
CornerNet: Detecting Objects as Paired Keypoints论文架构详解
论文:CornerNet: Detecting Objects as Paired Keypoints
代码:https://github.com/princeton-vl/CornerNet
注:本文的shape将采用TF的数据维度,pytorch将通道channel提到了axis=1这个维度,注意自己区分。
一、论文模型的主架构
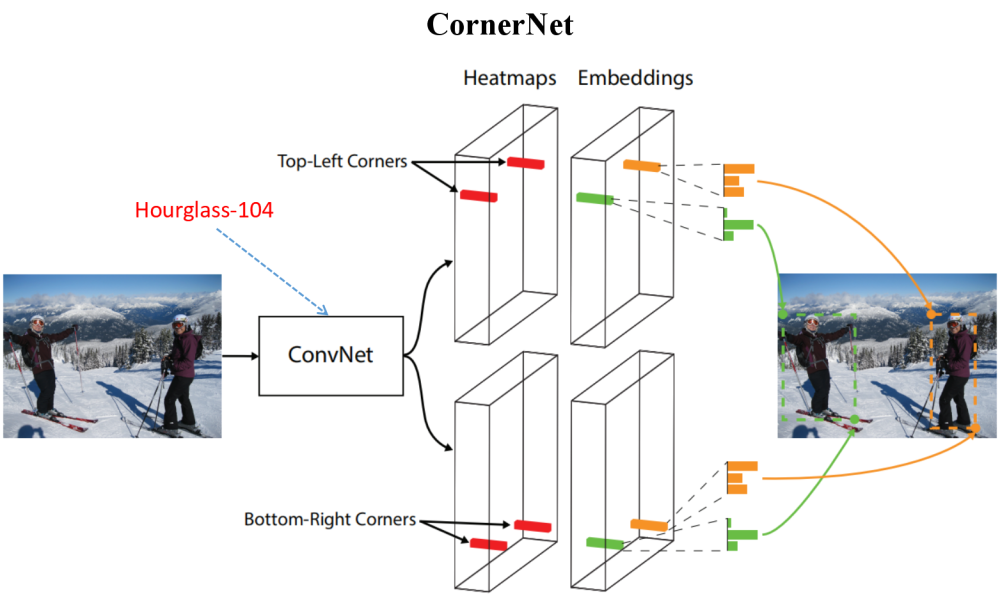
上图来源于原论文,Hourglass为沙漏模型,(猜测因模型结构和沙漏非常像而得名),后面会详细展开论文中的沙漏模型结构,以及用沙漏模型论文的原图进行说明。
CornerNet模型架构
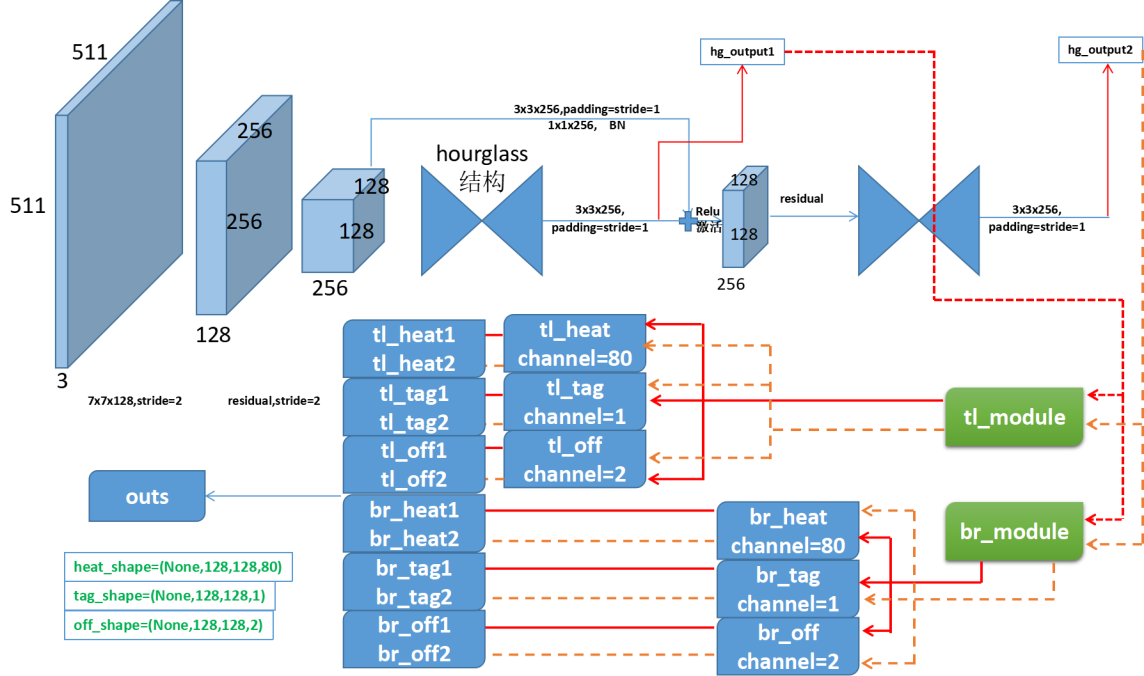
此处的heat(计算损失时经过了sigmoid激活)是角点的热力图,直白地说就是概率分布;tag对应了原论文中的Embedding,负责将左上角点和右下角点匹配,off是偏移量。输出中热力图的channel为80是因为数据的类别数为80,off的channel为2不难理解,tag为1?这里的思想和人体关键点检测是相同的,只是这里的Embedding向量为1-D,关于损失的计算由如下公式所示:
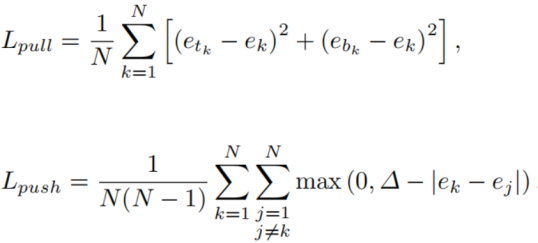
其中ek为两个嵌入向量的平均值,etk为左上的嵌入向量,ebk为右下的嵌入向量;Lpull用于组合角点,而Lpush用于分离角点,delta我们令其为1。这里有关于类别的求和,而我们的嵌入向量只有一维,那么求和是在哪个维度呢?
