后处理的输出,并且在单个网络结构中对序列的各个方面进行建模。其基本思想是在给定的输入序列的条件下,将网络输出解释为所有可能标签序列的概率分布。给定这个分布,可以导出一个目标函数,直接使正确标注的概率最大化。由于目标函数是可微的,因此可以通过标准反向传播对网络进行训练(Werbos,1990)。
在下文中,我们将标记未分段数据序列的任务称为时间分类(Kadous,2002),并将RNN用于此目的称为连接主义时间分类(CTC)。相比之下,我们将输入序列的每个时间步或帧的独立标记称为帧分类。
下一节提供了时间分类的数学形式,并定义了本文中使用的误差度量。第4节描述了允许RNN用作时态分类器的输出表示。第5节解释如何训练CTC网络。第6节在TIMIT语音语料库上比较了CTC与混合系统和HMM系统。第7节讨论了CTC与其他时态量词的一些主要区别,并给出了今后工作的方向,最后给出了第7节的结论。(注:我们只关注到第5节,后续实验请查看论文)
3、时间分类 Temporal Classifification
令\(S\)是训练样本,其分布在\(D_{X \times Z}\)上。输入空间\(X=\left ( \mathbb{R}^{m} \right )^{*}\)是一个\(m\)维的特征向量,即自变量的值域。标注空间\(Z=L^{*}\)是标签(有限)字母\(L\)上所有序列的集合,即因变量的值域。通常,我们会使用\(L^{*}\)中的一个元素作为标注--label。因此,我们知道数据集\(S\)是由数据\(\bf{\left ( x,z \right )}\)对组成。输入序列\(\bf{x}\)=\(\left ( x_{1},x_{2},\cdots ,x_{T} \right )\)比输出序列\(\bf{z}\)=\(\left ( z_{1},z_{2},\cdots ,z_{U} \right )\)要长,即\(U \leq T\)。由于输入序列和目标序列的长度通常不相同,因此没有先验的方法来对齐它们。
注:样本是序列!
我们要做的就是基于数据集\(S\)训练一个时间分类器模型:\(h: X \mapsto Z\) 实现对以前看不见的输入序列进行分类,使某些特定于任务的错误度量最小化。
3.1 标本错误率 Label Error Rate
这里作者引入了LER损失。
LER损失定义:
对于给定的测试集\({S}'\subset D_{X \times Z}\),与训练集\(S\)不相交,LER损失为测试集标注序列与分类器预测序列之间的编辑距离:
其中,\(L_{num}\)是测试集的数据对数量;\(ED(p,q)\)表示序列\(p,q\)之间的编辑距离!编辑距离可以理解为从序列\(p\)到序列\(q\)的最小操作次数(增、删、改操作)。
这是一个自然措施的任务(如语音或手写识别),其目的是尽量减少转录错误率。
4、连接主义时间分类 CTC
本节描述了允许将递归神经网络用于CTC的输出表示。关键步骤是将网络输出转化为标签序列上的条件概率分布。然后,通过为给定的输入序列选择最可能的标签,该网络可被用作分类器。
4.1 从网络输出进行标注
CTC网络层由一个\(softmax\)输出层,输出比所有标注还要多一个单元,即如果标注集字符最大为100,那么需要输出101个特征。多出的那个单元就是“blank”,或者没有标签。这些输出一起定义了将所有可能的标签序列与输入序列对齐的所有可能方式的概率。任何一个标签序列的总概率可以通过求其不同排列的概率之和来得到。
