
关键词提取、TF-IDF
TF-IDF
TF-IDF统计的是词库所有词的出现频率与在文件级出现频率的倒数的对数乘积。
TF:即词语出现的频率。
IDF:记每个词出现的文件数为 file_i,总文件数为file_num,IDF[I] = log(file_num/(1+file_i))
TF-IDF = TF * IDF
1 import jieba.analyse 2 # 在线制作词云 https://wordart.com/create 3 path = './test_text.txt' 4 file_in = open(path, 'r',encoding='utf-8') 5 content = file_in.read() 6 7 # 停止词在网上找 https://blog.csdn.net/dorisi_h_n_q/article/details/82114913 8 try: 9 jieba.analyse.set_stop_words('./stop_words.txt') 10 tags = jieba.analyse.extract_tags(content, topK=100, withWeight=True) 11 for v, n in tags: 12 #权重是小数,为了凑整,乘了一万 13 # 中间使用 制表符\t 是为了在线录入数据时候 选择csv格式自动添加词 14 out_words=v + '\t' + str(int(n * 10000)) 15 print(out_words) 16 with open('./out_词频.txt','a+',encoding='utf-8')as f: 17 f.write(out_words+'\n') 18 finally: 19 file_in.close()
打开词云制作网站,import导入数据,粘贴好数据后,选择shapes、Font等。
操作步骤:
1.导入数据
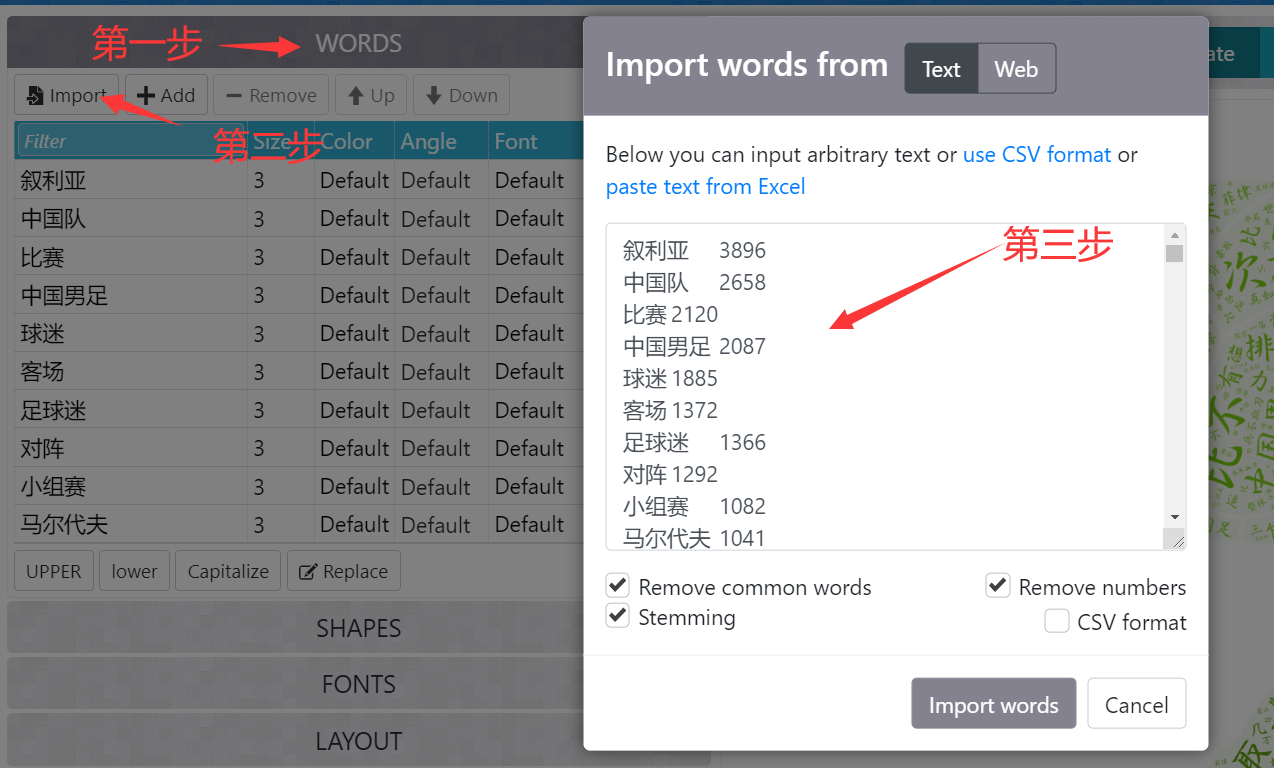
2.选择SHAPES中的某个图像
3.设置字体。字体可以加载本地字体,也可以导“搜字网”下载。
可视化之后,效果图如下所示:

jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
sentence:待分析的文本;
topK: 返回前topK个值;
withWeight: 是否返回权值,默认不返回;
allowPOS: 筛选过滤掉指定词性的词。可选:'ns', 'n', 'vn', 'v','nr'。
清澈的爱,只为中国
