
PixelLink论文解析
PixelLink::基于语义分割、像素分类的文本检测算法(论文解析)
作者:elfin 资料来源:PixelLink论文
PixelLink的作者分别为:\(DanDeng^{1,3}\)、\(Haifeng Liu^{1}\)、 \(Xuelong Li^{4}\)、\(Deng Cai^{1,2}\)
分别来自:
- 1 浙江大学计算机学院CAD&CG国家重点实验室;
- 2 阿里巴巴浙江大学联合前沿技术学院;
- CVTE Research;
- 中国科学院西安光学精密机械研究所.
项目地址:https://github.com/ZJULearning/pixel_link,贡献者:\(DanDeng^{1,3}\)等!
1、摘要
目前最先进的场景文本检测算法都是基于深度学习的方法,它依赖于边界框回归,至少执行两种预测:文本/非文本分类和位置回归。在这些方法中,回归在Bbox的获取中起着关键的作用,但它并不是必不可少的,因为文本/非文本预测本身也可以看作是一种包含完整位置信息的语义切分。然而,场景图像中的文本实例往往彼此非常接近,使得它们很难通过语义分割进行分离。因此,需要进行实例分割来解决这个问题。本文提出了一种基于实例分割的场景文本检测算法PixelLink。文本实例首先通过将同一实例中的像素链接在一起进行分割。然后直接从分割结果中提取文本边界框,无需进行位置回归。实验表明,与基于回归的方法相比,PixelLink可以在多个基准上获得更好或可比的性能,同时需要更少的训练迭代次数和更少的训练数据。
2、背景介绍
在文本阅读领域,通常分为:文本检测、文本识别两个重要领域。
检测任务,也称为定位,以图像为输入,输出文本在其中的位置。随着深度学习和一般目标检测技术的进步,人们提出了越来越精确和高效的场景文本检测算法,如CTPN(Tian et al.2016)、TextBoxs(Liao et al.2017)、SegLink(Shi,Bai,and Belongie 2017)和EAST(Zhou et al.2017)。这些当年的STA模型都是基于全卷积神经网络模型构建,且主要是基于如下两种预测任务:
- 文本/非文本预测,如TextBoxs、SegLink、EAST;
- 位置回归,如Bbox的偏移量预测 TextBoxs、SegLink、CTPN ;边界框的绝对位置预测 EAST 。
在SegLink等方法中,还可以预测段之间的连接。在这些预测之后,应用主要包括将段连接在一起(例如SegLink、CTPN)或非极大值抑制(例如TextBoxs、EAST)的后处理来获得边界框作为最终输出。