对于长度为\(T\)的输入序列\(\bf{x}\),定义一个RNN网络,其输入是\(m\)维的特征向量,输出为\(T\)个长度为\(n\)的特征向量,记连接映射为:$\mathbb{N}_{w}: \left ( \mathbb{R}^{m} \right )^{T} \mapsto \left ( \mathbb{R}^{n} \right )^{T} $ ,其中\(w\)为权值向量。令\(\bf{y}\)=\(\mathbb{N}_{w}(\bf{x})\) 是网络的输出序列,我们使用\(y^{t}_{k}\)表示第\(k\)个单元第\(t\)个时刻的激活值,同时它也表示了在第\(t\)个时刻标签为第\(k\)个单元的概率。\(y^{t}_{k}\)定义了一个序列长度为\(T\),在集合\({L}'^{T}\)上的分布,其中字母表\({L}'=L\, \cup \, \left \{ blank \right \}\),概率分布为:
至此,我们可以将\({L}'^{T}\)看作所有可能路径集合,并使用\(\pi\)来表示一条路径。
注:这里为什么使用\(y^{t}_{\pi_{t}}\)的乘积表示概率分布?因为这个值是激活值,在神经网络中我们可以用它表示时刻\(t\)中label \(\pi_{t}\)的概率。假设它条件独立,则成绩即为概率分布。
上式中隐含的假设是:给定网络的内部状态,网络在不同时刻的输出是有条件独立的。这是通过要求不存在从输出层到自身或网络的反馈连接来确保的。
上面是一一映射,这只能解决统计学上的条件概率预测问题,不能解决我们的痛点:序列对齐。那么下面我们采用多对一映射来解决这个问题。
我们定义一个 many_to_one 的映射\(\textbf{B}:\,{L}'^{T} \mapsto L^{\leqslant T}\),其中\(L^{\leqslant T}\)是可能的标签序列(对于一个标签序列可以有多个预测序列可以映射到正确的标签序列,所以是多对一映射)。映射\(\textbf{B}\)我们可以定义为移除分割符blanks和重复的字符。如:
\(\textbf{B}\left ( a-abb- \right )=\textbf{B}\left ( -aa--abb \right )=aab\)
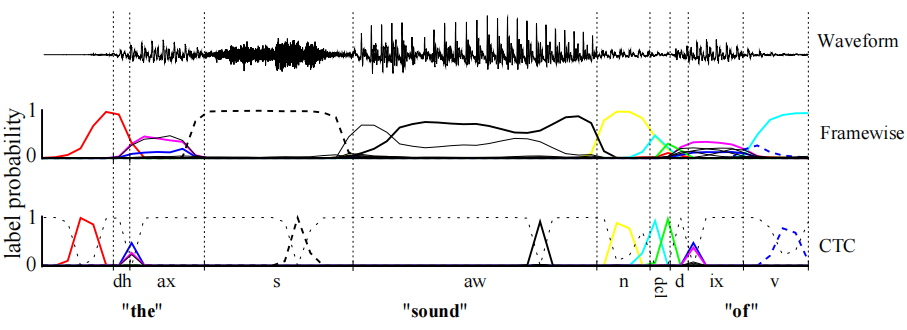
上图中的声波通过算法映射到预测结果Framewise,经过多对一映射即得到最后的输出序列。
最后我们对所有可以映射到标注的标签序列路径概率求和,即得到从输入到输出的条件概率。假设标签序列为 \(\textbf{l}\) ,则对于给定的输入 \(\textbf{x}\) ,由输入得到输出的概率为:
其中,\(\textbf{B}^{-1}\left ( \textbf{1} \right )\)表示可以映射到标注序列 \(\textbf{l}\) 的所有路径的集合。
4.2 构造分类器
对于上面的公式(3),输出的分类器应该具体输出标注序列的概率要最大化,即:
\(h\left ( \bf{x} \right )=\mathop{\arg\max}\limits_{\textbf{l} \in L^{\leqslant T}} \,\, p\left ( \textbf{l}|\textbf{x} \right )\)
使用HMMs的术语,我们把寻找这个标签的任务称为解码。不幸的是,对于优化函数\(h\left ( \bf{x} \right )\),我们不知道一个通用的、易于处理的解码算法。但以下两种近似方法在实际应用中效果良好。
第一种方法(最佳路径解码)基于最可能路径将对应于最可能标签的假设:
其中,\(\pi^{*} = \mathop{\arg\max}\limits_{\pi \in N^{t}} p\left ( \pi | \textbf{x} \right )\)。最佳路径解码是的计算量很小,因为 \(\pi^{*}\) 只是每个时间步中最活跃的输出的串联。然而,并不能保证找到概率最大的标签序列(即这里是有一个标签之间两两独立的假设)。
