
DB的数据处理与加载
DB--数据增强、加载
1、DataLoader简介
以train为例,模型为resnet50,使用配置experiments/seg_detector/totaltext_resnet50_deform_thre.yaml。
train_data_loader = self.experiment.train.data_loader得到了数据加载的实例,for batch in train_data_loader是逐个batch进行取数据。
实例化数据加载类
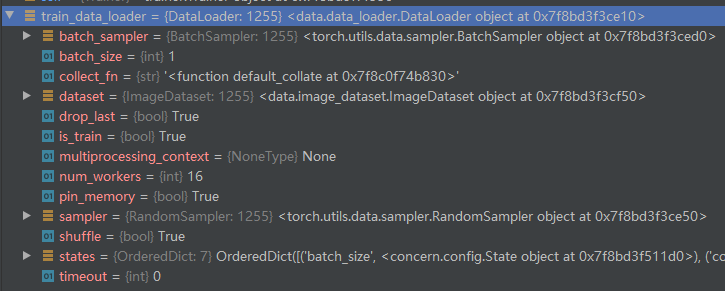
上面的属性、方法在pytorch的官方都可以找到相应的配置说明。
查看参考文献torch.utils.data
- batch_sampler批量采样器;
- dataset:是DataLoader类要加载的数据集;
- num_workers:是加载数据的子进程数量;
- pin_memory:是否固定内存;
- sampler是采样器;
- states是pytorch官网没有的东西,这里面配置了DataLoader类的重要基本参数。
数据加载类的states对象
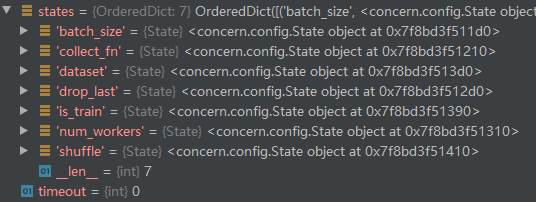
这里和上面的命名是很类似的,实际上是作者通过这个states对象集对数据加载类进行参数控制。
关于train部分代码的数据加载器,主要代码为:
class DataLoader(Configurable, torch.utils.data.DataLoader):
dataset = State()
batch_size = State(default=256)
num_workers = State(default=10)
is_train = State(default=True)
collect_fn = State(default=None)
drop_last = State(default=True)
shuffle = State()
def __init__(self, **kwargs):
self.load_all(**kwargs)
if self.collect_fn is None:
self.collect_fn = torch.utils.data.dataloader.default_collate
cmd = kwargs.get('cmd', {})
self.is_train = cmd['is_train']
if 'batch_size' in cmd:
self.batch_size = cmd['batch_size']
if self.shuffle is None:
self.shuffle = self.is_train
self.num_workers = cmd.get('num_workers', self.num_workers)
if cmd.get('distributed'):
sampler = DistributedSampler(
self.dataset, shuffle=self.shuffle,
num_replicas=cmd['num_gpus'])
batch_sampler = BatchSampler(
sampler, self.batch_size//cmd['num_gpus'], False)
torch.utils.data.DataLoader.__init__(
self, self.dataset, batch_sampler=batch_sampler,
num_workers=self.num_workers, pin_memory=False,
drop_last=self.drop_last, collate_fn=self.collect_fn,
worker_init_fn=default_worker_init_fn)
else:
torch.utils.data.DataLoader.__init__(
self, self.dataset,
batch_size=self.batch_size, num_workers=self.num_workers,
drop_last=self.drop_last, shuffle=self.shuffle,
pin_memory=True, collate_fn=self.collect_fn,
worker_init_fn=default_worker_init_fn)
self.collect_fn = str(self.collect_fn)
这里的dataset、batch_size、num_workers、is_train、collect_fn、drop_last、shuffle都是基本参数,大部分可以从命令行进行获取。所有参数都传给了torch.utils.data.DataLoader进行实例化。
基于上面的代码,在实例experiment的创建过程中、DataLoader的创建过程中,循环取值过程中,都没有发现所谓的数据增强。在调试代码过程中,我遇到报错:
Expected: /root/.pycharm_helpers/pydev/pydevd_attach_to_process/attach_linux_amd64.so to exist.
在网上搜索的方法仍然没有解决此问题,最后将num_workers设置为0,不开启数据加载的子线程。
数据展示:
# 获取数据,这里batch_size为1
image1 = batch["image"].squeeze().permute([1,2,0])
image1 = 255 * (image1 - image1.min()) / (image1.max() - image1.min())
cv.imwrite("/home/elfin/DB/test.png", image1.numpy())
gt = batch["gt"][0].permute([1,2,0]) * 255
通过这里的数据展示,我们发现batch里面的数据已经进行了数据增强!所以数据增强的逻辑,这个框架写在对dataloader循环的过着中了,关于具体是如何操作的,是不太好调试的!
