
开始分布式爬虫------(五)
写一个执行项目的py文件,main:
1 from scrapy import cmdline 2 cmdline.execute('scrapy crawl sina_spider'.split())
将项目复制一份到Ubantu虚拟机里,Windows和Linux里同时执行项目,你会发现代码执行之后阻塞了,这是因为我们还没有 lpush
start_urls。下面用Linux里面的操作截图说明:
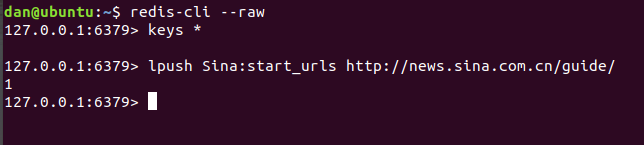
输入上面的代码之后你可以看见Linux和Windows里都开始爬取数据了。
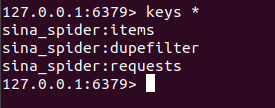
如果你执行项目时直接报错了,很大的可能是redis连接不上,那么你要将redis.confg里的bind配置为0.0.0.0
清澈的爱,只为中国
