
torch.utils.data
torch的DataLoader
作者:elfin 资料来源:pytorch1.6官网
- 1、DataLoader简介
- 2、DataLoader类
- 3、Dataset类
- 4、IterableDataset类
- 5、其他类、方法
- 5.1 TensorDataset类
- 5.2 ConcatDataset类
- 5.3 ChainDataset
- 5.4 Subset类
- 5.5 get_worker_info方法
- 5.6 torch.utils.data.random_split(dataset, lengths, generator=<torch._C.Generator object>)
- 5.7 torch.utils.data.Sampler(data_source)
- 5.8 torch.utils.data.SequentialSampler(data_source)
- 5.9 RandomSampler(data_source, replacement=False, num_samples=None, generator=None)
- 5.10 torch.utils.data.SubsetRandomSampler(indices, generator=None)
- 5.11 torch.utils.data.WeightedRandomSampler(weights, num_samples, replacement=True, generator=None)
- 5.12 BatchSampler(sampler, batch_size, drop_last)
- 5.13 DistributedSampler(dataset, num_replicas=None, rank=None, shuffle=True, seed=0)
1、DataLoader简介
torch.utils.data.DataLoader 类是PyTorch数据加载实用程序的核心。它表示可在数据集上的Python迭代器,并支持
- 映射风格、迭代风格的数据集;
- 自定义数据加载顺序;
- 自动batch分配;
- 单进程和多进程数据加载;>
- 内存自动分配。
DataLoader的构造函数参数配置 :
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None)
关于上面的形参到底是什么?下文将意义介绍!
1.1 dataset类型
DataLoader 构造函数最重要的参数是dataset,它指示要从中加载数据的数据集对象。PyTorch支持两种不同类型的数据集:
-
map-style datasets
映射样式的数据集是一种实现
__getitem__()和__len__()协议的数据集,它表示从(可能是非整数)索引/关键字到数据样本的映射。 例如,当使用dataset[idx]访问这样的数据集时,可以从磁盘上的文件夹中读取第idx-th 图像及其对应的标签。注意我们使用索引取值的时候才加载了数据,关于映射和迭代数据集的差异见https://blog.csdn.net/liudaohui11/article/details/107772849
-
iterable-style datasets.
可迭代样式的数据集是
IterableDataset实现__iter__()协议的子类的实例,并且表示数据样本上的可迭代形式。这种类型的数据集特别适用于随机读取价格昂贵甚至不可能的情况,并且批处理大小取决于所获取的数据。 例如,这样的数据集在调用
iter(dataset)时,可以返回从数据库,远程服务器甚至实时生成的日志中读取的数据流。
1.2 数据加载顺序和 Sampler
对于可迭代样式的数据集,数据加载顺序完全由用户定义的可迭代样式控制。这样可以更轻松地实现块读取和动态批处理大小(例如,通过每次生成一个批处理的样本)。
对于map-style的数据,torch.utils.data.Sampler 类用于指定数据加载中使用的索引/键的顺序。它们代表数据集索引上的可迭代对象。例如,在SGD中,a Sampler可以随机排列一系列索引并一次生成每个索引,或者为小批量SGD生成少量索引。
shuffle参数可以指定先打乱数据的顺序再进行采样;当然用户可以自定义一个sampler类(torch的 sampler类的子类),该对象每次产生下一个要提取的索引/键。
可以一次Sampler生成一个批次索引列表的作为batch_sampler参数传递。也可以通过batch_size和 drop_last参数启用自动批处理。
1.3 批量加载与非批量加载数据
DataLoad支持使用参数batch_size, drop_last, and batch_sampler进行数据的批量采样。
1.3.1 自动分批量(默认)