位置回归长期以来一直被用于目标检测和文本检测,并被证明是有效的。它在最先进的文本边界框生成方法中起着关键作用。然而,如上所述,文本/非文本预测不仅可以作为回归结果的置信度,还可以作为分割得分图,它本身包含位置信息,可以直接用于获得边界框。因此,回归并非不可或缺。
然而,如下图所示,场景图像中的文本实例通常彼此非常接近。在这种情况下,它们非常困难,有时甚至不可能仅通过语义分割(即文本/非文本预测)来分离;因此,还需要在实例级别进行分割。

针对这一问题,本文提出了一种新的场景文本检测算法PixelLink。它直接从实例分割结果中提取文本位置,而不是从边界框回归中提取文本位置。在PixelLink中,训练一个深度神经网络(DNN)来进行两种像素预测:文本/非文本预测和连接预测。文本实例中的像素标记为正(即文本像素),否则标记为负(即非文本像素)。这里的link概念灵感来自SegLink的link设计,但有着显著的区别。每个像素有8个邻居。对于给定的像素和它的一个邻居,如果它们位于同一实例中,它们之间的连接将被标记为正,否则将被标记为负。预测的正像素通过预测的正链接连接在一起成为连接的组件(CC)。实例分段是这样实现的,每个CC代表一个检测到的文本。利用OpenCV(Its 2014)中的MinAreaRect(寻找最小外接矩形)等方法,得到CCs的边界盒作为最终的检测结果。
名词说明:
CC:连接组件
我们的实验证明了PixelLink相对于基于回归的最新方法的优势。具体来说,从零开始训练,PixelLink模型可以在几个基准上获得相当或更好的性能,同时需要较少的训练迭代和较少的训练数据。
3、相关工作(其他架构的贡献)
3.1 语义分割、实例分割
分割任务是为图像分配像素级的标签。当只考虑对象类别时,称为语义分割。此任务的主要方法通常采用完全卷积网络(FCN)方法(Long、Shelhamer和Darrell 2015)。实例分割比语义分割更具挑战性,因为它不仅需要每个像素的对象类别,还需要实例的区分。它比语义分割更适合于一般的对象检测,因为它可以感知对象实例。该领域的最新方法大量使用目标检测系统。FCIS(Li et al.2016)扩展了R-FCN中位置敏感预测的思想(Dai et al.2016)。Mask R-CNN(He et al.2017a)将Faster R-CNN(Ren et al.2015)中的ROIPooling改变为ROIAllign。它们都在同一个深度模型中进行检测和分割,并且分割结果高度依赖于检测性能。
3.2 基于分割的文本检测