由于这里大多是动态类,很多东西不是那么容易想明白,而数据增强的过程都包含在for batch in train_data_loader代码段中,所以后面我们主要根据这个循环取值所做的操作进行说明。在开始之前,我们先罗列yaml文件声明的处理措施:
- class: MakeICDARData
- class: MakeSegDetectionData
- class: MakeBorderMap
- class: NormalizeImage
- class: FilterKeys
DataLoader的worker_init_fn参数
那么在对train_data_loader进行循环之前,程序所作的初始化有:
-
default_worker_init_fn为numpy设置随机数;
为数据增强库imgaug设置随机数种子。
参考文献torch.utils.data中的 “4、IterableDataset类” 查看worker_init_fn的作用
2、__iter__方法
这是for循环会直接调用的方法,这个方法是pytorch进行的重构,进行此方法后,我这里是调用_SingleProcessDataLoaderIter方法。
这里你只要单步进行调试,代码一定会执行到:
data = [self.dataset[idx] for idx in possibly_batched_index]
注意这段代码的路径是:torch/utils/data/_utils/fetch.py(line: 44)
这段代码是fetch取数据的固定代码,所以,调试到这里就很关键了,因为这里是DataLoader与dataset直接相关的地方!
self.dataset[idx]是索引取值,这里直接回调用我们传入的dataset的__getitem__方法。
注意,这里的dataset一般是自定义的类型,我们的处理逻辑一般需要重构__getitem__方法进行实现。
下面介绍DB重构的__getitem__方法。
3、__getitem__方法
DB项目源码:
def __getitem__(self, index, retry=0):
if index >= self.num_samples:
index = index % self.num_samples
data = {}
image_path = self.image_paths[index]
img = cv2.imread(image_path, cv2.IMREAD_COLOR).astype('float32')
if self.is_training:
data['filename'] = image_path
data['data_id'] = image_path
else:
data['filename'] = image_path.split('/')[-1]
data['data_id'] = image_path.split('/')[-1]
data['image'] = img
target = self.targets[index]
data['lines'] = target
if self.processes is not None:
for data_process in self.processes:
data = data_process(data)
return data
getitem方法的关键就在于self.processes,这个字典记录了所有数据增强要进行的操作对象,如:
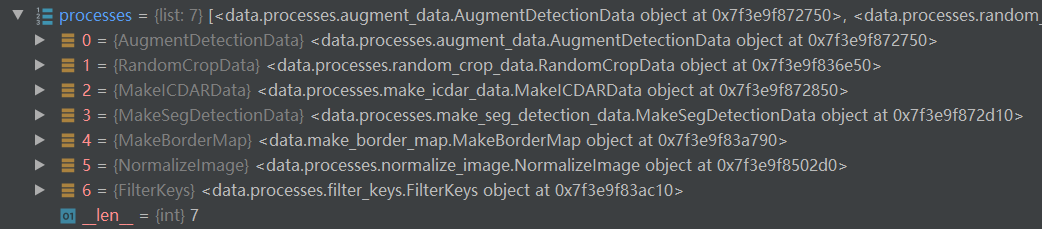
3.1 AugmentDetectionData
AugmentDetectionData是AugmentData的子类。
首先介绍下AugmentData的属性、方法:
- 属性:augmenter_args ---> 数据增强的参数。
- 方法:may_augment_annotation ---> 这里没有进行任何实现,实现见子类。
- 方法:resize_images ---> 使用cv2.resize将图像resize到目标大小。
- 方法:process ---> 对数据进行增强,详情参考后文。
process处理方法:
def process(self, data):
image = data['image']
aug = None
shape = image.shape
if self.augmenter:
aug = self.augmenter.to_deterministic()
if self.only_resize:
data['image'] = self.resize_image(image)
else:
data['image'] = aug.augment_image(image)
self.may_augment_annotation(aug, data, shape)
filename = data.get('filename', data.get('data_id', ''))
data.update(filename=filename, shape=shape[:2])
if not self.only_resize:
data['is_training'] = True