第二种方法(前缀搜索解码)依赖于这样一个事实,即通过修改第5.1节的前后向算法,我们可以有效地计算标签前缀连续扩展的概率(如下图)。
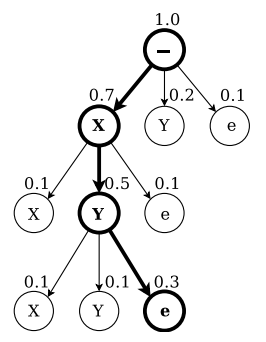
如果有足够的时间,前缀搜索解码总是找到最可能的标签。但是,它必须扩展的最大前缀数随输入序列长度呈指数增长。如果输出分布在模式周围达到足够的峰值,它仍将在合理的时间内完成。然而,对于本文的实验,还需要进一步的启发,使其应用成为可能。
我们观察到一个训练过的CTC网络的输出趋向于形成一系列由强烈预测的空白隔开的尖峰(图1),我们将输出序列分成很可能以空白开始和结束的部分。我们通过选择观察空白标签的概率高于某个阈值的边界点来实现这一点。然后,我们分别计算每个部分的最可能标签,并将它们连接起来以得到最终分类。(即在图一中,CTC对应的那一行数据,空白部分是发声的位置片段)
在实践中,前缀搜索很好地使用了这种启发式算法,并且通常优于最佳路径解码。但是,在某些情况下,它确实会失败,例如,如果在截面边界的两侧弱预测相同的标签。
5、网络训练
到目前为止,我们已经描述了一个输出表示,它允许RNN用于CTC。我们现在导出一个用梯度下降法训练CTC网络的目标函数。
目标函数由极大似然原理导出。也就是说,最小化它最大化了目标标签的对数可能性。请注意,这与标准神经网络目标函数的基本原理相同(Bishop,1995)。给定目标函数及其对网络输出的导数,可以通过标准序列反向传播计算权重梯度。然后可以使用当前用于神经网络的任何基于梯度的优化算法来训练网络(LeCun等人,1998;施劳多尔夫,2002年)。
我们从最大似然函数所需的算法开始。
5.1 CTC的前向与后向传播算法
我们需要高效地计算每个标签序列的条件概率。如公式(3)所提到的:对于一个标注的标签序列,是有很多的预测序列可以映射到标注序列。
幸运的是,这个问题可以用动态规划算法来解决,类似于HMMs的前向-后向算法(Rabiner,1989)。关键思想是,与一个标号对应的路径上的和可以分解为与该标号的前缀对应的路径上的迭代和。然后可以使用递归的前向和后向变量有效地计算迭代。
对于长度为\(r\)的序列\(\textbf{q}\) ,使用 \(\textbf{q}_{1:p}\) 和 \(\textbf{q}_{r-q:r}\) 分布表示前\(p\)、后\(p\) 个标签。对于一个标注序列 \(\textbf{l}\) ,使用前向变量 \(\alpha_{t}\left( s \right)\) 表示 \(\textbf{l}_{1:s}\) 的总概率:
如上式所示,我们可以递归地计算 \(\alpha_{t-1}\left( s \right)\) 和 \(\alpha_{t-1}\left( s-1 \right)\) 。
为了允许空白分割出现在输出的路径序列中,我们修改标签序列,将空白分割符加入标注的序列,得到新的标注标签序列 \({\textbf{l}}'\) ,它的长度为 \(2\left | \textbf{l} \right | + 1\) 。在计算 \({\textbf{l}}'\) 前缀的概率时,我们允许空白和非空白标签之间的所有转换,以及任何一对不同的非空白标签之间的转换 (即所有标签可以转移到空白标签 \(\left( b \right)\),反之亦可;所有非空白标签可以随意转移)。并且允许序列以空白符或者原序列第一个字符开始。
则初始化的状态概率为:
\(\alpha_{1}\left( 1 \right) = y_{b}^{1},\,\alpha_{1}\left( 2 \right) = y_{\textbf{l}_{1}}^{1},\,\alpha_{1}\left( s \right) = 0,\,\forall s>2\)
于是,可以循环获取:
其中:
注意吗,对于\(\alpha_{t} \left ( s \right ) \,\, \forall s < \left | {\textbf{l}}' \right | - 2\left ( T-t \right ) - 1\),因为这些变量对应的状态没有足够的时间步来完成序列(图3右上角未连接的圆)。
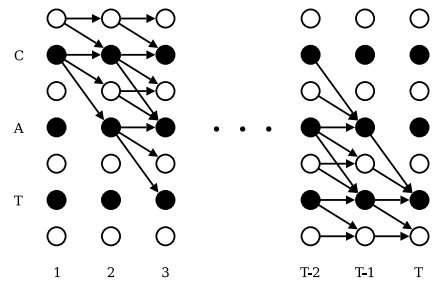
同时 \(\alpha_{t}\left( s \right) = 0 \,\, \forall s<1\) 。
最后序列 \(\textbf{l}\) 的概率是没有最后一个分隔符状态下的 \({\textbf{l}}'\)的和有最后的分割符的 \({\textbf{l}}'\) 的概率之和,即:
反向传播类似可得,详情见论文4.1节。

实际上上诉算法很快就会导致underflows问题,即一串很小的数连续相乘,最终计算机会归到0。为了避免这种情况,可以使用:
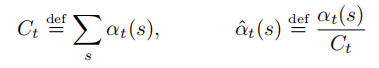

最后得到的目标函数为:
\(ln \left( p \left( \textbf{l} |\textbf{x} \right) \right) = \sum_{t=1}^{T} ln\left ( C_{t} \right )\)
5.2 最大似然的训练
根据最大似然函数的求解理论,我们很容易导出,最后我们要求下式的最小值:
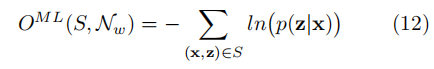
关于某时刻输出的偏导为:
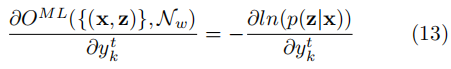
关于上式的计算就会使用带上一节中提到的算法。
这里的关键点在于:对于标注序列\(\textbf{l}\),其前向、后向变量是对给定字符\(s\)在\(t\)时刻的概率,对应了所有映射到 \(\textbf{l}\) 的路径在\(t\)时刻取到字符\(s\)的总概率。
根据前面的公式有:
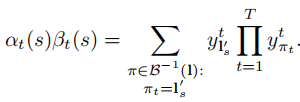
对公式(2)进行排列替换有:

至此我们就使用前向变量、后向变量两者乘积表示出可能路径的所有概率之和(\(t\)时刻字符为\(s\)的总概率)。
结合公式(3),即\(t\)时刻可能出现的字符集为\(\left| {\textbf{l}}’ \right|\) ,所以有:
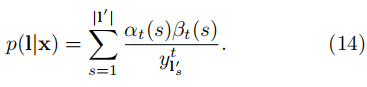
为了区分表示\(y_{k}^{t}\),这里我们只考虑在\(t\)时刻取到字符\(k\)。我们要注意,在原始的标签序列中可能会有同样的字符连续出现,我们定义一个位置的集合\(lab \left( \textbf{l},k \right) = \left\{ s: \, {\textbf{l}}’_{s}=k \right\}\),集合可能为空。则上式可以转换为:
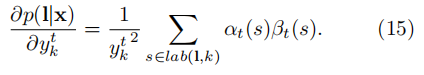
注:参考图三,在时刻\(\textbf{t}\)取到字符\(k\)的情况可能有很多,因为标注的标签序列可能会有相同字符,令s表示序列中的某个字符,注意\({\textbf{l}}’_{s}=k\)的\(s\)可以是不同的,如序列第三个字符为\(k\),和序列第五个字符也为\(k\)。
所以最后得出:
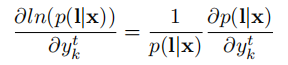
完!