分割在文本检测中的应用由来已久。(Yao et al.2016)通过预测三种得分特征图:文本/非文本、字符类和字符链接方向,将检测任务转化为语义分割问题。然后将它们分组成单词或行。在(Zhang et al.2016)中,从FCN预测的显著性图中发现文本块,并使用MSER(Donoser and Bischof 2006)提取候选字符。最后用手工制作的规则形成线条或文字。在CCTN(He et al.2016)中,通过生成文本区域热图,使用粗网络粗略检测文本区域,然后通过细文本网络将检测到的区域细化为文本行,输出中心行区域热图和文本行区域热图。这些方法通常会遇到耗时的后处理步骤和令人不满意的性能。
3.3 基于回归的文本检测
这一类的大多数方法都利用了一般目标检测的发展。CTPN(Tian et al.2016)将目标检测中的anchor思想扩展到预测文本片段,然后通过启发式规则连接文本片段。TextBoxes(Liao et al.2017)是一种文本专用SSD(Liu et al.2016),采用了大长宽比anchor和不规则形状的anchor,以适应场景文本的大长宽比特性。RRPN(Ma et al.2017)在Faster R-CNN中增加了anchor和RoIPooling的旋转,以处理场景文本的方向。SegLink(Shi、Bai和Belongie 2017)采用SSD预测文本片段,并使用链接预测将其链接到完整实例中。EAST(Zhou et al.2017)执行非常密集的预测,这些预测使用位置感知NMS进行处理。所有这些基于回归的文本检测算法都能同时预测置信度和位置。在本文中,最新技术主要是指在IC13(Karatzas et al.2013)或IC15(Karatzas et al.2015)上表现最好的公开方法,包括TextBoxes、CTPN、SegLink和EAST。
4、通过实例分割的文本检测
如下图所示,PixelLink通过实例分段检测文本,其中预测的正像素通过预测的正链接连接在一起成为文本实例。然后直接从分割结果中提取边界框。
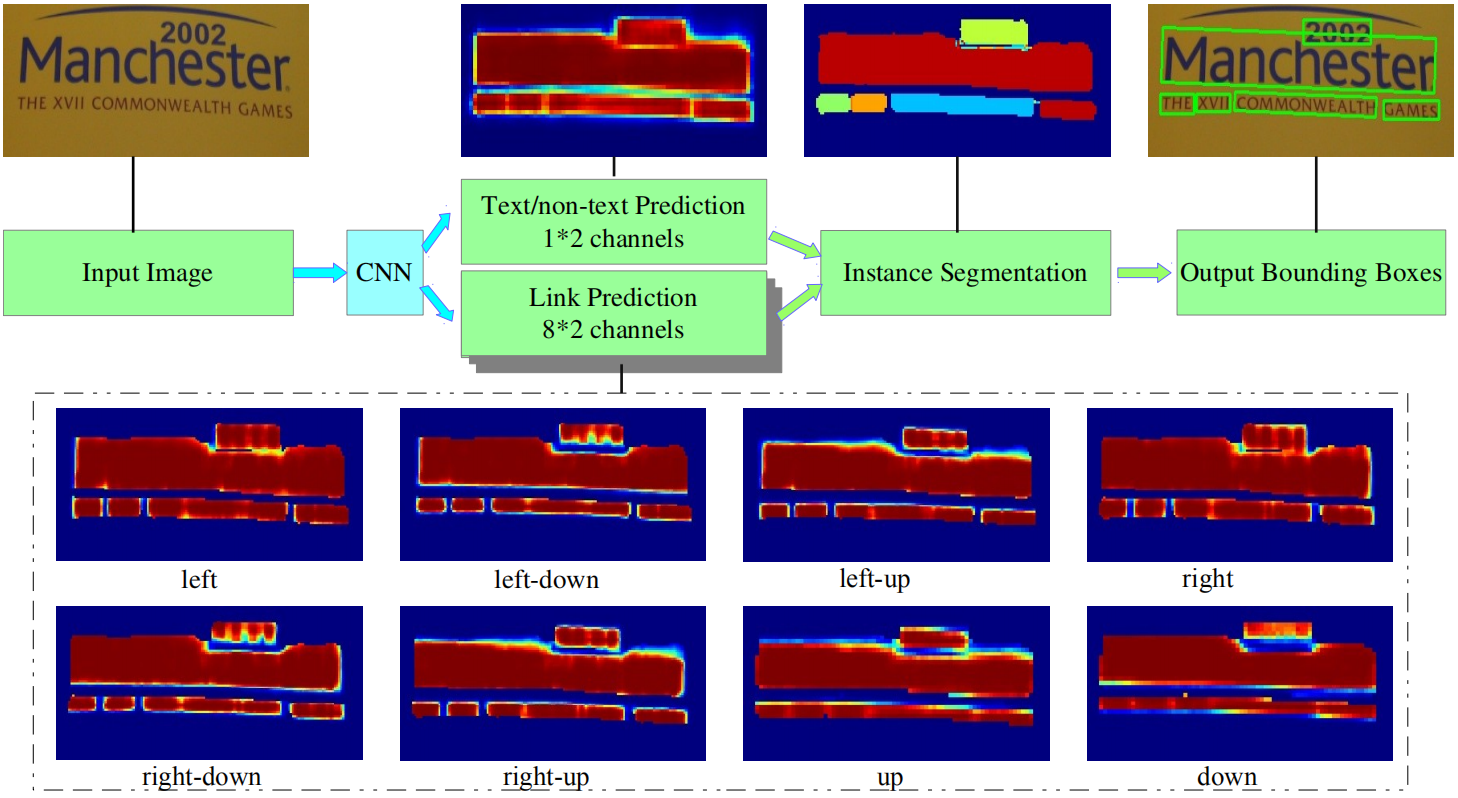
-
注:
Text/nontext Prediction实际上是语义分割;
Link Prediction实际上是8个方向的Mask,共8张;
为什么是两个通道?因为在channel这个维度上,分别标识了“是”、“不是”的概率。
4.1 网络架构