这是最常见的情况,对应于获取一个数据的小批量并将其整理为批处理的样本,即,包含一个维度为batch的张量(通常是第一维)。
如果batch_size(default 1)不是None,则数据加载器将生成批处理的样本,而不是单个样本。batch_size和 drop_last参数用于指定数据加载器如何获取批次的数据集密钥。对于map-style的数据集,用户可以选择指定batch_sampler,从而一次生成一个键列表。
Tips:
- 在
batch_size和drop_last主要是用于构建从sampler、batch_sampler。map-style的数据集,sampler要么由用户提供,要么基于shuffle参数构造。对于可迭代样式的数据集,sampler是一个虚拟的无限数据集 。 - 当通过多重处理从可迭代样式的数据集中获取 数据时 ,该 参数将删除每个工作人员的数据集副本的最后一个非完整批次。
drop_last
使用来自采样器的索引获取样本列表后,作为collate_fn参数传递的函数用于将样本列表整理为批次。
在这种情况下,从map-style数据集加载大致等效于:
for indices in batch_sampler:
yield collate_fn([dataset[i] for i in indices])
从可迭代样式数据集加载大致等效于:
dataset_iter = iter(dataset)
for indices in batch_sampler:
yield collate_fn([next(dataset_iter) for _ in indices])
# 注意哦,这里实际上batch_sampler没什么卵用
自定义collate_fn可用于自定义排序规则,例如,将顺序数据填充到批处理的最大长度。
1.3.2 禁止自动批处理
在某些情况下,用户可能希望以数据集代码手动处理批处理,或仅加载单个样品。例如,直接加载批处理的数据(例如,从数据库中批量读取或读取连续的内存块)可能会比较高效,或者批处理大小取决于数据,或者该程序设计为可以处理单个样本。在这些情况下,最好不要使用自动批处理(collate_fn用于整理样本的位置),而应让数据加载器直接返回dataset对象的每个成员。
当batch_size和batch_sampler均为None(默认值为batch_sampler已经None)时,将禁用自动批处理。从所获得的每个样本dataset都将作为collate_fn参数传递的函数进行处理。
禁用自动批处理后,默认设置collate_fn将简单地将NumPy数组转换为PyTorch张量,并使其他所有内容保持不变。
在这种情况下,从map-style数据集加载大致等效于:
for index in sampler:
yield collate_fn(dataset[index])
从可迭代样式数据集加载大致等效于:
for data in iter(dataset):
yield collate_fn(data)
1.3.3 collate_fn的使用
collate_fn启用或禁用自动批处理时的使用略有不同。
当自动batching被禁用,collate_fn每个单独的数据样本都会被调用,并且输出是从数据加载器迭代器中产生的。在这种情况下,默认值collate_fn只是简单地转换 PyTorch 张量中的 NumPy 数组。
当自动batching被允许,collate_fn每次都会使用数据样本列表调用。预计将输入样本整理成一个批次,以便从数据加载器迭代器中产生。本节的其余部分描述collate_fn了这种情况下默认行为。
例如,如果每个数据样本都包含一个3通道图像和一个整型标签,即数据集的每个元素都返回一个元组(image, class_index) ,则collate_fn默认将这些元组的列表整理为批处理图像张量和一个批处理类标签张量。特别是,默认值具有以下属性:
- 它总是加一个新维度作为batch dim;
- 它自动转换numpy数据和python数值为pytorch张量;
- 它保留了数据结构,例如,如果每个样本都是一个字典,则它输出具有相同键值但批处理过的张量作为值的词典(或如果值不能转换为张量则列出)。与
lists,tuples,namedtuples等相同。
用户可以使用自定义collate_fn来实现自定义批处理,例如,沿着除第一个维度之外的其他维度进行校对,各种长度的填充序列,或添加对自定义数据类型的支持。
1.4 单进程、多进程数据加载
DataLoader默认情况下,使用单进程数据加载。
在Python进程中, 全局解释器锁(GIL) 防止跨线程真正地完全并行化Python代码。为了避免在加载数据时阻塞计算代码,PyTorch提供了一个简单的开关,只需将参数设置num_workers 为正整数即可执行多进程数据加载。
1.4.1 单进程数据加载