else:
data['is_training'] = False
return data
其中 self.augmenter = AugmenterBuilder().build(self.augmenter_args) ,
AugmenterBuilder().build可以理解为刷选数据增强参数的构造函数。
相应的类在实例化的时候就已经配置了augmenter属性,如:
augmenter_args = [
['Fliplr', 0.5],
{'cls': 'Affine', 'rotate': [-10, 10]},
['Resize', [0.5, 3.0]]
]
由augmenter_args得到:

注意,这里的augmenter参数是imgaug.augmenters.Sequential对象。
注:Sequential的参考文档见:https://blog.csdn.net/zong596568821xp/article/details/83105700
Sequential的主要作用就是将数据增强的操作序列化整合到一起,形成一个对象。它有一个random_order参数可以控制batch之间的数据增强顺序是否保持一致(一个batch内的操作顺序是一致的)。
如上面代码所示,self.augmenter是一个Sequential对象,如果有数据增强,则进行 to_deterministic 控制(参考文献:https://blog.csdn.net/limiyudianzi/article/details/86498416),这个方法主要是控制图像与标签一起变换。
数据增强做好之后,使用 self.may_augment_annotation(aug, data, shape) 进行增强后的标签信息生成。如下图所示,分别为增强前后的数据关键点(分割的多边形顶点):
原始的标签信息:

imgaug库的keypoints:
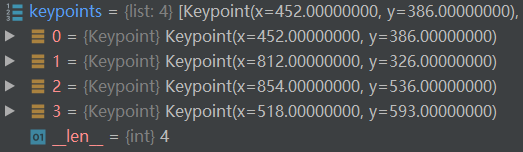
重要:关键点增强
keypoints = aug.augment_keypoints(
[imgaug.KeypointsOnImage(keypoints, shape=img_shape)]
)[0].keypoints
需要非常注意的是这里的aug是什么?aug实际上是self.augmenter.to_deterministic(),换句话说图像增强和关键点增强是同一个对象。
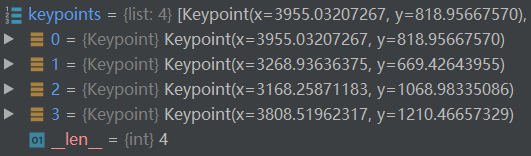
上图是增强后的图像关键点。(看起来好像有点不对劲,这里的数据集实际上好像有点不能一一对应,TODO:调整数据调试)
最后data字典重构了ploys字段,其中有:points字段是增强后的关键点;ignore字段是忽略的实例;text是区域内的文本。
至此,应该可以理解AugmentDetectionData做了什么操作,简单地说就是:
- 第一步:以0.5的概率翻转图像;
- 第二步:做仿射变换,旋转\(\left[ -10, 10 \right]\)度;
- 第三步:对预想resize调整;
这里Resize((0.5, 3.0))的参数是什么意思?这里的(0.5, 3.0)是均匀分布\(U(0.5, 3.0)\),由均匀分布随机产生一个缩放尺度参数。如果产生的随机数为1.0,那么就是原始尺寸,如果随机数为2.0,那么高和宽的size就会乘以2。
3.2 RandomCropData
RandomCropData是data.processes中的一个类,继承于DataProcess。
这里作者指定了size为 [640, 640],max_tries指定了裁剪的最大尝试次数,min_crop_side_ratio指定了最小裁剪率。
这里也是重构了process方法,所有的处理操作集中于这个方法的代码逻辑内。其中传入图像与图像所有实例的多边形分割给crop_area方法进行裁剪。此方法首先记录图像有实例的x轴区域、有实例的y轴区域。下面的代码即确保裁剪不会穿过实例:
# ensure the cropped area not across a text
h_axis = np.where(h_array == 0)[0]
w_axis = np.where(w_array == 0)[0]
h_axis、w_axis分别记录的是没有实例的坐标值。
接着使用self.split_regions对h_axis、w_axis寻找可以裁剪的h、w坐标值。
h_regions = self.split_regions(h_axis)
w_regions = self.split_regions(w_axis)
进行max_tries次裁剪尝试,每次尝试都会产生 xmin, xmax,ymin, ymax ,尝试的截至条件是:
xmax - xmin > self.min_crop_side_ratio * w and ymax - ymin > self.min_crop_side_ratio * h
即 xmax - xmin 表示裁剪区域,ymax - ymin表示纵轴的裁剪区域。循环直到尝试次数没了,或者上式成立。
那么 xmin, xmax,ymin, ymax 是如何得到的呢?