继SSD和SegLink之后,VGG16(Simonyan和Zisserman 2014)被用作特征提取器,全连接层(即fc6和fc7)被转换为卷积层。特征融合和像素预测的方式继承自(Long、Shelhamer和Darrell 2015)。如下图所示,整个模型有两个单独的header头,一个用于文本/非文本预测,另一个用于链接预测。两者都使用Softmax,因此它们的输出分别有1x 2=2 和 8 x 2=16个通道。
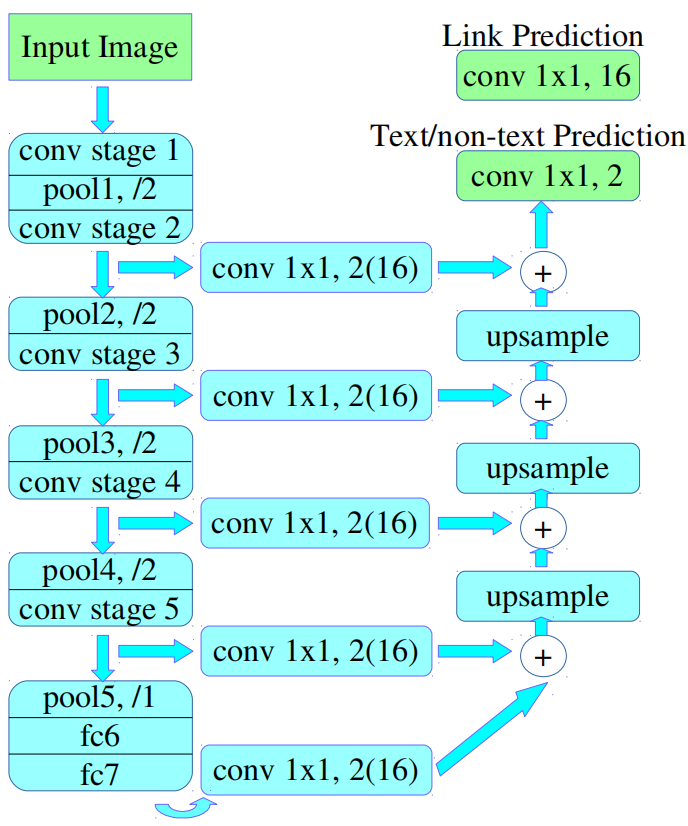
实现了特征融合层的两种设置: (2s的分辨率是原始图像的一半,4s是四分之一)
-
第一种:\(\frac{1}{2}\)下采样特征融合 表示为 PixelLink+VGG16 2s \(\{Conv2\_2, Conv3\_3, Conv4\_3, Conv5\_3, fc\_7\}\)
相比较与4s模型,2s模型多了一个在\(\frac{1}{2}\)分辨率的特征图上面的连接,即上图中的第一个\(Conv\;1\times 1,\;2\left ( 16 \right )\)
-
第二种:\(\frac{1}{4}\)下采样特征融合 表示为 PixelLink+VGG16 4s \(\{Conv3\_3,Conv4\_3, Conv5\_3, fc\_7\}\)
上文中所诉的\(Conv2\_2\)命名是由TF中的slim生成的,在VGG16的backbone中,作者设置每个stage的连续卷积部分使用
slim.repeat实现,scope命名为conv+stage_num,如stage1对应了conv1. slim在给每个层分配名字的时候默认使用的是:conv1/conv1_1、conv1/conv1_2,这里的stage先使用了两层卷积!所以\(Conv2\_2\)是stage2的第二层卷积。
4.2 将像素链接在一起
给定对每个像素的实例预测及其连接的预测,可以分别对它们应用两个不同的阈值。然后使用正链接将正像素分组在一起,形成一个CCs集合,每个CCs表示检测到的一个文本实例,因此实现了实例分割。值得注意的是,给定两个相邻像素的预测,它们的链接都由它们的预测决定,并且当两个链接预测中的一个或两个为正时,它们应该连接起来(相邻像素只要有正预测结果就连接起来)。这个连接过程可以用不相交的集合数据结构来实现。
备注:
isson:为什么两个像素之间的预测有两个,不是两个之间只有一个预测值吗?
解答:这里我们要注意预测阶段是每一个像素对8个方向的连接都有预测,所以Mask实际是\(8\times 2 =16\)个通道。对某一个像素而言,在这16为的通道向量中总有2个通道数值是与相邻像素的连接预测,而相邻像素的对应位置也有对它的连接预测,所以这里会在两个像素之间产生两个预测,而这两个预测的结果可能有四种情况!
