自己编译flink
自己编译flink的环境:Linux、git、maven、jdk8以上。
获取flink源代码:git clone https://github.com/apache/flink.git
克隆flink项目到本地,下载会等一会。

下载完成之后:
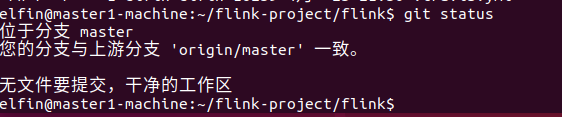
进入对应版本的分支
git tag 查看分支;git checkout release-1.9.2 进入release-1.9.2分支
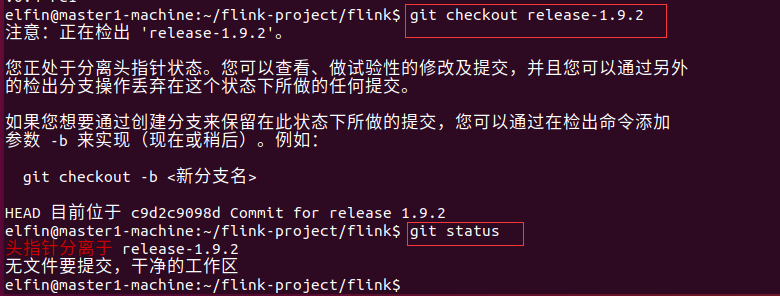
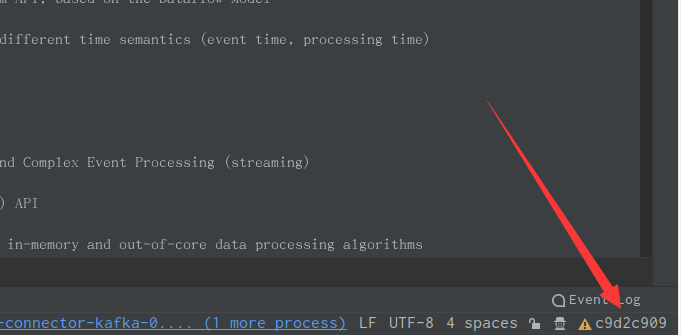
此时我们用IDEA打开这个flink项目,右下角会发现分支为:一串奇怪的字符串,其实是分支的编号,即上图中位于后的字符串,如图所示。
编译flink
确保进入flink项目目录。