-
如果w_regions(可裁剪区域列表)的个数不大于1,则执行self.random_select(w_axis, w),其中w为图像的宽。
def random_select(self, axis, max_size): # 从axis(没有实例的连续坐标集)随机选择两个值 xx = np.random.choice(axis, size=2) xmin = np.min(xx) xmax = np.max(xx) xmin = np.clip(xmin, 0, max_size - 1) # 保证选择的数在 [0, max_size - 1]之间 xmax = np.clip(xmax, 0, max_size - 1) return xmin, xmax注意这里的axis是上面的h_axis、w_axis,这两个对象记录了没有实例的坐标点。
-
如果w_regions(可裁剪区域列表)的大于1(即不同实例在x轴的投影是离散的),则执行self.region_wise_random_select,其中w为图像的宽。
def region_wise_random_select(self, regions, max_size): # 选出两个无实例坐标集对应的index selected_index = list(np.random.choice(len(regions), 2)) # 记录两个无实例坐标集中选择的value selected_values = [] for index in selected_index: axis = regions[index] # 从一个可连续的无实例坐标集中选择一个坐标 xx = int(np.random.choice(axis, size=1)) selected_values.append(xx) xmin = min(selected_values) xmax = max(selected_values) # 此时返回的 [xmin, xmax] 至少有一个实例区域 return xmin, xmax
最后crop_area方法进行判断裁剪区域是否有实例,如果有就返回,没有就返回原图(0, 0, w, h)
crop_area方法最后返回的是裁剪区域的左上角、宽、高!
process方法:
def process(self, data):
img = data['image']
ori_img = img
ori_lines = data['polys']
all_care_polys = [line['points']
for line in data['polys'] if not line['ignore']]
crop_x, crop_y, crop_w, crop_h = self.crop_area(img, all_care_polys)
scale_w = self.size[0] / crop_w # self.size = [w, h]是当前增强模块期望的输出shape
scale_h = self.size[1] / crop_h # 放缩比例
# 选择小的尺寸,即小的scale对应的轴会填满self.size对应的目标轴,
# 另外一个轴占比大,但是注意占比大的乘以scale会让其比轴 的长度小,
# 即这个轴不能被填满,又即某个轴 乘0.8 恰好是目标轴的长度,那么 乘0.5 就比输出的轴长度小了
scale = min(scale_w, scale_h)
h = int(crop_h * scale)
w = int(crop_w * scale)
padimg = np.zeros(
(self.size[1], self.size[0], img.shape[2]), img.dtype)
# 在输出图像的左上角填充放缩后的图像
padimg[:h, :w] = cv2.resize(
img[crop_y:crop_y + crop_h, crop_x:crop_x + crop_w], (w, h))
img = padimg
# 至此img处理完毕,下面是label的处理
lines = []
for line in data['polys']:
# 图像相当于左上角删除了crop_x、crop_y,再乘以scale尺度,即实现了关键点的变换
poly = ((np.array(line['points']) -
(crop_x, crop_y)) * scale).tolist()
if not self.is_poly_outside_rect(poly, 0, 0, w, h):
lines.append({**line, 'points': poly})
data['polys'] = lines
if self.require_original_image:
data['image'] = ori_img
else:
data['image'] = img
data['lines'] = ori_lines
data['scale_w'] = scale
data['scale_h'] = scale
return data
注:关键点的坐标重构,因为我们取的是裁剪区域,所以新区域的坐标原点是\((crop_x, crop_y)\)。所以变换时,要先减去坐标原点,再进行放缩变换。
3.3 MakeICDARData
所有的数据增强继承了DataProcess就不用赘述了。这里DataProcess调用 _call_ 方法之后,就直接调用MakeICDARData的process方法了。
def process(self, data):
polygons = []
ignore_tags = []
# 所有实例的多边形标注
annotations = data['polys']
for annotation in annotations:
# 数据类型转换为numpy数据
polygons.append(np.array(annotation['points']))
# polygons.append(annotation['points'])
# 忽略的标识列表
ignore_tags.append(annotation['ignore'])
# 忽略的标识列表元素转化为0或1(原始为True/False)
ignore_tags = np.array(ignore_tags, dtype=np.uint8)
filename = data.get('filename', data['data_id'])
if self.debug:
self.draw_polygons(data['image'], polygons, ignore_tags)
shape = np.array(data['shape'])
return OrderedDict(image=data['image'],
polygons=polygons,
ignore_tags=ignore_tags,
shape=shape,
filename=filename,
is_training=data['is_training'])