4.3 Bbox提取
实际上,检测任务是在实例分割之后完成的。但是,在IC13(Karatzas等人2013)、IC15(Karatzas等人2015)和COCO文本(Veit等人2016)等挑战中,需要使用边界框作为检测结果。因此,通过OpenCV(Its 2014)中的MinAreaRect等方法提取CCs的边界框。MinAreaRect的输出是一个有方向的矩形,对于IC15可以很容易地转换成四边形,对于IC13可以很容易地转换成矩形。值得一提的是,在PixelLink中,对场景文本的方向没有限制。
这一步导致了PixelLink和基于回归的方法之间的关键区别,即边界框是直接从实例分割而不是位置回归中获得的。
4.4 分割后的后置滤波
由于PixelLink试图通过连接将像素分组在一起,因此不可避免地会有一些预测噪声,因此需要进行后置滤波步骤。一个简单而有效的解决方案是通过检测到的检测框的简单几何特征进行过滤,例如,宽度、高度、面积和纵横比等。例如,在后面6.3的IC15实验中,如果检测到的框的短边小于10个像素或面积小于300,则放弃该框。10和300是对IC15训练数据的统计结果。具体地说,对于所选择的过滤准则,选择训练集上相应的0.99分位数计算值作为阈值。
5、优化器 Optimization
5.1 真实值计算
按照TextBlocks的公式(Zhang等人,2016),文本边界框内的像素被标记为positive。如果存在重叠,则只有未重叠的像素为正。否则是否定的。(这一规则规避了边框重合带来的误差,但是也引入了边框侵入文本的风险,总的来说此设置会使模型识别的更加精准,以此减小损失。因为一旦文字被多个框识别到会产生漏识风险,损失函数就较大,在预测中如果产生某个字符遗漏就有可能是这里的规则造成的,但是此规则利大于弊!)
对于一个给定的像素和它的八个邻居之一,如果他们属于同一个实例,他们之间的连接是正的,否则是否定的。
注意,真实值计算是在调整为预测层形状的输入图像上进行的,即\(Conv3\_3\)表示4s,\(Conv2\_2\)表示2s。
5.2 损失
PixelLink的损失函数为:
这里的像素分类要比 \(link\) 重要, 作者的参数 \(\lambda\) 设置为2.
Pixel的损失
5.2.1 正像素损失
文本实例的大小可能变化很大。例如,在第一张图中,“曼彻斯特”的面积大于所有其他单词的总和。在计算损失时,如果对所有正像素赋予相同的权重,对面积较小的实例是不公平的,可能会影响性能。针对这一问题,提出了一种新的分割加权损失方法——实例平衡交叉熵损失法。即:
其中:
- \(B_{i}\)是给定的所有实例的初始权值,即实例的平均面积;
- \(S_{i}\)是第\(i\)个实例的面积,\(S\)是总的实例面积(对于一个页面),\(N\)是实例数量;
最终每个像素的权值计算为:
5.2.2 负像素损失
Online Hard Example Mining (OHEM) (Shrivastava, Gupta, and Girshick 2016) 用于负像素的选择。一般来讲,通过设置权值为1来选择损失最高的负像素\(r * S\)个。其中\(r\)是负正比且一般设置为3.
按照负正比,那么\(r * S\)实际就是所有的负像素了,所有负像素权值是直接设置为1!而\(r\)如果设置为3,那么部分负像素不为1,具体设置参考OHEM。
5.2.3 像素的总损失
基于上面两种机制可以写出权值矩阵,即为\(W\)(每一个像素点的权值都已知了),所以像素分类任务的损失为:
其中\(L_{pixel\_CE}%\)表示了文本/非文本的交叉熵,注意这里实际上就是前景、背景的预测。
最后,小实例中的像素具有更高的权重,而大实例中的像素具有更小的权重。然而,每一个例子都会造成同样的损失,有利于将小目标检测的更好。
Link的损失
5.2.4 Link的损失
正、负link的损失分别计算,且仅在正像素上计算:
\(L_{link\_CE}\)是link预测的交叉熵损失矩阵,\(W_{pos\_link}\)、\(W_{neg\_link}\)分别是正负连接的权值,这里的\(W\)实际上就是像素分类里面的\(W\)!细节上像素\((i,j)\)对于第\(k\)个相邻像素:
其中\(Y_{link}\)是连接的标签矩阵!