命令:mvn clean install -Dmaven.test.skip=true 跳过测试
命令:mvn clean install -Dmaven.test.skip=true -Dfast 跳过测试、QA插件、javadoc以加速构建,默认会将Hadoop2的支持打包进去
针对指定版本的Hadoop版本:mvn clean install -Dmaven.test.skip=true -DHadoop.version=2.6.1
这里指定支持Hadoop2.6.1,你得确保你有这个版本的hadoop。
针对指定的Hadoop发行版编译flink:
命令:mvn clean install -Dmaven.test.skip=true -Pvendor-repos -DHadoop.version=2.6.1-cdh5.0.0
你可以使用命令行参数激活prom.xml中profile标签的配置。
如果用户主目录是加密的,可能会报错:java.io.IOException:File name too long exception。比如ubantu系统的encfs文件系统。那么那个模块报的错就修改哪个模块的配置文件,如:flink-yarn模块报的错,则在它的prom.xml文件中的scala-maven-plugin的configuration标签下添加:
<args> <arg>Xmax-classfile-name</arg> <arg>128</arg> </args>
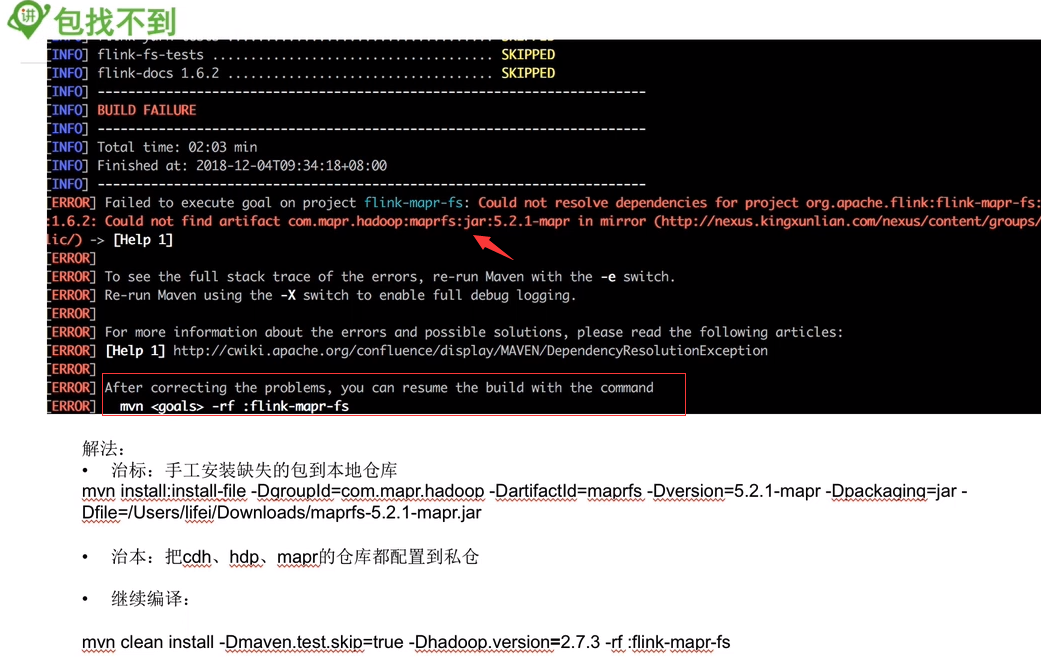
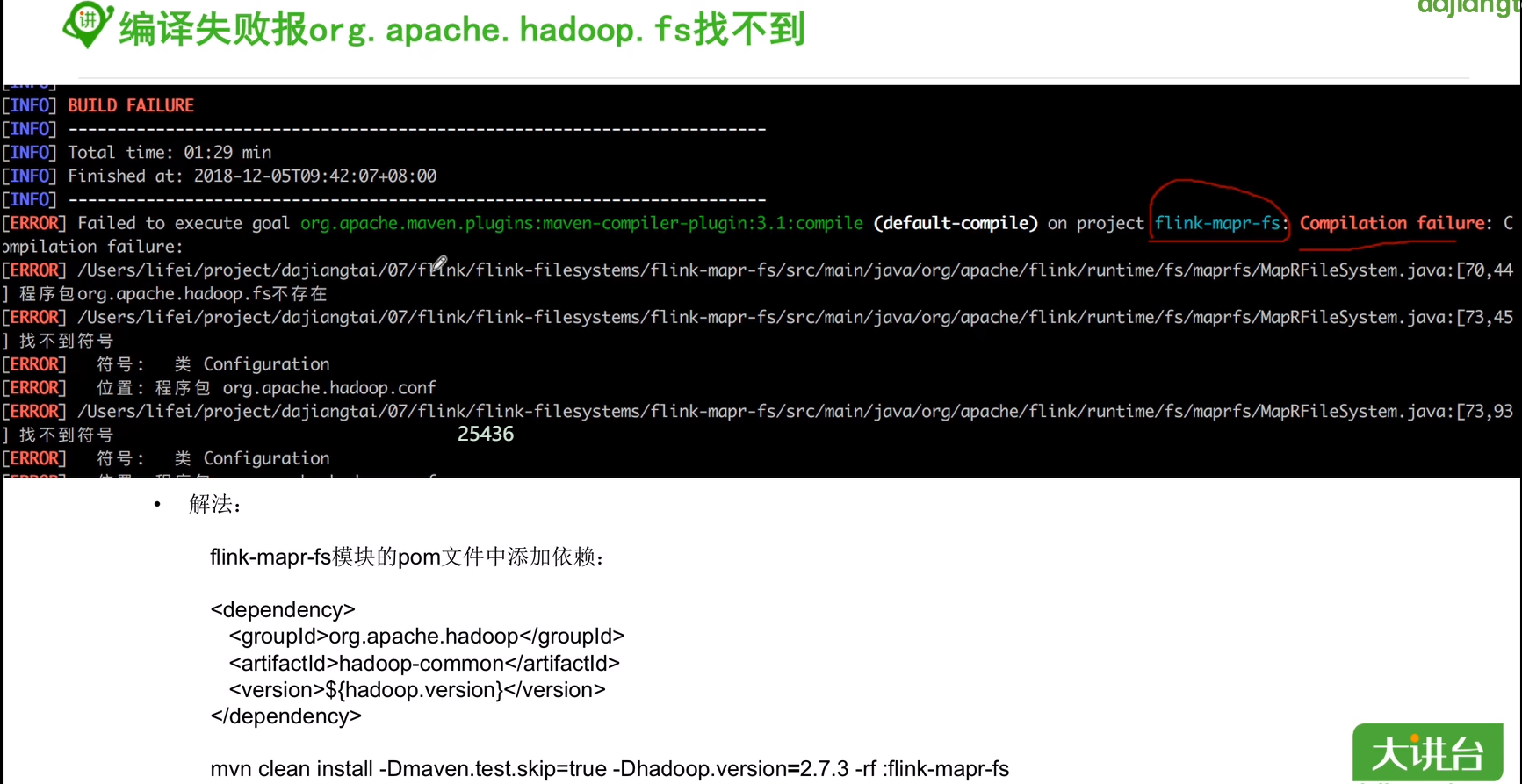
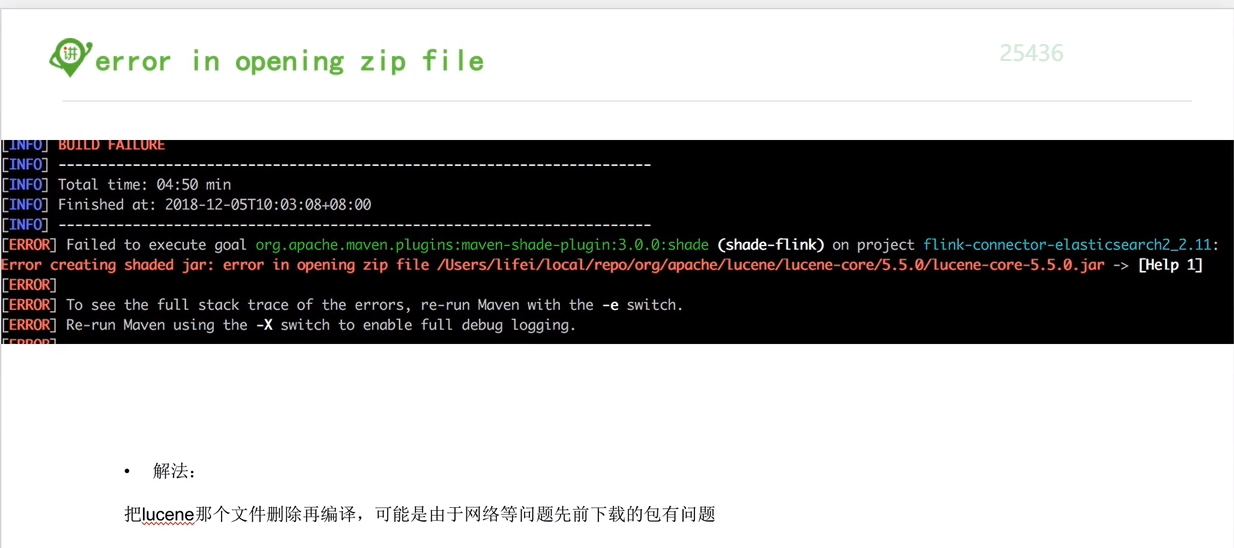
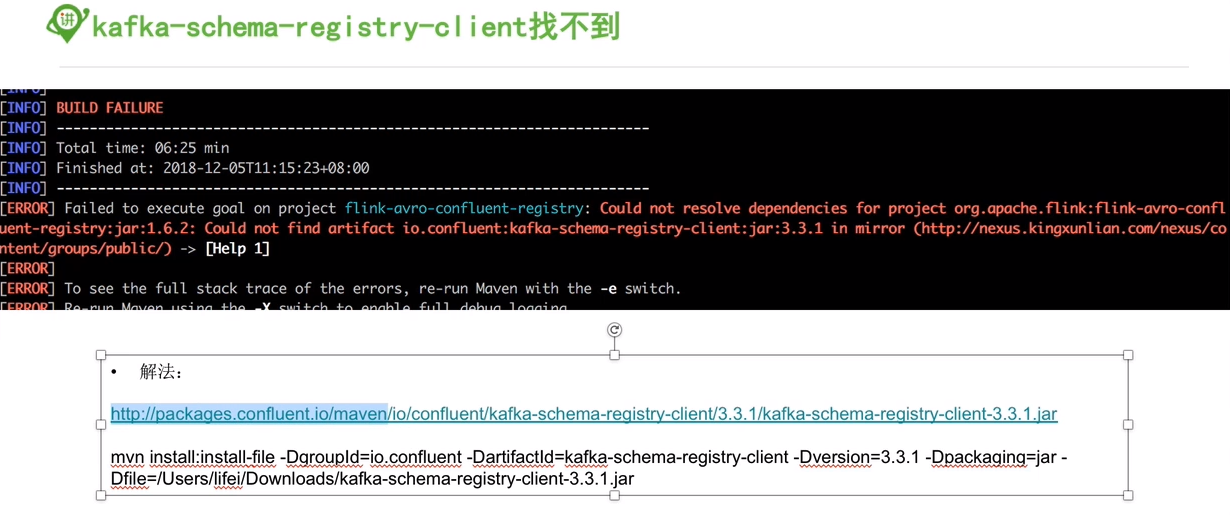
编译flink报错汇总