LayoutLM: Pre-training of Text and Layout for Document Image Understanding 论文解读
LayoutLM: Pre-training of Text and Layout for Document Image Understanding
摘要
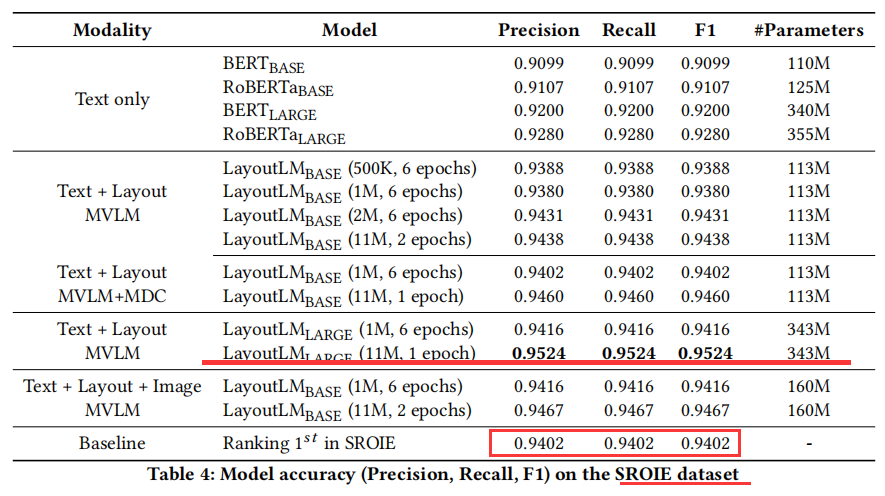
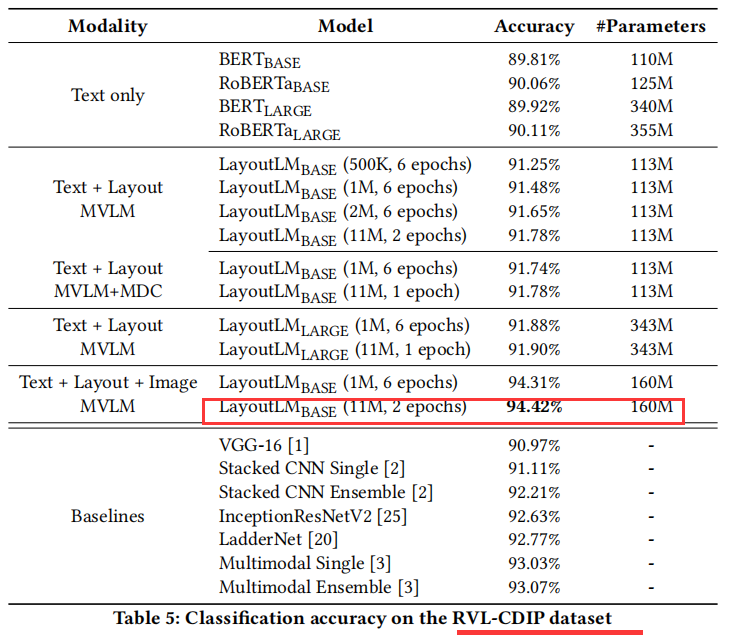
预训练技术已经在最近几年的NLP几类任务上取得成功。尽管NLP应用的预训练模型被广泛使用,但它们几乎只关注于文本级别的操作,而忽略了对文档图像理解至关重要的布局和样式信息。在本文中,跨扫描文档图像的文本和布局信息之间的交互,我们提出了LayoutLM来联合建模,这有利于大量实际的文档图像理解任务,如从扫描文档中提取信息。我们还利用图像特征将单词的视觉信息合并到LayoutLM中。据我们所知,这是第一次在一个文档级训练前的单一框架中共同学习文本和布局。它在几个下游任务中实现了新的最先进的结果,包括形式理解(从70.72到79.27)、接收理解(94.02至95.24)和文件图像分类(93.07至94.42)。代码和预先训练LayoutLM模型可以公开获得。
介绍
文件AI,或文件智能是一个相对较新的研究主题,涉及自动阅读、理解和分析业务文档的技术。业务文档是提供与公司内部和外部事务相关的详细信息的文件,如图1所示。它们可能是数字化的,以电子文件的形式出现,也可能是书面或打印在纸上的扫描形式。一些常见的商业文档包括采购订单、财务报告、商业电子邮件、销售协议、供应商合同、信函、发票、收据、简历等。商业文件对公司的效率和生产力至关重要。业务文档的确切格式可能有所不同,但是信息通常以自然语言呈现,并且可以以多种方式组织,包括纯文本、多列布局和各种表格/表单/图形。理解业务文档是一项非常具有挑战性的任务,因为文档的布局和格式多种多样,扫描的文档图像质量不高,模板结构复杂。如今,许多公司通过手工工作从业务文档中提取数据,这既费时又昂贵,同时还需要手工定制或配置。每种文档类型的规则和工作流通常需要硬编码,并随着特定格式的变化或在处理多种格式时进行更新。为了解决这些问题,文档人工智能模型和算法被设计用于自动分类、提取和结构化商业文档中的信息,加速自动文档处理工作流。当代文档AI的方法通常是建立在深度神经网络之上,从计算机视觉的角度或自然语言处理的角度,或两者的结合。早期的尝试通常集中于检测和分析文档的某些部分,比如表格区域。[7]最早提出了一种基于卷积神经网络(CNN)的PDF文档表检测方法。之后,[21,24,29]还利用了更先进Faster R-CNN模型[19]或Mask R-CNN模型[9]进一步提高了文档布局分析的准确性。此外,[28]提出了一种端到端、多模态、全卷积的网络,利用预训练的NLP模型中的文本嵌入,从文档图像中提取语义结构。