整个处理流程下来数据没有发生任何变换,只是数据重构了,从字典变为OrderedDict;polygons从列表变为numpy的ndarray数据;shape也转为ndarray数据;ignore_tags是新生成的数据。
为了进行对比,这里我给出输入、输出的对象展示:
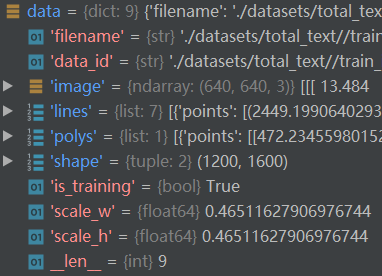
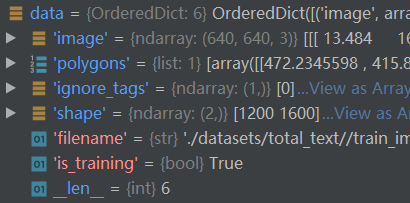
Note:
对于这种类型的数据可以设置这个数据处理策略;
注意我这里并没有说是数据增强,因为你对源数据的处理实际上都可以模块化地放进dataset里面,具体的处理模块是根据数据和模型进行选择。
3.4 MakeSegDetectionData
当前我们使用'./datasets/total_text//train_images/img1285.jpg'进行测试
这里直接观察process方法:
def process(self, data):
'''
需要的关键字: image, polygons, ignore_tags, filename
增加的关键字: mask
'''
image = data['image']
polygons = data['polygons']
ignore_tags = data['ignore_tags']
filename = data['filename']
h, w = image.shape[:2]
if data['is_training']:
polygons, ignore_tags = self.validate_polygons(
polygons, ignore_tags, h, w)
gt = np.zeros((1, h, w), dtype=np.float32)
mask = np.ones((h, w), dtype=np.float32)
for i in range(len(polygons)):
polygon = polygons[i]
height = max(polygon[:, 1]) - min(polygon[:, 1])
width = max(polygon[:, 0]) - min(polygon[:, 0])
# height = min(np.linalg.norm(polygon[0] - polygon[3]),
# np.linalg.norm(polygon[1] - polygon[2]))
# width = min(np.linalg.norm(polygon[0] - polygon[1]),
# np.linalg.norm(polygon[2] - polygon[3]))
if ignore_tags[i] or min(height, width) < self.min_text_size:
cv2.fillPoly(mask, polygon.astype(
np.int32)[np.newaxis, :, :], 0)
ignore_tags[i] = True
else:
polygon_shape = Polygon(polygon)
distance = polygon_shape.area * \
(1 - np.power(self.shrink_ratio, 2)) / polygon_shape.length
subject = [tuple(l) for l in polygons[i]]
padding = pyclipper.PyclipperOffset()
padding.AddPath(subject, pyclipper.JT_ROUND,
pyclipper.ET_CLOSEDPOLYGON)
shrinked = padding.Execute(-distance)
if shrinked == []:
cv2.fillPoly(mask, polygon.astype(
np.int32)[np.newaxis, :, :], 0)
ignore_tags[i] = True
continue
shrinked = np.array(shrinked[0]).reshape(-1, 2)
cv2.fillPoly(gt[0], [shrinked.astype(np.int32)], 1)
if filename is None:
filename = ''
data.update(image=image,
polygons=polygons,
gt=gt, mask=mask, filename=filename)
return data
代码解读:
-
self.validate_polygons:如果是训练,我们必须要验证多边形标注是否满足要求,这个函数就是干这个事情的。
def validate_polygons(self, polygons, ignore_tags, h, w): ''' polygons (numpy.array, required): of shape (num_instances, num_points, 2) ''' if len(polygons) == 0: return polygons, ignore_tags assert len(polygons) == len(ignore_tags) # 保证多边形的高、宽坐标在图像范围内 for polygon in polygons: polygon[:, 0] = np.clip(polygon[:, 0], 0, w - 1) polygon[:, 1] = np.clip(polygon[:, 1], 0, h - 1) for i in range(len(polygons)): area = self.polygon_area(polygons[i]) if abs(area) < 1: ignore_tags[i] = True if area > 0: polygons[i] = polygons[i][::-1, :] return polygons, ignore_tags这里的self.polygon_area为:
def polygon_area(self, polygon): """polygon为一个实例的多边形标注""" edge = 0 # 对实例标注的每个坐标点进行操作 for i in range(polygon.shape[0]): next_index = (i + 1) % polygon.shape[0] # 实际就是i+1 # 这是求多边形的面积公式 edge += (polygon[next_index, 0] - polygon[i, 0]) * (polygon[next_index, 1] - polygon[i, 1]) return edge / 2.注:关于公式的推导可以参考:https://en.wikipedia.org/wiki/Shoelace_formula
当面积绝对值小于1,则忽略这个实例;若面积大于0,就将所有的坐标逆序!
