
paddleocr论文解析
PP-OCR::一种实用的超轻量OCR系统(论文解析)
1、PP-OCR作者
作者是来自百度研究院的各位大佬:
Yuning Du, Chenxia Li, Ruoyu Guo, Xiaoting Yin, Weiwei Liu, Jun Zhou, Yifan Bai, Zilin Yu, Yehua Yang, Qingqing Dang, Haoshuang Wang
2、摘要
光学字符识别(OCR)系统已广泛应用于办公自动化、工厂自动化、在线教育、地图制作等各种应用场合,但由于文本形式的多样性和计算效率的要求,OCR仍然是一个具有挑战性的课题。本文提出了一种实用的超轻量OCR系统,即PP-OCR。PP-OCR的整体模型大小仅为3.5M用于识别6622个汉字和2.8M用于识别63个字母数字符号。我们引入一系列策略来增强模型能力或减小模型尺寸。并用实际数据进行了相应的消融实验。同时,发布了几种预训练的中英文识别模型,包括文本检测器(使用97K图像)、方向分类器(使用600K图像)和文本识别器(使用1790万图像)。此外,本文提出的PP-OCR算法在法语、韩语、日语和德语等语言识别任务中也得到了验证。上述所有模型都是开源的,代码可以在GitHub存储库中找到,即:https://github.com/paddle/paddocr。
3、增强、剪枝策略
3.1 文本检测
在本节中,将详细介绍六种增强文本检测器的模型能力或减小模型大小的策略。
3.1.1 Light Backbone
backbone 的大小对文本检测器的模型大小有显著影响。因此,在构建超轻量化模型时,应选择轻骨架。随着图像分类技术的发展,MobileNetV1、MobileNetV2、MobileNetV3和ShuffleNetV2系列通常被用作轻主干。每个系列有不同的规模。下图提供了20种backbone的性能表现:(https://github.com/PaddlePaddle/PaddleClas/)

这里的MobileNetV3在推理时间和精度上都有较好的表现,百度选择了 MobileNetV3_large_x0.5,作为精度和效率的权衡。顺便说一句,Padderclas提供了多达24个系列的图像分类网络结构和训练配置,122个模型的预训练权重及其评估指标,如ResNet、ResNet_vd、SERes-NeXt、Res2Net、Res2Net vd、DPN、DenseNet、EfficientNet、Exception、HRNet等。
3.1.2 Light Head
文本检测器的头部类似于FPN(Lin et al.2017)在目标检测中的架构(使用了DB模块),融合了不同尺度的特征图,证明了对小文本区域检测的效果。为了便于合并不同分辨率的特征映射,通常采用1×1卷积将特征映射缩小到相同的通道数(使用inner_channels作为short)。该概率图和阈值图由融合后的特征图和卷积生成,卷积也与上述inner_channels相关。因此,inner_channels对模型尺寸有很大的影响。当inner_channels从256减少到96时,模型尺寸从7M减少到4.1M,但精度略有下降。
3.1.3 Remove SE
SE是 squeeze-and-excitation的缩写(Hu、Shen和Sun,2018)。SE块对通道间的依赖关系进行显式建模,并自适应地重新校准通道特征响应。因为SE块可以明显提高视觉任务的准确率,MobileNetV3的搜索空间中包含了SE块,并且有大量的SE块在MobileNetV3体系结构中。然而,当输入分辨率较大时,如640×640时,很难用SE块估计通道特征响应。精度提高有限,但时间成本很高。当从主干中删除SE块时,模型尺寸从4.1M减小到2.5M,但精度没有影响。
3.1.4 CLRD 余弦学习率衰减🌟
学习速率是控制学习速度的超参数。学习率越低,损失值变化越慢。虽然使用较低的学习率可以确保不会错过任何局部极小值,但这也意味着收敛速度较慢。在训练的早期阶段,权值处于随机初始化状态,因此可以设置一个相对较大的学习速率来加快收敛速度。在训练的后期,权重接近最优值,因此应该使用相对较小的学习率。余弦学习率衰减已成为提高模型精度的首选学习率缩减策略。在整个训练过程中,余弦学习速率衰减保持了较大的学习速率,因此其收敛速度较慢,但最终的收敛精度较好。下图是其函数曲线:

3.1.5 Learning Rate Warm-up 学习率预热🌟
论文(He et al.2019a)表明,使用学习率预热操作有助于提高图像分类的准确性。在训练过程开始时,使用过大的学习率可能会导致数值不稳定,建议使用较小的学习率。当训练过程稳定时,使用初始学习率。对于文本检测,实验表明该策略也是有效的。
此时的学习率函数曲线应该是从0增长到设置的初始值,然后使用CLRD.
3.1.6 FPGM Pruner : FPGM 裁剪🌟
剪枝是提高神经网络模型推理效率的另一种方法。为了避免模型剪枝导致的模型性能下降,我们使用FPGM(He et al.2019b)在原始模型中寻找不重要的子网络。FPGM以几何中值为准则,将卷积层中的每个滤波器看作欧氏空间中的一个点。然后计算这些点的几何中值,用类似的值重新移动过滤器,如下图所示。每层的压缩比对于修剪模型也很重要。统一修剪每一层通常会导致显著的性能下降。在PP-OCR中,根据(Li et al.2016)中的方法计算每层的修剪灵敏度,然后用于评估每层的冗余度。
FPGM论文:https://arxiv.org/pdf/1811.00250.pdf 🌟
FPGM项目地址:https://github.com/he-y/filter-pruning-geometric-median 🌟
PFEC论文:https://arxiv.org/abs/1608.08710 🌟

关于FPGM裁剪策略可以参考文章:FPGM 裁剪。
3.2 方向分类
3.2.1 Light Backbone
我们还采用了与文本检测器相同的MobileNetV3作为方向分类器的backbone。因为这个任务相对简单,所以我们使用MobileNetV3_small_ x0.35从经验上平衡准确性和效率。当使用更大的backbone时,精确度不会提高更多。
3.2.2 Data Augmentation
例如旋转、透视失真、运动模糊和高斯噪声。这些过程简称为BDA(basedataaugmentation)。它们被随机添加到训练图像中。实验表明,BDA对方向分类器的训练也有一定的帮助。除BDA外,最近还提出了一些新的数据增强操作,以提高图像分类的效果。
- AutoAugment:https://arxiv.org/pdf/1805.09501v3.pdf
参考资料:https://blog.csdn.net/rainy0103/article/details/95180460
-
RandAugment:https://arxiv.org/abs/1909.13719
参考资料:https://blog.csdn.net/qq_42738654/article/details/103631455
-
CutOut:https://arxiv.org/abs/1708.04552v2
参考资料:https://blog.csdn.net/mingqi1996/article/details/96129374
-
RandErasing:https://arxiv.org/abs/1708.04896
参考资料:https://blog.csdn.net/xuluohongshang/article/details/79000951
-
HideAnd-Seek:https://arxiv.org/abs/1704.04232
参考资料:https://blog.csdn.net/qq_40760171/article/details/102722856
-
GridMask:https://arxiv.org/abs/2001.04086
参考资料:https://github.com/Jia-Research-Lab/GridMask
https://zhuanlan.zhihu.com/p/103992528?utm_source=zhihu&utm_medium=social&utm_oi=1126834861566304256
-
Mixup:https://arxiv.org/pdf/1710.09412.pdf
参考资料:https://zhuanlan.zhihu.com/p/139398593
https://blog.csdn.net/ellin_young/article/details/81142168
-
Cutmix:https://arxiv.org/pdf/1905.04899.pdf
参考资料:https://github.com/clovaai/CutMix-PyTorch
https://www.cnblogs.com/monologuesmw/p/12932407.html
https://zhuanlan.zhihu.com/p/104992391?utm_source=wechat_session
但实验表明,除了随机增强和随机删除外,大多数算法都不适用于方向分类器的训练。RandAugment效果最好。最后,我们将BDA和RandAugment添加到方向分类的训练图像中。
3.2.3 Input Resolution 输入分辨率
通常,当归一化图像的输入分辨率增加时,精度也将提高。由于方向分类器的主干很轻,适当提高分辨率不会导致计算时间明显提高。在以往的大多数文本识别方法中,归一化图像的高度和宽度分别设置为32和100。然而,在PP-OCR中,高度和宽度分别设置为48和192,以提高方向分类器的精度。
3.2.4 PACT 参数裁剪激活
PACT是一个在线量化方法,它提前从激活中删除一些异常值。剔除异常值后,模型可以学习到更合适的量化尺度。PACT对激活进行预处理的公式如下:
基于ReLU函数对普通PACT方法的激活值进行预处理。所有大于某个阈值的激活值都将被截断。然而,MobileNetV3中的激活函数不仅是ReLU,而且是 Hard Swish。使用普通的PACT量化会导致更高的量化损耗。因此,我们修改了激活预处理公式如下,以减少量化损失。
采用改进的PACT量化方法对方向分类器模型进行量化。另外,在PACT参数中加入系数为0.001的L2正则化,提高了模型的鲁棒性。
上述FPGM剪枝器和PACT量化的实现是基于PaddleSlim1的。是一个用于模型压缩的工具箱。它包含了剪枝、不动点量化、知识提炼、超参数搜索、神经结构搜索等一系列压缩策略。
3.3 文本识别
3.3.1 Light Backbone
MobileNetV3_small_x0.5
MobileNetV3_small_x1.0 模型增加了2M,性能提升明显。
3.3.2 Data Augmentation数据扩充
除BDA之外,还有以下策略:
-
TIA:
论文link:https://arxiv.org/abs/2003.06606
首先,在图像上初始化一组基准点。然后随机移动这些点,通过几何变换生成一个新的图像。在PP-OCR中,我们将BDA和TIA加入到文本识别的训练图像中。