最近,[15]引入了基于图卷积网络(GCN)的模型,用于结合文本和可视化信息,以便从业务文档中提取信息。尽管这些模型在深度神经网络的文档人工智能领域取得了重大进展,但这些方法中的大多数都面临两个限制:(1)仅依赖于少量的人工标注样本,而未对大量的未标注数据进行探索;(2)他们通常利用预先训练好的CV模型或NLP模型,但没有考虑文本和布局信息的多任务联合训练。因此,研究自我监督的文本和布局的预训练模型将有助于文档AI领域的进步。

为此,我们提出了一种简单而有效的文本和布局预训练方法LayoutLM,用于文档图像理解任务。受BERT模型[4]的启发,其中输入文本信息主要由文本嵌入和位置嵌入表示,LayoutLM进一步添加了两种类型的输入嵌入:(1)二维嵌入位置,表示标记在文档中的相对位置;(2)在文档中嵌入扫描标记图像的图像。LayoutLM的体系结构如图2所示。我们添加这两个输入嵌入是因为2d位置嵌入可以捕获文档中标记之间的关系,同时图像嵌入可以捕获一些外观特性,如字体方向、类型和颜色。此外,LayoutLM采用多任务学习目标,包括掩码可视化语言模型(MVLM)损失和多标签文档分类(MDC)损失,这进一步加强了对文本和布局的联合预训练。在这项工作中,我们的重点是基于扫描文档图像的文档预处理,而数字生成的文档难度较小,因为它们可以被视为不需要OCR的特殊情况,因此超出了本文的范围。具体来说,LayoutLM是在IIT-CDIP测试集合1.0版本上预训练的[14],包含600多万份扫描文档和1100万份扫描文档图像。这些数据包括新闻、税单、论文、演讲、科学出版物、问卷调查、简历、科学报告、说明书等,适合大规模的自我监督预训练。我们选择三个baseline数据集作为下游任务来评估预训练好的LayoutLM模型的性能。第一个是FUNSD 数据集[10],用于空间布局分析和形式理解。第二个是用于扫描收据信息提取的SROIE 数据集。第三种是RVL-CDIP 数据集[8]用于文档图像分类,其中包含40万幅、16类的灰度图像。实验表明,预训练的LayoutLM模型在这些基准数据集上的性能明显优于多个SOTA预训练模型,显示了在文档图像理解任务中对文本和布局信息进行预训练的巨大优势。
论文的贡献总结如下:
- 这是第一次,来自扫描文档图像的文本和布局信息被预先训练在一个单一的框架中。图像功能也被用来实现新的最先进的结果。
- LayoutLM使用MVLM和多标签文档分类作为训练目标,在文档图像理解任务中,它的表现明显优于几个预训练的SOTA模型。
- 代码和模型获取:
模型架构
回顾BERT模型
BERT模型是一种基于注意力的双向语言建模方法。实验证明,该BERT模型能够有效地从具有大规模训练数据的自监督任务中学习知识。BERT的结构是多层的双向transform编码器结构组成。它接受一个token序列并堆叠多个层以产生最终的表示。具体来说,给定一组用工具处理过的标记,将对应的单词嵌入、位置嵌入和分割嵌入相加,计算出输入嵌入。然后,这些输入嵌入通过多层transform,该编码器可以生成具有自适应注意机制的上下文化表示。