-
验证完多边形之后,进行gt:缩放区域label生成;gt_mask生成。下面以代码块进行说明
for i in range(len(polygons)): # 获取地i个标注实例及其外接矩形的宽、高 polygon = polygons[i] height = max(polygon[:, 1]) - min(polygon[:, 1]) width = max(polygon[:, 0]) - min(polygon[:, 0]) if ignore_tags[i] or min(height, width) < self.min_text_size: # 如果当前实例不忽略,且高、宽都小于最小的文本尺寸,则执行当前代码块 # 向gt_mask对应的实例区域插入值0(默认全是1),使用np.newaxis增加维度是因为, # fillPoly可以同时绘制多个多边形,第一个维度即为实例的维度 cv2.fillPoly(mask, polygon.astype( np.int32)[np.newaxis, :, :], 0) ignore_tags[i] = True else: # 实例化一个Polygon对象(shapely.geometry.Polygon) polygon_shape = Polygon(polygon) # 收缩偏移量:面积 * (1-收缩率**2)/ 周长 distance = polygon_shape.area * \ (1 - np.power(self.shrink_ratio, 2)) / polygon_shape.length # subject记录多边形的顶点坐标,坐标是以元组给出 subject = [tuple(l) for l in polygons[i]] padding = pyclipper.PyclipperOffset() padding.AddPath(subject, pyclipper.JT_ROUND, pyclipper.ET_CLOSEDPOLYGON) shrinked = padding.Execute(-distance) if shrinked == []: # 没有内缩就将实例区域绘制到mask上 cv2.fillPoly(mask, polygon.astype( np.int32)[np.newaxis, :, :], 0) ignore_tags[i] = True continue shrinked = np.array(shrinked[0]).reshape(-1, 2) # 获取内缩标注gt cv2.fillPoly(gt[0], [shrinked.astype(np.int32)], 1)注: pyclipper是一个对c++封装的python库,主要功能是裁剪。
-
传入的数据:
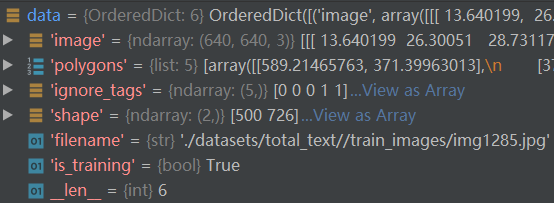
-
基于上述操作后,再对数据进行重构,得到如下的数据:
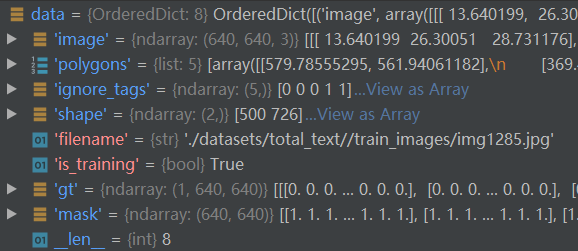
总结:什么是gt_mask?
gt为内缩label,gt_mask是没有内缩实例的实例区域mask;
下面是原图、gt、gt_mask的对比:
-
原始图像
elfin_fig = 255 * (data["image"] - data["image"].min()) / (data["image"].max() - data["image"].min()) cv.imwrite("/home/elfin/DB/elfin_fig.png", elfin_fig) gt = batch["gt"][0].permute([1,2,0]) * 255
-
gt图像
gt_fig = 255 * data["gt"].reshape([640, 640, 1]) cv.imwrite("/home/elfin/DB/gt_fig.png", gt_fig)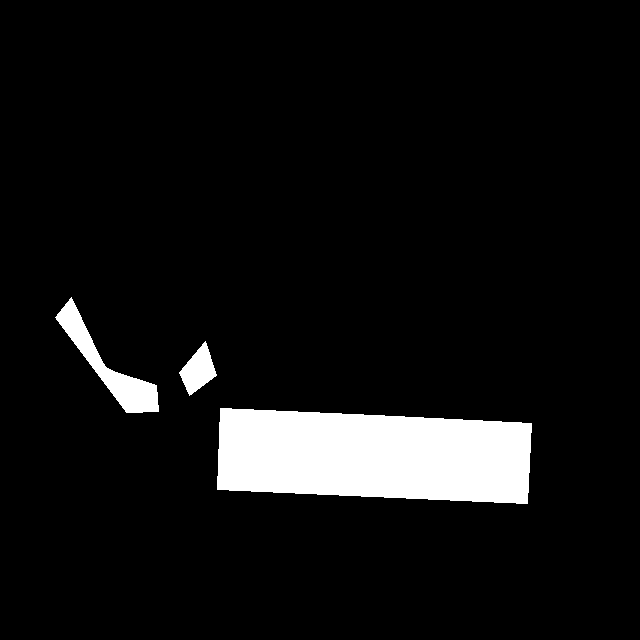 渲染原图后:
渲染原图后:
这里明显可以观察到gt是实例区域的内缩。
-
gt_mask图像

这里可以看出gt_mask标注的是未内缩的实例区域,这里标识的是路标左右两边的文字区域
3.5 MakeBorderMap
如其名,这个处理模块是实例的边界生成,最后会增加 thresh_map, thresh_mask字段。注意上一步我们生成了内缩的mask。
使用使用实例 + ()调用时,实际上使用的是类的构造函数__call__方法。那么前面我们为什么要分析process方法呢?因为构造函数是继承的父类的构造函数,默认就只调用process方法。
def __call__(self, data, *args, **kwargs):
image = data['image']
polygons = data['polygons']
# 记录了忽略的实例,如接上一节,ignore_tags = [0,0,0,1,1],
# 后面两个实例进行忽略,因为他们在gt上面没有内缩
ignore_tags = data['ignore_tags']
canvas = np.zeros(image.shape[:2], dtype=np.float32)
mask = np.zeros(image.shape[:2], dtype=np.float32)
for i in range(len(polygons)):
# ignore_tags[i] 一个实例的所有多边形顶点
if ignore_tags[i]:
continue
# 对有内缩的实例进行外扩mask生成
self.draw_border_map(polygons[i], canvas, mask=mask)