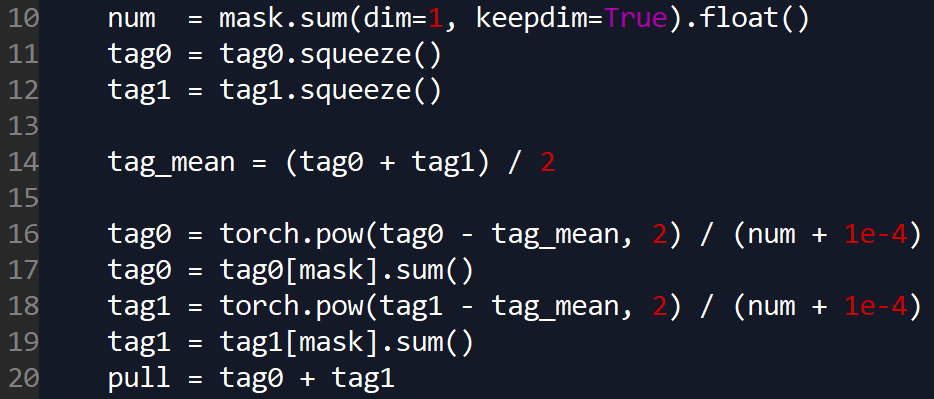
如上图所示,ek为均值,求和是使用mask取了部分区域的损失。
####################################
“#”中为引用内容,参考博客 CornerNet源码阅读笔记(一)------解码过程
引用部分shape为pytorch架构下的数据维度
一、理论回顾
CornerNet的总共上下两个分支,每个分支三种输出,分别为:各点为角点的概率,偏移,表示两个点是否为同一个物体的embedding得分
左上角分支:
heat map:tl_heat [batch,C,H,W]
offset: tl_regr [batch,2,H,W]
embedding: tl_tag [batch,1,H,W]
右下角分支:
br_heat, tl_heat [batch,C,H,W]
br_regr [batch,2,H,W]
br_tag [batch,1,H,W]
总计tl_heat, br_heat, tl_tag, br_tag, tl_regr, br_regr 六个输出。
解码流程:
1.分别在左上角和右下角的heat map中选出得分最高的前100个点
2.对这100个点进行逐个匹配,生成100*100个候选框
3. 通过匹配的两个点是否为同一类,两个点的embedding得分,以及空间位置(左上角必须比右下角小)这几个条件过滤掉大多数bbox,最终留下1000个候选框输出
注:最终生成的1000的候选框应该是要进行nms处理的,但是作者并未将nms操作写入解码函数.