则,连接link的总损失为:
其中\(rsum\)表示reduce sum,它将张量的所有元素相加为标量。
5.3 数据增强
数据扩充的方式与SSD相似,只是增加了一个随机旋转步骤。输入图像首先以0.2的概率旋转0、π/2、π或3π/2的随机角度,与(He et al.2017b)相同。然后随机裁剪面积为0.1到1,纵横比为0.5到2。最后,将它们统一调整为512×512。增强后,短边小于10像素的文本实例将被忽略。剩余少于20%的文本实例也将被忽略。在损失计算期间,忽略实例的权重设置为零。
在训练中,设置数据增强的代码段可以自行查看项目
6、实验
PixelLink模型在多个基准上进行了训练和评估,取得了与现有方法相当或更好的结果,表明无需边界盒回归就能很好地解决文本定位问题。
6.1 Benchmark Datasets基准数据集
ICDAR2015(IC15)的Challenge 4(Karatzas et al.2015)是在任意方向检测场景文本的最常用基准。它包括两组:train和test,分别包含1000和500个图像。与以前的ICDAR挑战不同,使用Google glass获取图像时不考虑视角、定位或帧质量。只有长度超过3个字符的可读拉丁语文字才被视为单词四边形。“do not care”文字也会被注释,但在评估时会被忽略。
ICDAR2013(IC13)(Karatzas et al.2013)是另一个广泛使用的场景文本检测基准,包含229个用于训练的图像,233个用于测试。此数据集中的文本实例大多是水平的,并在单词中注释为矩形。
TD500(Yao et al.2012)中的MSRA-TD500(TD500)文本也是任意定向的,但比IC15中的文本长得多,因为它们是按行注释的。TD500总共包含500个图像,300个用于训练,200个用于测试。英文和中文都有。
每个数据集使用相应的标准评估协议。
6.2 实施细则
采用SGD优化PixelLink模型,momentum=0.9,权重衰减 weight decay=\(5\times 10^{-4}\)。VGG网络不是从ImageNet预训练模型进行微调,而是通过xavier方法(Glorot和Bengio 2010)进行初始化。前100次迭代的学习率设置为\(10^{-3}\),其余的固定为\(10^{-2}\)。细节将在每个实验中单独描述。
备注:
SGD::momentum:SGD随机梯度下降,一般容易震荡或在鞍点缺乏动量而使得无法离开平地,添加动量实现了二阶梯度的模仿,更多资料参考:
weight decay:即权值衰减,也即\(L_{2}\)正则(每次都记不住,同一个东西取这么多名字搞事情)
实验采用的环境:
- tensorflow1.1.0
- python
- *GTX Titan X 3
- 128G RAM
- 两个Intel Xeon CPU(2.20GHz)
设置\(batchsize\)为\(24\),迭代速度 \(0.65 s/iterations\),整个过程训练了7∼8小时。
6.3 在IC15中检测定向文本
训练从随机初始化的VGG16模型开始,仅限IC15训练。4s的模型需要大约4万次迭代的训练,而2s的时间更长,大约6万次迭代。最小的边长和面积用于后置滤波,并分别设置为10和300,即通过忽略“do not care”实例来训练IC15的相应99%。通过网格搜索找到像素和链接的阈值,并将其设置为(0.8,0.8)。测试时输入图像的大小调整为1280×768。结果显示在下表:
Table 1
| Model | R | P | F | FPS |
|---|---|---|---|---|
| PixelLink+VGG16 2s | 82.0 | 85.5 | 83.7 | 3.0 |
| PixelLink+VGG16 4s | 81.7 | 82.9 | 82.3 | 7.3 |