3.3.3 CLRD 余弦学习率衰减(同上)
3.3.4 特征图分辨率
为了适应多语种识别,特别是中文识别,在PPOCR中,CRNN输入的高度和宽度设置为32和320。因此,原始MobileNetV3的步幅不适合于文本识别。为了保留更多的水平信息,我们将下采样特征图的步长从(2,2)改为(2,1)。为了保留更多的垂直信息,我们进一步将二次下采样特征图的步长从(2,1)修改为(1,1)。
因此,第二下采样特征图s2的步长对整个特征图的分辨率和文本识别器的精度有很大的影响。在PP-OCR中,s2被设置为(1,1),以在经验上获得更好的性能。

3.3.5 正则化参数 权值衰减 L2范数
文本识别中,L2正则对结果的影响非常大!
3.3.6 学习率预热 Learning Rate Warm-up
同文本检测
3.3.7 Light Head
采用全连接层对序列特征进行编码,将序列特征编码为普通序列中的预测字符。序列特征的维数对文本识别器的模型尺寸有很大的影响,特别是对于字符数超过6000的中文识别。同时,并不是维数越高,序列特征表示能力越强。在PP-OCR中,序列特征的维数根据经验设置为48。
3.3.8 预训练模型
如果训练数据较少,则对在ImageNet等大数据集上训练的现有网络进行微调,以实现快速收敛和更好的精度。在图像分类和目标检测中的传递学习实验表明了上述策略的有效性。在真实场景中,用于文本识别的数据往往是有限的。如果用上千万个样本训练模型,即使是合成的模型,也能显著提高精度。通过实验验证了该策略的有效性。
3.3.9 PACT量化
我们采用方向分类的类似量化方案来减小文本识别器的模型尺寸,只是跳过了LSTM层。由于LSTM量化的复杂性,这些层目前不会被量化。
4、实验
对于文本检测,有97k个训练图像和500个验证图像。在训练图像中,68K幅图像是真实的场景图像,这些图像来自一些公共数据集和百度图像搜索。使用的公共数据集包括LSVT(Sun等人,2019)、RCTW-17(Shi等人,2017)、MTWI 2018(He和Yang,2018)、CASIA-10K(He等人,2018)、SROIE(Huang等人,2019)、MLT 2019(Nayef等人,2019)、BDI(Karatzas等人,2011)、MSRA-TD500(Yao等人,2012)和CCPD 2019(Xu等人,2018)。百度图像搜索的训练图像大多是文档文本图像。剩下的29K合成图像主要集中在长文本、多方向文本和表格文本的场景中。所有的验证图像都来自真实场景。
对于方向分类,有600k训练图像和310K验证图像。在训练图像中,100K图像是真实场景图像,来自公共数据集(LSVT、RCTW-17、MTWI 2018)。它们是水平文本,纠正和裁剪图像的基本事实。剩下的500K合成图像主要集中在反转文本上。我们使用垂直字体合成一些文本图像,然后水平旋转它们。所有的验证图像都来自真实场景。