在这种模式下,数据获取是在与DataLoader初始化相同的过程中完成的 。因此,数据加载可能会阻塞计算。但是,当用于在进程之间共享数据的资源(例如共享内存,文件描述符)有限或整个数据集很小并且可以完全加载到内存中时,此模式可能是首选。此外,单进程加载通常显示出更具可读性的错误跟踪,因此对于调试很有用。
1.4.2 多进程数据加载
将参数设置num_workers为正整数将打开具有指定数量的加载程序工作进程的多进程数据加载。
在这种模式下,每次DataLoader 创建迭代器时(例如,当您调用时enumerate(dataloader)),都会 创建num_workers个工作进程。在这一点上,dataset, collate_fn,并worker_init_fn传递给每一个worker,在那里它们被用来初始化,并获取数据。这意味着数据集访问及其内部IO转换(包括collate_fn)在工作进程中运行。
torch.utils.data.get_worker_info()在工作进程中返回各种有用的信息(包括工作ID,数据集副本,初始种子等),并在主进程中返回None。用户可以在数据集代码中使用此功能和/或worker_init_fn单独配置每个数据集副本,并确定代码是否在工作进程中运行。例如,这在分片数据集时特别有用。
对于map-style的数据集,主要过程:使用生成索引 sampler并将其发送给worker。因此,任何shuffle都是在主进程中完成的,该过程通过为索引分配索引来引导加载。
对于可迭代样式的数据集,由于每个工作进程都获得dataset对象的副本,因此幼稚的多进程加载通常会导致数据重复。用户可以使用torch.utils.data.get_worker_info()和/或 worker_init_fn独立配置每个副本。(有关IterableDataset如何实现此操作的信息,请参阅 文档。出于类似的原因,在多进程加载中,drop_last 参数删除每个工作程序的可迭代样式数据集副本的最后一个非完整批次。
一旦迭代结束或迭代器被垃圾回收,worker将被关闭。
平台特定的行为
由于工作程序依赖于Python multiprocessing,因此与Unix相比,Windows上的工作程序启动行为有所不同。
- 在Unix上,
fork()是默认的multiprocessing启动方法。使用fork(),子进程通常可以dataset直接通过克隆的地址空间访问和Python参数函数。 - 在Windows上,
spawn()是默认的multiprocessing启动方法。使用spawn(),将启动另一个解释器,该解释器运行主脚本,随后是内部工作程序函数,该函数通过序列化接收dataset,collate_fn以及其他参数pickle。
这种单独的序列化意味着您应该采取两个步骤来确保在使用多进程数据加载时与Windows兼容:
- 将您的大多数主脚本代码包装在
if __name__ == '__main__':块中,以确保在启动每个工作进程时,该脚本不会再次运行(很可能会产生错误)。您可以 在此处放置数据集和DataLoader实例创建逻辑,因为它不需要在worker中重新执行。 - 确保任何自定义
collate_fn,worker_init_fn或dataset代码被声明为__main__的顶层定义。这样可以确保它们在工作进程中可用。(这是必需的,因为将函数仅作为引用进行腌制,而不能将其腌制为引用bytecode。)
多进程数据加载中的随机性:
默认情况下,每个worker的PyTorch种子设置为base_seed + worker_id,这是主进程使用其RNG(随机数生成器)生成的长整数(因此,强制使用RNG状态)。但是,在初始化工作程序(例如NumPy)时,可能会复制其他库的种子,从而使每个工作程序返回相同的随机数。
在worker_init_fn,您可以使用torch.utils.data.get_worker_info().seed 或者torch.initial_seed()设置seed,在数据加载之前,使用它可对其他库设置seed。
1.5 内存固定
当数据源锁定内存时,数据传输到GPU要快很多。如何多顶内存缓冲区,可以参考 Use pinned memory buffers 。
对于数据加载,在Dataloader中设置pin_memory=True可以自动获取锁内存的Tensors,从而更快地将数据传输到支持CUDA的GPU。
默认内存锁定逻辑仅识别张量以及包含张量的映射和迭代。默认情况下,如果固定逻辑看到一个自定义类型的批处理(如果您有一个collate_fn返回自定义批处理类型的批处理,则会发生这种情况),或者如果您的批处理的每个元素都是自定义类型,则固定逻辑将无法识别它们,并且它将返回该批次(或那些元素)而不固定内存。要为自定义批处理或数据类型启用内存锁定,pin_memory()请在自定义类型上定义一个方法。
案例:
# 批量采样类
class SimpleCustomBatch:
def __init__(self, data):
transposed_data = list(zip(*data))
self.inp = torch.stack(transposed_data[0], 0)
self.tgt = torch.stack(transposed_data[1], 0)
# custom memory pinning method on custom type
def pin_memory(self):
self.inp = self.inp.pin_memory()
self.tgt = self.tgt.pin_memory()
return self
def collate_wrapper(batch):
return SimpleCustomBatch(batch)
inps = torch.arange(10 * 5, dtype=torch.float32).view(10, 5)
tgts = torch.arange(10 * 5, dtype=torch.float32).view(10, 5)
dataset = TensorDataset(inps, tgts)
loader = DataLoader(dataset, batch_size=2, collate_fn=collate_wrapper,
pin_memory=True)
for batch_ndx, sample in enumerate(loader):
print(sample.inp.is_pinned())
print(sample.tgt.is_pinned())
2、DataLoader类
class torch.utils.data.DataLoader(
dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None,
num_workers=0, collate_fn=None, pin_memory=False, drop_last=False,
timeout=0, worker_init_fn=None, multiprocessing_context=None,
generator=None)
DataLoader:在给定的数据集上提供可迭代的组合数据集和采样器。
该DataLoader同时支持map-style和迭代式的数据集与单或多进程加载,支持自定义加载顺序、自动batching、内存锁定。
参数:
- dataset (Dataset) – 从中加载数据的数据集;
- batch_size (int, optional) – 每个批次的数量,默认为1;
- shuffle (bool, optional) – 是否打乱数据进行采样,默认不打乱;
- sampler (Sampler or Iterable, optional) – 定义从数据集中抽取样本的策略。sampler可以是任何基于
Iterable与__len__的实现。如果指定,则shuffle不得指定; - batch_sampler (Sampler or Iterable, optional) – 类似于采样器,只是每次只返回一个batch的indices。一般与
batch_size,shuffle,sampler, anddrop_last互斥; - num_workers(int,optional)–要用于数据加载的子进程数。
0表示将在主进程中加载数据。(默认值:0); - collate_fn(callable ,optional)–合并样本列表,以形成张量的小批量。在从map-style 数据集中使用批量加载时使用;
- pin_memory(bool,可选)–如果为
True,则数据加载器在将张量返回之前将其复制到CUDA固定的内存中。如果您的数据元素是自定义类型,或者您collate_fn返回的是自定义类型的批次,请参见下面的示例。(张量默认会固定) - drop_last(bool,可选)–设置为
True删除最后一个不完整的批次,如果该数据集大小不能被该批次大小整除。如果False并且数据集的大小不能被批次大小整除,那么最后一个批次将比batch_size小。(默认值:False) - timeout (numeric, optional) –如果为正,则为worker收集批次的超时值。应始终为非负数。(默认值:
0) - worker_init_fn (callable, optional) –如果不是
None,在随机数种子设置后、数据加载前,每个子进程将会调用并输入进程编号id,id属于[0, num_workers - 1]。IterableDataset类中有详细说明
下面是一个dataset被DataLoader调用的一个简单案例,这里的数据集已经单独测试通过,没有问题,可以通过map-style的形式处理数据,但是我们实例化加载器之后,使用却报错了!这是为什么呢?