原文链接:https://blog.csdn.net/goodxin_ie/article/details/90453802
####################################
二、第一层卷积将原始特征图分辨率降低了4倍
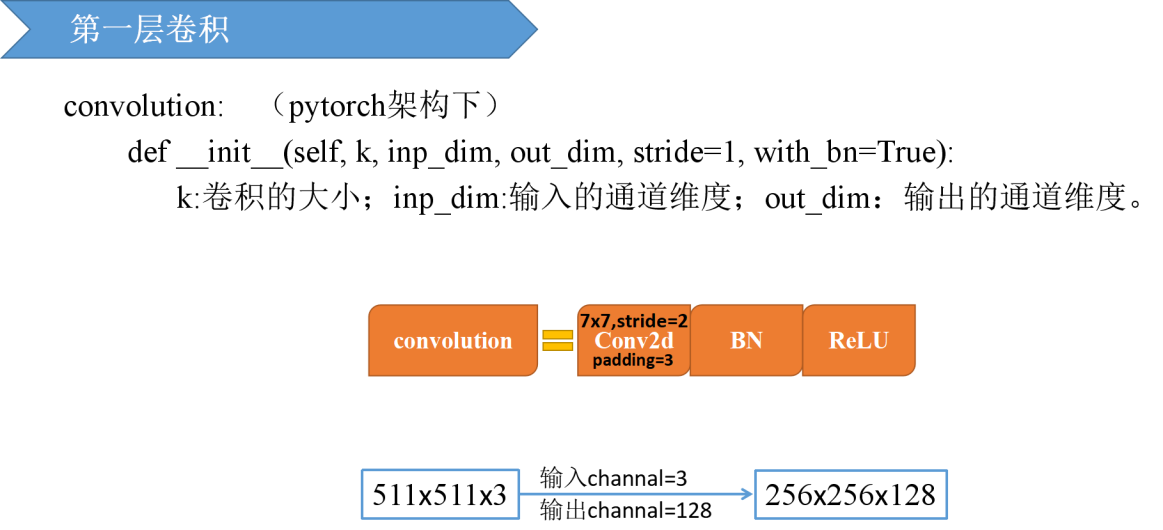