在BERT框架中有两个步骤:预训练和微调。预训练阶段分为Masked Language Modeling(MLM)和Next Sentence Prediction(NSP);在微调中,特定于任务的数据集被用于以端到端方式更新所有参数,BERT模型已成功地应用于一系列NLP任务。
LayoutLM模型
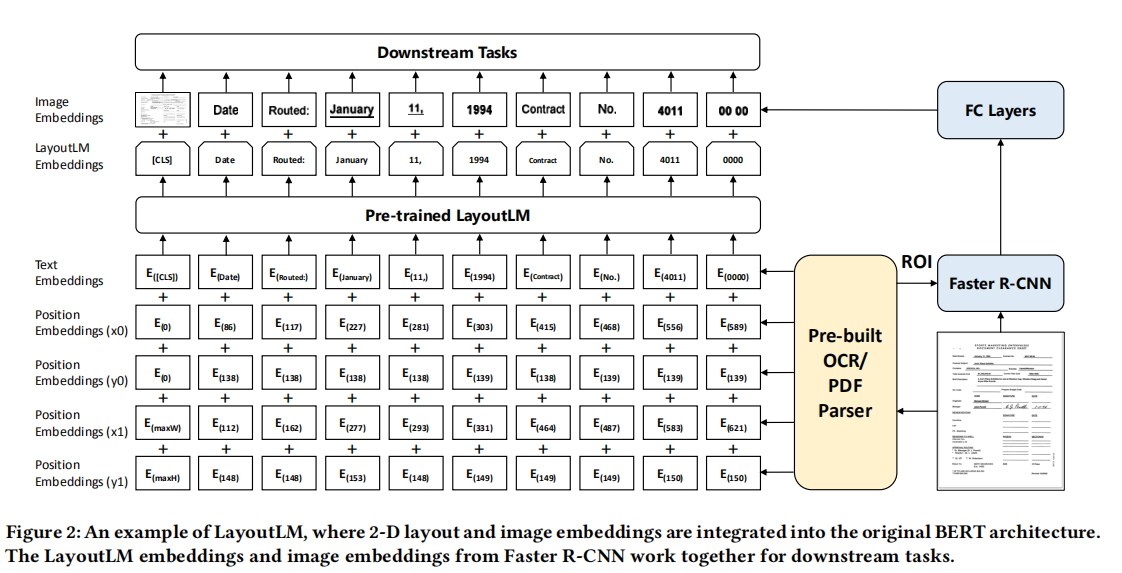
虽然说BERT在很多任务中是最优的模型,但是在文档内容分析及定位任务上,它使用的信息太少了,还有大量信息被抛弃,所以LayoutLM模型横空出世。模型架构见图2,架构主要分两块,一块是使用Faster-RCNN 提取图像特征,一块是使用嵌入技术提取文字语义信息。
- 2-D位置编码:坐标原点为:top-left。区域位置定位:(x0, y0, x1, y1),其中 (x0, y0)为左上角, (x1, y1)为右下角。
- Image Embedding:这里采用了OCR的技术获取图像、文字的边界(如使用python:pdfminer库),通过字符的位置可以切分相应的子图(裁剪出单词区域)。模型使用Fast-RCNNd 特征图对应区域作为图像的嵌入。
- 对于token[CLS],作者利用了当前页整个图像作为ROI(感兴趣的目标区域),这样有益于为后面的任务生成token[CLS]。就下面这句话是真的长,不妨分一下句子成分再理解一下:
- For the [CLS] token, we also use the Faster R-CNN model to produce embeddings using the whole scanned document image as the Region of Interest (ROI) to benefit the downstream tasks which need the representation of the [CLS] token.
预训练模型
Task 1: Masked Visual-Language Model: MVML
受mask语言模型的启发,LayoutLM使用它去学习文字及其位置信息的嵌入表示。实际上就是可以看作使用BERT这样的技术学习'词向量'。mask部分token时,保留其位置编码。
Task 2: Multi-label Document Classification 文档多分类任务
上面说有16类,如果预训练模型有16类,那么对文档的内容类别分的还是比较细的。如可以识别正文区域、标题区域、注释区域(猜测)、表格区域等。关于文档内容分类,此模型是开放领域,对于特殊领域,你可以进行微调。
模型消融实验