data = PubLayNetDataSet(cfg={"data": {
"data_root": "/home/VanSegInstance/publaynet/images",
"test": "/test/",
"test_json": "/test.json"
}}, mode="test")
# DataLoader测试
loader = DataLoader(dataset=data, batch_size=4, shuffle=True, num_workers=2,drop_last=True)
loader_item = iter(loader)
images, labels = loader_item.__next__()
print(type(images), type(labels))
print(images.shape())
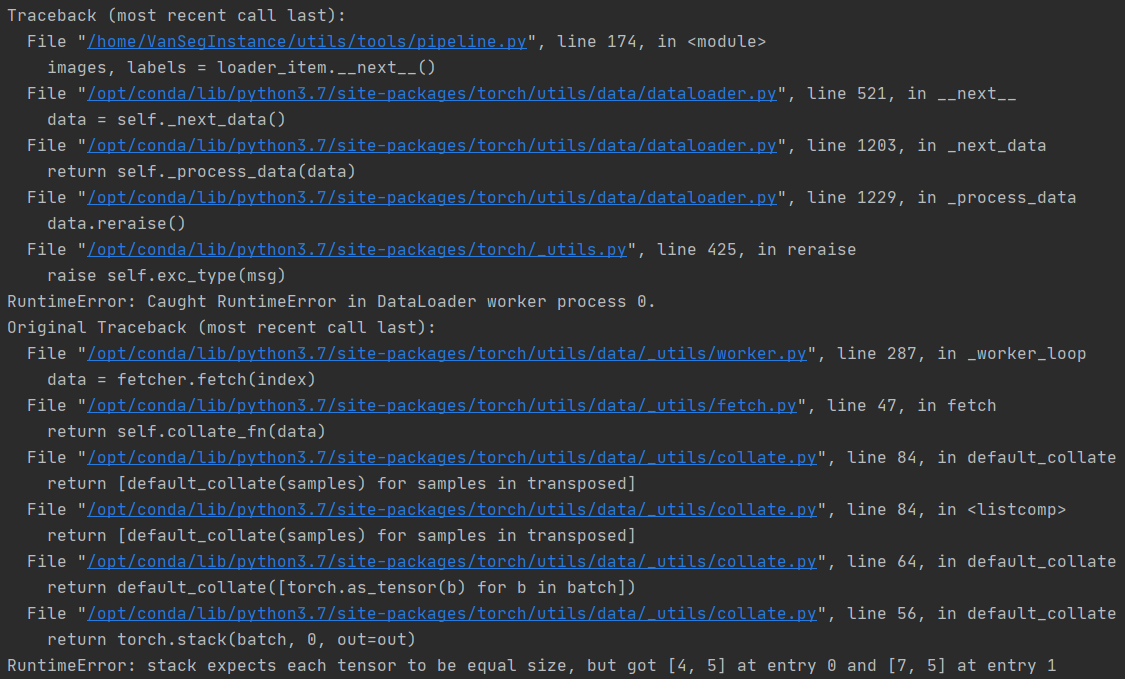
如图所示:根据报错轨迹我们可以简单确认如下几件事:
- 打包数据时,实体0的形状为[4, 5],而实体1的形状为[7, 5],size不一样导致数据合并报错;
- DataLoader报错是在取值时报错,即
images, labels = loader_item.__next__()这个时候报错 - 用
next取数据时再根据索引取数据,这意味着所有取数据、处理数据的逻辑都是在loader中触发 - collate_fn最后会被调用,以聚合每个样本及其标签数据,但是这些数据必须具有相同的size
根据自己写的代码,我们很快就能知道这是由于不同图片中实例的数量不一致导致的,那么我们怎么debug呢?
解决方案:
这里我们可以借助1.3.3节所介绍的collate_fn函数实现打包数据的操作。最简单的就是将标签顺序地存入列表或者字典,这样就可以避免数据维度不一致代理的打包问题。
- 数据Dataset参考下一章的案例;
- 定义一个collate_fn函数
def collate_fn(batch): """ 对采样的批量结果(list)进行合并 :param batch: list, 每个元素是一个Dataset.__getitem__返回的元组 :return: """ collate_images = torch.stack([torch.tensor(b[0], dtype=torch.float32) for b in batch]) length = len(batch) collate_labels = {b: torch.tensor(batch[b][1], dtype=torch.float32) for b in range(length)} # shape: [B, H, W, C] --> [B, C, H, W] collate_images = collate_images.permute([0, 3, 1, 2]) return collate_images, collate_labels
这样loader就可以正常返回我们需要的数据了!