对于文本识别,有17.9M的训练图像和18.7K的验证图像。在训练图像中,有190万张是真实场景图像,这些图像来自一些公共数据集和百度图像搜索。使用的公共数据集包括LSVT、RCTW-17、MTWI 2018和CCPD 2019。其余16M合成图像主要集中在不同背景的场景、平移、旋转、透视变换、线条干扰、噪声、垂直文本等。合成图像的语料库来源于真实场景图像。所有的验证图像也都来自真实场景。
为了快速进行消融实验并选择合适的策略,我们从真实场景训练图像中选取4k图像进行文本检测,从真实场景训练图像中选取300k图像进行文本识别。
此外,我们收集了300张不同实际应用场景的图像,对整个OCR系统进行评估,包括合同样本、车牌、铭牌、火车票、测试单、表格、证书、街景图像。
此外,为了验证所提出的PP-OCR在其他语言中的应用,我们还收集了一些用于字母数字符号识别、法语识别、韩语识别、日语识别和德语识别的语料库。
合成文本行图像进行文本识别。一些用于字母数字符号识别的图像来自公共数据集ST(Gupta、Vedaldi和Zisserman 2016)和SRN(Yu等人,2020)。表2显示了统计数据。由于用于文本检测的MLT 2019包括多语言图像,因此用于中文和英文识别的文本检测器也可以支持多语言文本检测。由于数据有限,我们还没有找到合适的数据来训练多语种方向分类器。
用于文本检测和文本识别的数据合成工具是从文本呈现(Sanster 2018)修改而来的。
Implementation Details
我们使用Adam优化器训练所有模型,并采用余弦学习率衰减作为学习率调度。不同任务的初始学习率、批量大小和阶段数见下表。在得到训练后的模型时,可以使用FPGM剪枝和PACT量化进一步缩小模型尺寸,将上述模型作为预训练模型。FPGM剪枝机和PACT量化的训练过程与以前的相似。

在推理阶段,用HMean来评价文本检测器的性能。准确度用于评估方向分类器或文本识别器的性能。Fscore用于评估OCR系统的性能。为了计算F值,一个正确的文本识别结果应该是准确的位置和相同的文本。GPU推断时间在单个T4 GPU上进行测试。CPU推断时间在Intel(R)Xeon(R)Gold 6148上进行了测试。我们使用Snapdragon 855(SD 855)来评估量化模型的推理时间。
4.1 文本检测


4.2 方向分类
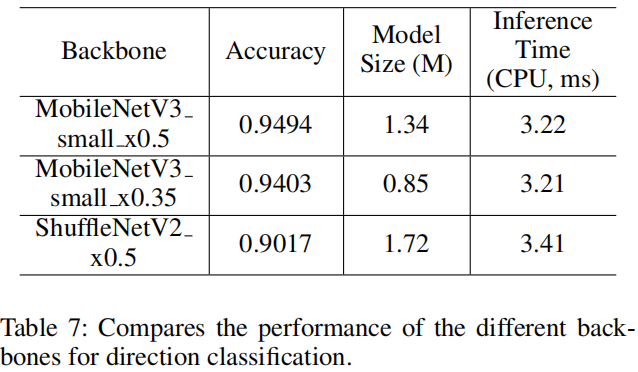


4.4 文本识别





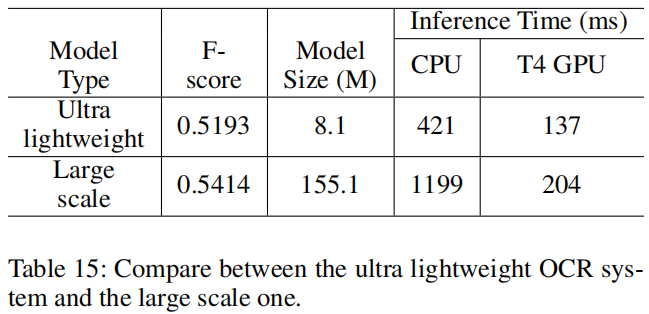
完!