经过一个7x7的卷积层,共128个过滤器,步长为2,padding=3,得到的输出维度为256x256x128。
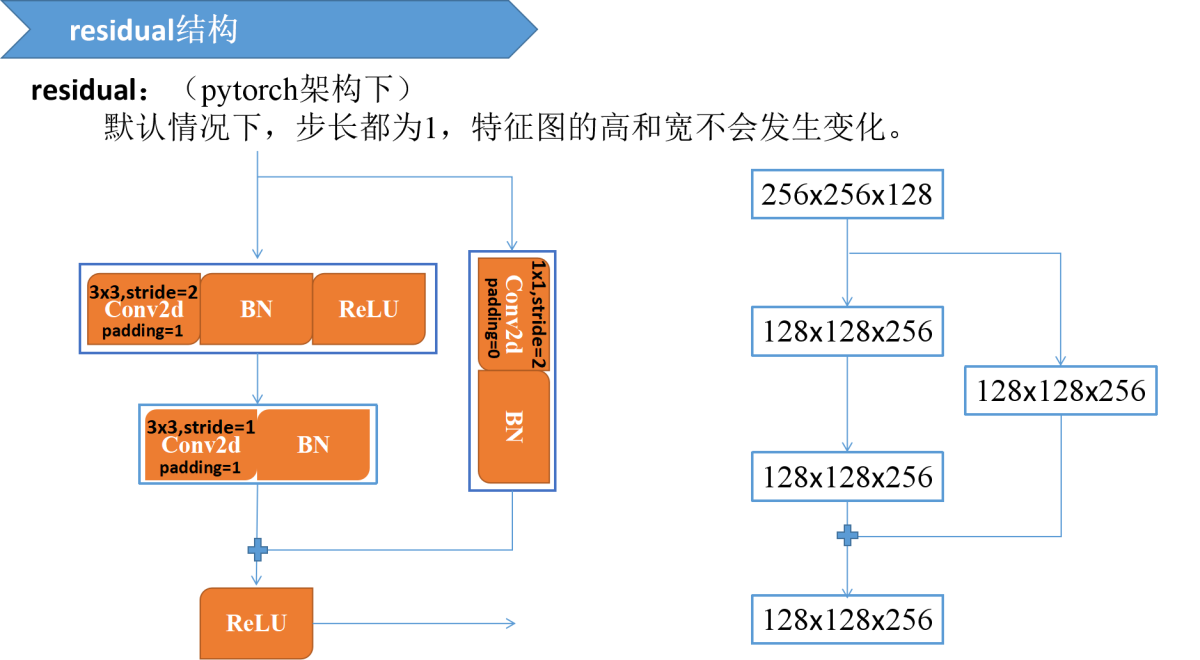
三、本文的主骨架是沙漏模型,而沙漏模型中的主要结构为residual
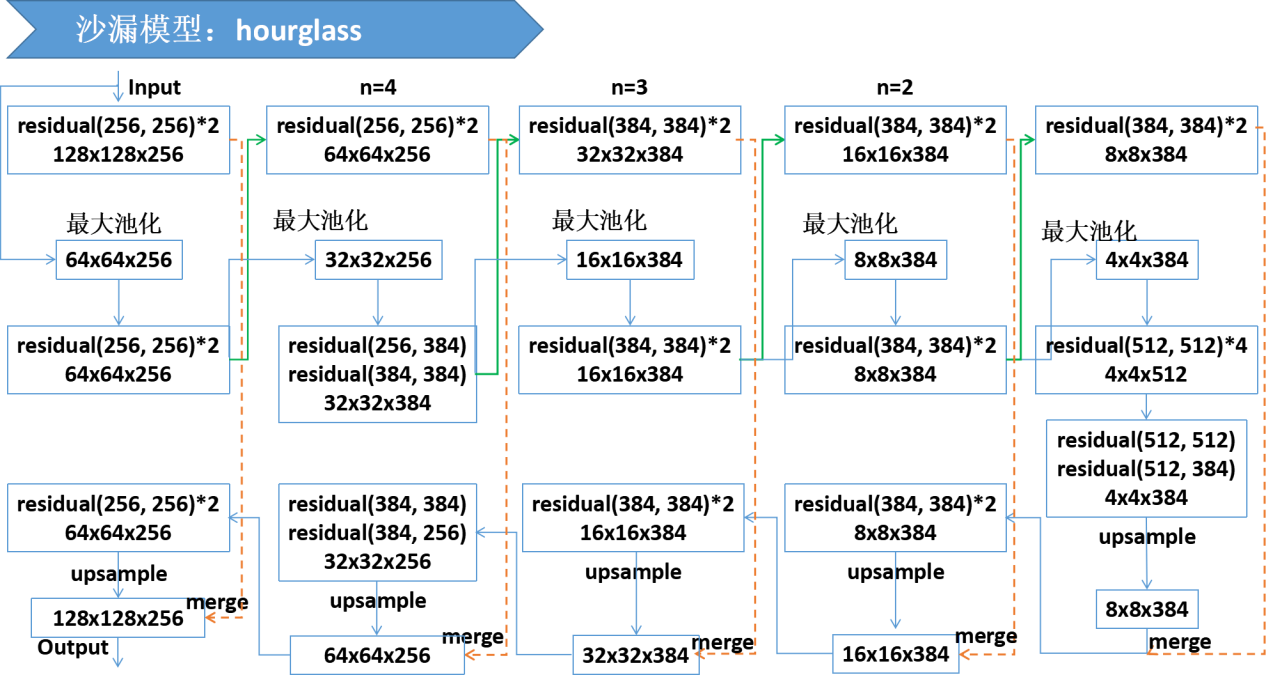
四、沙漏模型在本文中的架构