3、Dataset类
DataLoader类中的所有dataset的抽象类。
代表从键到数据样本的映射的所有数据集都应将其子类化。所有子类都应该覆盖__getitem__()方法,支持获取给定键的数据样本。子类也可以选择覆盖 __len__(),这有过许多Sampler实现和 DataLoader的默认选项来返回望通大小的数据集。
Note:
DataLoader 默认构建整形index的采样器。要使map-style风格数据集使用非整形索引,则需要提供自定义采样器。
下面是一个Dataset的实际使用案例:
class PubLayNetDataSet(Dataset):
def __init__(self, cfg, mode="train"):
"""
配置数据集的基础信息
:param cfg: dict
:param mode: 控制使用train、valid、test数据集
"""
super(PubLayNetDataSet, self).__init__()
self.Img_Dir = cfg["data"]["data_root"] + cfg["data"][mode]
self.Ana_Dir = cfg["data"]["data_root"] + cfg["data"][mode + "_json"]
self.images = os.listdir(self.Img_Dir) # 图像路径的载入顺序是一致的,打乱需要在DataLoader阶段处理
self.labels = self.get_json()
self.Iaa_Seq = get_aug_pipeline()
def get_json(self):
with open(self.Ana_Dir, "r+", encoding="utf-8") as f:
label_json = json.load(f)
f.close()
return label_json
def __getitem__(self, item):
img = np.array(PIL.Image.open(self.Img_Dir+self.images[item]))
label = self.labels[self.images[item]]
bbs = BoundingBoxesOnImage(
[BoundingBox(box[0], box[1], box[0] + box[2],
box[1] + box[3], box[4]) for box in label],
shape=img.shape[:2]
)
# 开始数据增强, 增强后的bbox是 $左上角 $右下角 坐标
img, label = self.Iaa_Seq(image=img, bounding_boxes=bbs)
# 测试图片渲染效果
# img2 = label.draw_on_image(img, size=2, color=(0, 255, 0))
# plt.imshow(img2)
# plt.show()
label = np.array([
[label.bounding_boxes[i].x1, label.bounding_boxes[i].y1, label.bounding_boxes[i].x2,
label.bounding_boxes[i].y2, label.bounding_boxes[i].label] for i in range(len(label.bounding_boxes))
])
return img, label
def __len__(self):
return len(self.images)
4、IterableDataset类
它的所有子类,应该重构_iter_()方法,以实现返回数据的迭代器。
当子类与DataLoader一起使用时,数据集中的每个item都将由DataLoader 迭代器产生。当设置为num_workers > 0时,每个工作进程将具有数据集对象的不同副本,因此通常需要独立配置每个副本,以避免从工作进程返回重复的数据。在工作程序进程中get_worker_info()调用时,返回有关工作程序的信息。在数据集的每个item或者Dataloader的worker_init_fn参数选项被修改时,它将被调用来修改每个副本的行为。
案例1:使用__iter__()进行worker的工作负载分配
class MyIterableDataset(torch.utils.data.IterableDataset):
def __init__(self, start, end):
super(MyIterableDataset).__init__()
assert end > start, "this example code only works with end >= start"
self.start = start
self.end = end
def __iter__(self):
worker_info = torch.utils.data.get_worker_info()
if worker_info is None: # single-process data loading, return the full iterator
iter_start = self.start
iter_end = self.end
else: # in a worker process
# split workload
per_worker = int(math.ceil((self.end - self.start) / float(worker_info.num_workers)))
worker_id = worker_info.id
iter_start = self.start + worker_id * per_worker
iter_end = min(iter_start + per_worker, self.end)
return iter(range(iter_start, iter_end))
>>> # should give same set of data as range(3, 7), i.e., [3, 4, 5, 6].
>>> ds = MyIterableDataset(start=3, end=7)
>>> # Single-process loading
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=0)))
[3, 4, 5, 6]
>>> # Mult-process loading with two worker processes
>>> # Worker 0 fetched [3, 4]. Worker 1 fetched [5, 6].