| EAST+PVANET2x MS | 78.3 | 83.3 | 81.0 | — |
| EAST+PVANET2x | 73.5 | 83.6 | 78.2 | 13.2 |
| EAST+VGG16 | 72.8 | 80.5 | 76.4 | 6.5 |
| SegLink+VGG16 | 76.8 | 73.1 | 75.0 | — |
| CTPN+VGG16 | 51.6 | 74.2 | 60.9 | 7.1 |
- 所有方法均在720P的分辨率下测试 或者 1280 * 768
- MS 表示多尺度
- PVANET2x 是PVANET的修订版本(加倍channels)
2s模型比EAST+PVANET2x的F值高了5.5个点,且在COCO-Text评估集上取得的得分为:
| Model | R | P | F |
|---|---|---|---|
| PixelLink+VGG16 2s | 35.4 | 54.0 | 42.4 |
| EAST (Zhou et al. 2017) | 32.4 | 50.4 | 39.5 |
由于在实现细节和运行环境上的差异,进行客观公正的速度比较并非易事。此处报告的速度仅用于表明,如果使用相同的深度模型(即VGG16)作为基本网络,则与基于回归的最新方法相比,PixelLink并不慢。请注意,尽管EAST+PVANET2x运行得最快,但它的精确度远低于PixelLink模型。
6.4 在TD500中检测长文本
由于TD500中是行长文本检测,因此IC15上的最终模型不用微调(可直接训练)。相反,该模型在IC15训练集上预训练约15K次迭代,并在TD500训练集+HUST-TR400(Yao、Bai和Liu 2014)上微调约25K次迭代。图像大小调整为768×768以进行测试。像素和链接的阈值设置为(0.8,0.7)。后置滤波的最小短边为15,最小区域为600,对应训练集的99%。
如下表所示。结果表明,在所有基于VGG16的模型中,EAST的表现最差,因为它对大感受野的需求最高。SegLink和PixelLink都不需要更深的网络来检测长文本,因为它们对感受野的需求较小。
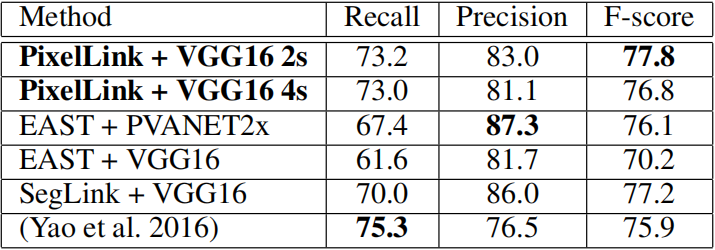
6.5 检测IC13中的水平文本
IC15的最终模型在IC13训练集、TD500训练集和TR400训练集上进行了微调,进行了大约10K的迭代。在单尺度测试中,所有图像的大小都调整为512×512。多刻度包括(384、384)、(512、512)、(768、384)、(384、768)、(768、768)和最大长边1600。对于单尺度测试,像素和链接的阈值为(0.7,0.5);对于多尺度测试,像素和链接的阈值为(0.6,0.5)。0.99分位数设置了10、300,分别表示短边和面积,用于后置后滤波。
与EAST和TextBoxs等基于回归的方法不同,PixelLink没有直接输出作为每个检测边界框的置信度,因此其多尺度测试方案是专门设计的。具体地说,不同比例尺的预测图被均匀地调整到所有特征图中的最大高度和最大宽度。然后,通过取平均值来融合它们。其余步骤与单标度测试相同。
下表说明,PixelLink多尺度可以使F分数提高了4~5个点,与PixelLink的表现类似。

7、分析与讨论
在IC15上的实验结果进一步分析表明,PixelLink作为一种基于分割的方法,比基于回归的方法有许多优点。如下表所示,在使用VGGNet的各种方法中,PixelLink训练速度快,数据量少,性能好。具体来说,经过大约25K次的反复训练(不到EAST或SegLink所需的一半),PixelLink可以达到与SegLink或EAST相当的性能。请记住,PixelLink是从头开始训练的,而其他的则需要从ImageNet预先训练的模型中进行微调。当在“IC15训练集”上从头开始训练时,SegLink只能获得67.8的F分数。