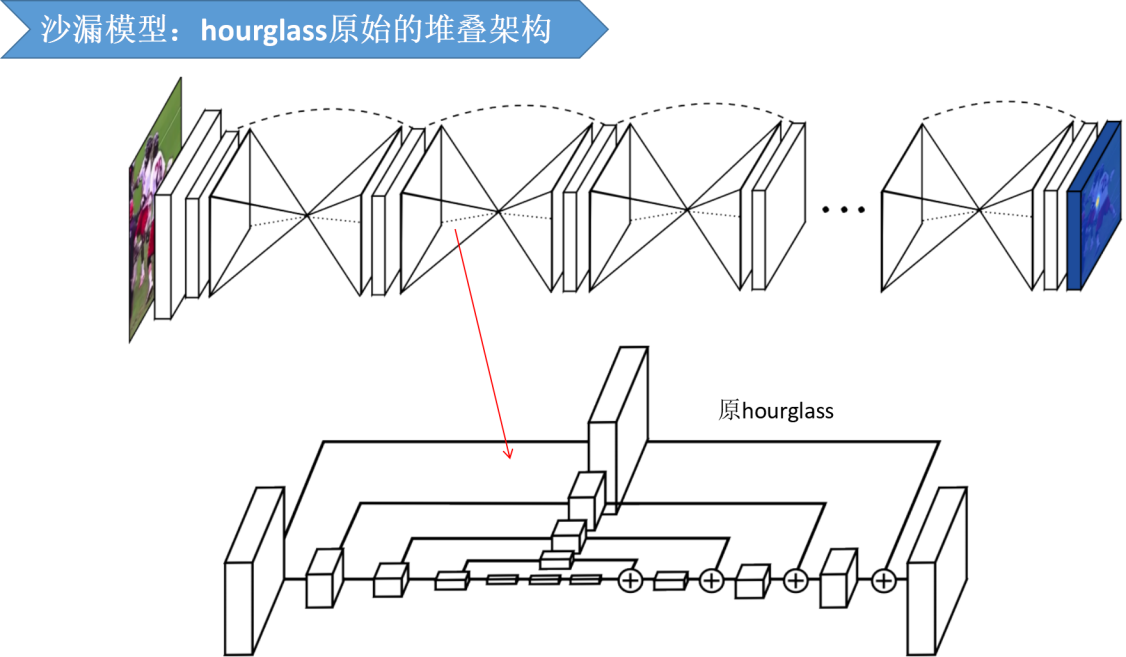
修改前的原架构为:
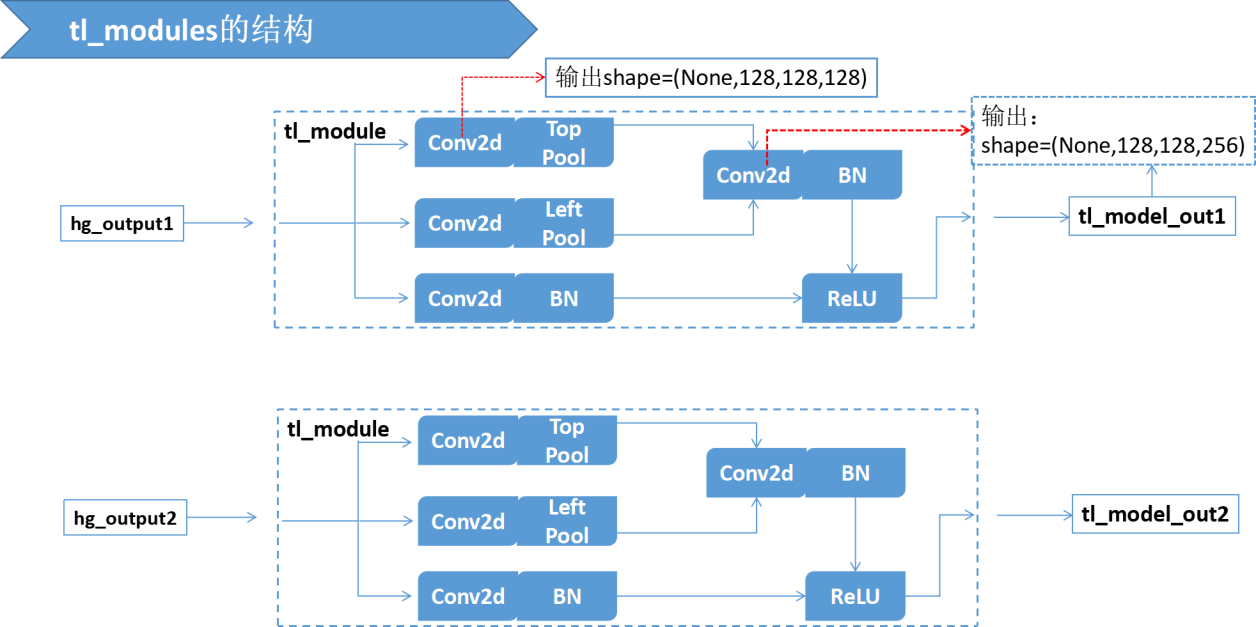
五、tl_models的结构
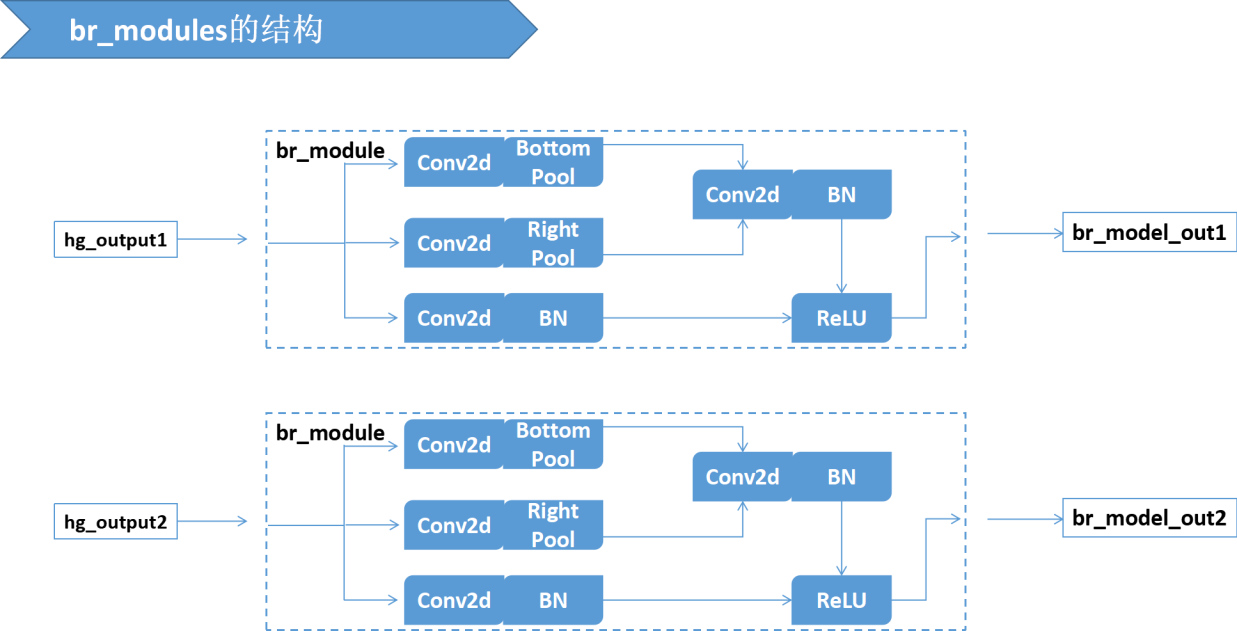
六、br_models的结构
七、模型输出outs的结构

这里为了看的清楚将很多张量拆开写了,源码中,tl_heats=[tl_heat1, tl_heat2] ; 其他几个指标类似。
以上资源需要可以从百度云盘下载:
链接:https://pan.baidu.com/s/17bkWCohmZJifVuFgiivvhQ
提取码:ni5e

 浙公网安备 33010602011771号
浙公网安备 33010602011771号