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=2)))
[3, 5, 4, 6]
>>> # With even more workers
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=20)))
[3, 4, 5, 6]
案例2:使用 worker_init_fn 进行worker的工作负载分配
class MyIterableDataset(torch.utils.data.IterableDataset):
def __init__(self, start, end):
super(MyIterableDataset).__init__()
assert end > start, "this example code only works with end >= start"
self.start = start
self.end = end
def __iter__(self):
return iter(range(self.start, self.end))
>>> # should give same set of data as range(3, 7), i.e., [3, 4, 5, 6].
>>> ds = MyIterableDataset(start=3, end=7)
>>> # Single-process loading
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=0)))
[3, 4, 5, 6]
>>> # Directly doing multi-process loading yields duplicate data
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=2)))
[3, 3, 4, 4, 5, 5, 6, 6]
def worker_init_fn(worker_id):
worker_info = torch.utils.data.get_worker_info()
dataset = worker_info.dataset # the dataset copy in this worker process
overall_start = dataset.start
overall_end = dataset.end
# configure the dataset to only process the split workload
per_worker = int(math.ceil((overall_end - overall_start) / float(worker_info.num_workers)))
worker_id = worker_info.id
dataset.start = overall_start + worker_id * per_worker
dataset.end = min(dataset.start + per_worker, overall_end)
>>> # Mult-process loading with the custom `worker_init_fn`
>>> # Worker 0 fetched [3, 4]. Worker 1 fetched [5, 6].
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=2, worker_init_fn=worker_init_fn)))
[3, 5, 4, 6]
>>> # With even more workers
>>> print(list(torch.utils.data.DataLoader(ds, num_workers=20, worker_init_fn=worker_init_fn)))
[3, 4, 5, 6]
5、其他类、方法
5.1 TensorDataset类
数据集包装张量。每个样本将通过沿第一维索引张量来检索。
参数:
- tensors (Tensor)
5.2 ConcatDataset类
参数是多个数据集的串联数据集。这个类在合并不同数据集是非常有用的。
参数:
- datasets (sequence) – List of datasets to be concatenated(可合并的数据集列表)
5.3 ChainDataset
用于链接多个IterableDatasets的数据集。
此类对于组装不同的现有数据集流很有用。链接操作是即时完成的,因此将大型数据集与此类连接起来将非常有效。
参数:
- datasets (iterable of IterableDataset) – datasets to be chained together(链接迭代器)
5.4 Subset类
指定索引处的数据集子集。
参数:
- dataset (Dataset) – The whole Dataset
- indices (sequence) – Indices in the whole set selected for subset
5.5 get_worker_info方法
返回有关当前 DataLoader迭代器工作进程的信息。
在工作线程中调用时,这将返回一个保证具有以下属性的对象:
id:当前worker的ID。num_workers:子进程总数。seed:当前worker的随机数种子。该值由主进程RNG和工作程序ID确定。dataset:此过程中数据集对象的副本。请注意,在不同的过程中,这将是与主过程中的对象不同的对象。
在主流程中调用时,将返回None。
Note:
当worker_init_fn用于传递给 DataLoader时,此方法可用于不同地设置每个工作进程,例如,worker_id 用于将dataset对象配置为仅读取分片数据集的特定部分,或seed用于对数据集代码中使用的其他库进行随机数种子设置(例如NumPy)。
5.6 torch.utils.data.random_split(dataset, lengths, generator=<torch._C.Generator object>)
将数据集随机拆分为给定长度的不重叠的新数据集。(可选)修复生成器以获得可重复的结果,例如:
random_split(range(10), [3, 7], generator=torch.Generator().manual_seed(42))