问题是,为什么PixelLink可以用更少的训练迭代次数和更少的训练数据获得更好的性能?我们人类善于学习如何解决问题。问题越简单,我们学习的速度就越快,我们需要的教材就越少,我们的表现也就越好。它也适用于深度学习模式。因此,可能有两个因素起作用。
-
感受野要求
当两者都采用VGG16作为主干时,SegLink在长文本检测方面的表现要比EAST好得多,如第二个表所示。这种差距应该是由于它们对接收域的不同要求造成的。训练EAST的预测神经元观察整个图像,以预测任意长度的文本。SegLink虽然也基于回归,但它的深层模型只尝试预测文本片段,因此对感受野的要求比EAST低。
-
任务难度
在基于回归的方法中,边界框表示为四边形或旋转矩形。每个预测神经元都必须学习以精确的数值来预测它们的位置,即四个顶点的坐标,或中心点、宽度、高度和旋转角度。这是可能的,也是有效的,早就被更快的R-CNN、SSD、YOLO等算法证明了。然而,这样的预测远不是直观和简单的。神经元必须学习很多,努力学习才能胜任自己的任务。
当涉及到PixelLink时,预测层上的神经元只需在特征图上观察自身及其相邻像素的状态。换句话说,在列出的方法中,PixelLink对神经元的感受野要求最低,学习任务也最简单。
从上面的假设中可以找到一个设计深层模型的有用指南:如果可能的话,简化深层模型的任务,因为这样可以使它们更快地得到训练,减少对数据的需求。
用非常有限的数据量从头开始训练PixelLink的成功也表明文本检测比一般的目标检测简单得多。文本检测可能更多地依赖于底层的纹理特征,而较少依赖于高层的语义特征。
8、模型分析
如下表所示,消融实验分析了PixelLink模型。虽然PixelLink+VGG16 2s车型有更好的性能,但它们比4s模型慢得多,实用性也差得多,因此,Exp.1中的最好4s模型作为比较的baseline。
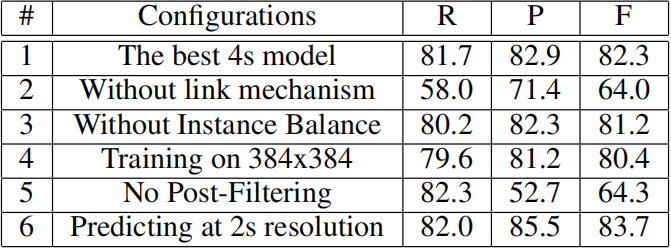
8.1 Link是非常重要的
Exp.2中,通过将连接上的阈值设置为零,连接被禁用,从而导致召回率和准确率的大幅下降。连接设计的重要性在于它将语义切分转化为实例切分,这对于PixelLink中相邻文本的分离是必不可少的。
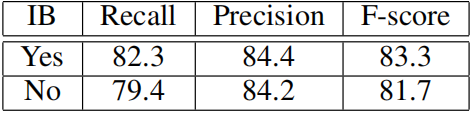
8.2 IB机制(实例平衡机制)
Exp.3中,实例平衡(IB)不被使用,并且在损失计算期间所有正像素的权重被设置为相同。即使没有IB,PixelLink的F分数也可以达到81.2,超过最先进的水平。当使用IB时,可以得到稍微好一点的模型。继续在IC13上的实验,性能差距更为明显(如下表所示).
8.3 训练图像大小很重要
Exp.4中,训练时图像大小调整为384×384,查全率和查准率都有明显下降。这种现象与SSD是一致的。
8.4 后置过滤是非常重要的
在实验5中,去除了后置过滤,使召回率略有提高,但精确度明显下降。
8.5 高分辨率更准确也更慢
在实验6中,预测是在\(Conv2\_2\)上进行的,性能得到了提高。然而,召回率和准确率提高都是以速度为代价的。如表1所示:2s的速度不到4s的一半,显示了性能和速度之间的权衡。
9、总结与展望
提出了一种新的文本检测算法PixelLink。通过实例分割,将同一文本实例中的像素连接在一起,完成检测任务。直接从分割结果中提取检测文本的边界框,而不进行位置回归。由于需要更小的感受野和更容易学习的任务,PixelLink可以在更少的迭代中用更少的数据从头开始训练,同时在几个基准上实现与基于位置回归的最新方法相当或更好的性能。
为了便于比较,本文选择VGG16作为backbone。为了获得更好的性能和更高的速度,还将研究其他一些深层模型。
与当前流行的实例分割方法(Li et al.2016)(He et al.2017a)不同,PixelLink的分割结果并不依赖于检测性能。PixelLink的应用将在其他一些需要实例分割的任务中进行探索。
完!