# self.thresh_max - self.thresh_min是允许的阈值范围,将所有点的阈值放缩到这个范围内
# 注意canvas只记录了扩张实例的外接矩形的区域的点到外扩边界的距离;默认为0,修正后为self.thresh_min
canvas = canvas * (self.thresh_max - self.thresh_min) + self.thresh_min
data['thresh_map'] = canvas
data['thresh_mask'] = mask
return data
self.draw_border_map是生成thresh_map和thresh_mask的关键函数,当然其代码也不是一眼能明白的:
def draw_border_map(self, polygon, canvas, mask):
polygon = np.array(polygon)
assert polygon.ndim == 2
assert polygon.shape[1] == 2
polygon_shape = Polygon(polygon)
distance = polygon_shape.area * \
(1 - np.power(self.shrink_ratio, 2)) / polygon_shape.length
subject = [tuple(l) for l in polygon]
padding = pyclipper.PyclipperOffset()
padding.AddPath(subject, pyclipper.JT_ROUND,
pyclipper.ET_CLOSEDPOLYGON)
padded_polygon = np.array(padding.Execute(distance)[0])
# 使用mask记录内缩实例对应的外扩区域
cv2.fillPoly(mask, [padded_polygon.astype(np.int32)], 1.0)
# 计算当前实例的外扩的取值范围
xmin = padded_polygon[:, 0].min()
xmax = padded_polygon[:, 0].max()
ymin = padded_polygon[:, 1].min()
ymax = padded_polygon[:, 1].max()
width = xmax - xmin + 1
height = ymax - ymin + 1
# 重置多边形的顶点( 原点 为扩张后的实例左上角的坐标)
polygon[:, 0] = polygon[:, 0] - xmin
polygon[:, 1] = polygon[:, 1] - ymin
# numpy的广播机制,可以参考https://www.cnblogs.com/dan-baishucaizi/p/9389338.html
xs = np.broadcast_to(
np.linspace(0, width - 1, num=width).reshape(1, width), (height, width))
ys = np.broadcast_to(
np.linspace(0, height - 1, num=height).reshape(height, 1), (height, width))
# 距离特征图
distance_map = np.zeros(
(polygon.shape[0], height, width), dtype=np.float32)
for i in range(polygon.shape[0]):
# i, j 搭配组成循环取值索引,分别计算所有点到第i个线段(第i,j个顶点组成的线段)的距离
j = (i + 1) % polygon.shape[0]
absolute_distance = self.distance(xs, ys, polygon[i], polygon[j])
distance_map[i] = np.clip(absolute_distance / distance, 0, 1)
# 计算每个点到实例的最小距离
distance_map = distance_map.min(axis=0)
# 为保证新生成的扩张实例位于图像范围内,生成验证范围
xmin_valid = min(max(0, xmin), canvas.shape[1] - 1)
xmax_valid = min(max(0, xmax), canvas.shape[1] - 1)
ymin_valid = min(max(0, ymin), canvas.shape[0] - 1)
ymax_valid = min(max(0, ymax), canvas.shape[0] - 1)
# distance_map.shape为 扩张实例的外界矩形的shape;
# 下面的np.fmax是在生成的distance_map与canvas对应区域取较大的值
canvas[ymin_valid:ymax_valid + 1, xmin_valid:xmax_valid + 1] = np.fmax(
1 - distance_map[
ymin_valid - ymin:ymax_valid - ymax + height,
xmin_valid - xmin:xmax_valid - xmax + width],
canvas[ymin_valid:ymax_valid + 1, xmin_valid:xmax_valid + 1])
注意,这里的形参会改变实参,即:即使我们没有返回mask、canvas,但是我们在draw_border_map的修改会同步到__call__方法中。draw_border_map总结下来就是:
- 根据DB论文的距离计算公式,获取扩张的距离,将多边形顶点进行外扩;
- 将外扩的顶点渲染外扩的掩码到mask上;
- 使用numpy广播机制生成实例(扩张实例的外接矩形区域)对应的坐标特征图;
- 初始化距离特征图,并计算每个点到多边形每个边 (原始多边形,非外扩) 的距离,取最小值,得到最后的实例距离特征图;
- 更新canvas对应此实例扩张区域的值,取
1 - distance_map与原始canvas对应此实例扩张区域的值中的较大的那个。注意这里是每个元素进行比较返回。
下面我们来看生成的 thresh_map 和 thresh_mask :
-
原始图像
elfin_fig2 = 255 * (data["image"] - data["image"].min()) / (data["image"].max() - data["image"].min()) cv.imwrite("/home/elfin/DB/elfin_fig2.png", elfin_fig2)
-
thresh_map 阈值特征图
注意这里并不是基于外扩和内缩生成!
cv.imwrite("/home/elfin/DB/thresh_map.png", data['thresh_map']*255)
-
thresh_mask 阈值mask:外扩掩码
cv.imwrite("/home/elfin/DB/thresh_mask.png", data['thresh_mask']*255)
3.6 NormalizeImage
这个类比较简单,这里我们可以看源码:
class NormalizeImage(DataProcess):
RGB_MEAN = np.array([122.67891434, 116.66876762, 104.00698793])
def process(self, data):
assert 'image' in data, '`image` in data is required by this process'
image = data['image']
image -= self.RGB_MEAN
image /= 255.
# 将数据重构为shape为 [channel, h, w]
image = torch.from_numpy(image).permute(2, 0, 1).float()
data['image'] = image
return data
@classmethod
def restore(self, image):
image = image.permute(1, 2, 0).to('cpu').numpy()
image = image * 255.
image += self.RGB_MEAN
image = image.astype(np.uint8)
return image
训练的时候我们使用process方法,后期可以使用restore方法重构原始图像。
@classmethod修饰的方法不用实例化即可使用,如后期我们可以直接使用 NormalizeImage.restore(image) 进行图片的重构。
3.7 FilterKeys
这个类用于检查最后生成的数据是否所有的关键字都有:
class FilterKeys(DataProcess):
required = State(default=[])
superfluous = State(default=[])
def __init__(self, **kwargs):
super().__init__(self, **kwargs)
self.required_keys = set(self.required)
self.superfluous_keys = set(self.superfluous)
if len(self.required_keys) > 0 and len(self.superfluous_keys) > 0:
raise ValueError(
'required_keys and superfluous_keys can not be specified at the same time.')
def process(self, data):
for key in self.required:
assert key in data, '%s is required in data' % key
superfluous = self.superfluous_keys
if len(superfluous) == 0:
for key in data.keys():
if key not in self.required_keys:
superfluous.add(key)
for key in superfluous:
del data[key]
return data
当前类可以实现两种对数据的检查方式:
- 第一种:指定required;
- 第二种:指定要删除的关键字。
经过这些流程,DataLoader已经将传入的图片、label路径转换为具体的训练数据了。
4、总结
数据加载器的调用逻辑实现了数据增强、数据标签生成一系列操作。主要的数据增强发生在[3.1](#3.1 AugmentDetectionData)、[3.2](#3.2 RandomCropData);[3.4](#3.4 MakeSegDetectionData)生成了内缩标签gt、实例标签gt_mask;[3.5](#3.5 MakeBorderMap)生成了外扩标签thresh_mask和实例边界thresh_map。
关于论文的介绍可参考:https://www.cnblogs.com/dan-baishucaizi/p/14378202.html
完