参数:
5.7 torch.utils.data.Sampler(data_source)
采样器的基类。每个Sampler子类都必须提供一个__iter__()方法,提供一种对数据集元素的索引进行迭代的方法,以及一种返回的迭代器长度的__len__()方法。
__len__()并非严格要求DataLoader有该方法,但是在涉及长度的任何计算中都应该使用该方法。
5.8 torch.utils.data.SequentialSampler(data_source)
始终以相同顺序顺序采样元素。
参数:
- data_source(Dataset)–要从中采样的数据集
5.9 RandomSampler(data_source, replacement=False, num_samples=None, generator=None)
随机采样元素。如果不进行替换,则从经过改组的数据集中采样。如果有替换,则用户可以指定num_samples绘制。
参数:
- data_source(Dataset)–要从中采样的数据集
- replacement (bool) – 如果为真,则采样的样本会发生变化,默认为
False,即默认数据不会被重复采样。 - num_samples (int) – 采样数,默认为数据集的长度。
- generator (Generator) – 用于采样的生成器。
案例:
>>> list(torch.utils.data.RandomSampler(torch.Tensor([1,2,3,4,5,6])))
[0, 5, 4, 3, 1, 2]
>>> list(torch.utils.data.RandomSampler(torch.Tensor([1,2,3,4,5,6]), replacement=True, num_samples=5))
[4, 0, 4, 2, 5]
>>> list(torch.utils.data.RandomSampler(torch.Tensor([1,2,3,4,5,6]), replacement=True))
[3, 3, 4, 3, 2, 0]
5.10 torch.utils.data.SubsetRandomSampler(indices, generator=None)
从给定的索引列表中随机抽样元素,而无需替换。
参数:
- indices (sequence) – a sequence of indices
- generator (Generator) –随机数发生器
5.11 torch.utils.data.WeightedRandomSampler(weights, num_samples, replacement=True, generator=None)
在[0,..,len(weights)-1]中以给定的概率(权重)对元素进行采样。
参数:
- weights (sequence) –权重序列,不必累加为1;
- num_samples(int)–采样数;
- replacement (bool) – 是否重复采样;
- generator (Generator) – 随机数发生器。
案例:
>>> list(WeightedRandomSampler([0.1, 0.9, 0.4, 0.7, 3.0, 0.6], 5, replacement=True))
[4, 4, 1, 4, 5]
>>> list(WeightedRandomSampler([0.9, 0.4, 0.05, 0.2, 0.3, 0.1], 5, replacement=False))
[0, 1, 4, 3, 2]
5.12 BatchSampler(sampler, batch_size, drop_last)
采样器的子类:批量采样器。
参数:
- sampler:采样器;
- batch_size:批量大小
- drop_last:是否删除最后一个不合格的batch
案例:
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))
[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True))
[[0, 1, 2], [3, 4, 5], [6, 7, 8]]
5.13 DistributedSampler(dataset, num_replicas=None, rank=None, shuffle=True, seed=0)
将数据加载限制为数据集子集的采样器。
与 torch.nn.parallel.DistributedDataParallel结合使用时特别有用。在这种情况下,每个进程都可以传递:torch.utils.data.DistributedSampler实例作为 DataLoader采样器,并加载原始数据集的专有子集。
参数:
- dataset – 采样的数据集;
- num_replicas (int, optional) – 参与分布式培训的进程数。默认情况下,
rank从当前分布式组中检索。 - rank (int, optional) –在
num_replicas中当前进程的等级。默认情况下,rank从当前分布式组中检索。 - shuffle (bool, optional) – 是否打乱数据;
- seed (int, optional) – 如果
shuffle=True,随机种子用来配置随机采样器。在分布式组中的所有进程中,此数字应相同。默认值:0。
在分布式模式下,必须在每个时期的开始处调用:meth set_epoch(epoch)<set_epoch>方法, 然后才能创建DataLoader迭代器,以确保epoch之间的shuffle操作。否则,将始终使用相同的顺序。
案例:
>>> sampler = DistributedSampler(dataset) if is_distributed else None
>>> loader = DataLoader(dataset, shuffle=(sampler is None),
... sampler=sampler)
>>> for epoch in range(start_epoch, n_epochs):
... if is_distributed:
... sampler.set_epoch(epoch)
... train(loader)
完
